

Cloudera’s SQL Stream Builder (SSB) is a versatile platform for data analytics using SQL. As apart of Cloudera Streaming Analytics it enables users to easily write, run, and manage real-time SQL queries on streams with a smooth user experience, while it attempts to expose the full power of Apache Flink. SQL has been around for a long time, and it is a very well understood language for querying data. The SQL standard has had time to mature, and thus it provides a complete set of tools for querying and analyzing data. Nevertheless, as good as it is sometimes it is necessary, or at least desirable, to be able to extend the SQL language for our own needs. UDFs provide that extensibility.
What is a UDF and why do we need it?
SQL is a very useful language for querying data, but it has its limitations. With UDFs you can really enhance the capabilities of your queries. In SSB, today we are supporting JavaScript (JS) and Java UDFs, which can be used as a function with your data. Below we will show an example on how to create and use a JS UDF.
In the following example we use ADSB airplane data. ADSB is data about aircraft. The data is generated and broadcast by planes while flying. Anyone with a simple ADSB radio receiver can acquire the data. The data is very useful, and luckily easy to understand. The data consists of a plane ID, altitude, latitude and longitude, speed, etc.
For our UDF we would like to use the longitude value in order to find out what time zone the plane is in, and output a time zone value as an offset from the GMT time zone (i.e. GMT -3).
The ADSB raw data queried using SSB looks similar to the following:
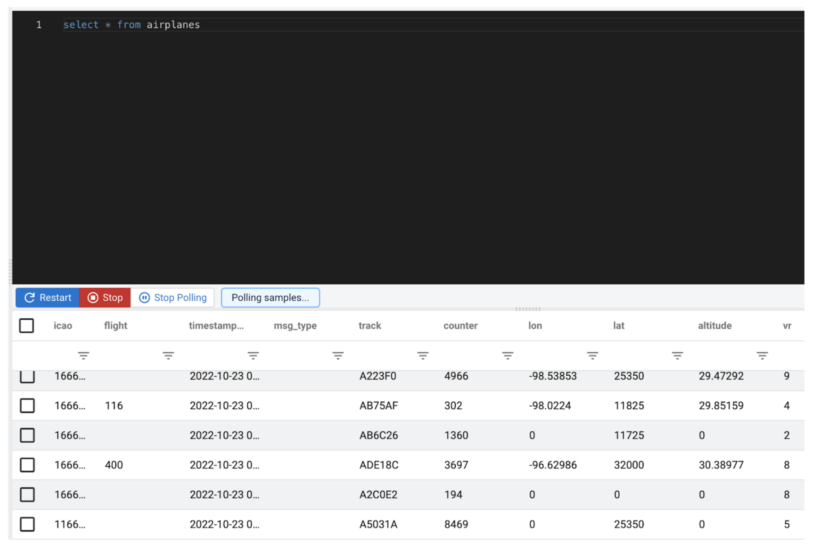
For the purposes of this example we will omit the explanation of how to set up a data provider and how to create a table we can query. But let’s assume we have already set up such a table, based off of a Kafka topic that has the ADSB data streaming through it, and we have named it airplanes. Please check our documentation to see how that’s done.
The raw data above could be acquired by simply issuing the following SQL statement:
SELECT * FROM airplanes;
As we stated earlier we would like to deal with the longitude values and use them to be able to generate a time zone in the usual GMT +-<offset> format. We are also not interested in rows that don’t contain a longitude so we can exclude those. We can also exclude most columns other than the icao, lon and the value we will generate. To achieve our goal, the SQL we require might look something like this:
SELECT icao, lon, TOTZ(lon) as `timezone` FROM airplanes WHERE lon <> ‘’;
The UDF (TOTZ)
TOTZ does not yet exist. TOTZ is the custom UDF that we would need to craft in order to convert a longitude to a time zone, and output the appropriate string.
Planning the UDF
A decimal longitude value can be converted to a time in seconds from the GMT by dividing the longitude by 0.004167:
Longitude / 0.004167 = seconds from GMT
Once we have the number of seconds from GMT we can calculate the hours from GMT by dividing the seconds from GMT by 3600 (3600 is the number of seconds in one hour):
Seconds from GMT / 3600 = hours from GMT
Finally we are only interested in the total number of hours from GMT, not in its remainder (minutes and seconds), so we can eliminate the decimal portion from the hours from GMT value. For example for Kahului, Maui, Hawaii, the longitude is -156.474, then:
-156.474 / 0.004167 = -37550.756s
To hours:
-37550.756 / 3600 = -10.43h
Thus our function should output “GMT -10”. Currently UDFs can be crafted using the JavaScript programming language in SSB (and Java UDFs can be uploaded, but in our post we are using JS). By right clicking on “Functions” and then the “New Function” button, a user can create a new UDF. A popup opens up and the UDF can be created. The UDF requires a “Name” one or more “Input Type”, an “Output Type” and the function body itself. The JS code has just one requirement, and that is that the last line must return the output value. The code receives the input value as the variable named “$p0”. In our case $p0 is the longitude value.
In case we want to pass multiple parameters to our function that can be done as well, we only need to make sure to adapt the last line accordingly and add the proper input types. For example if we have function myFunction(a, b, c) { … }, the last line should be myFunction($p0, $p1, $p2), and we should match the number and kind of the “Input Types” as well.
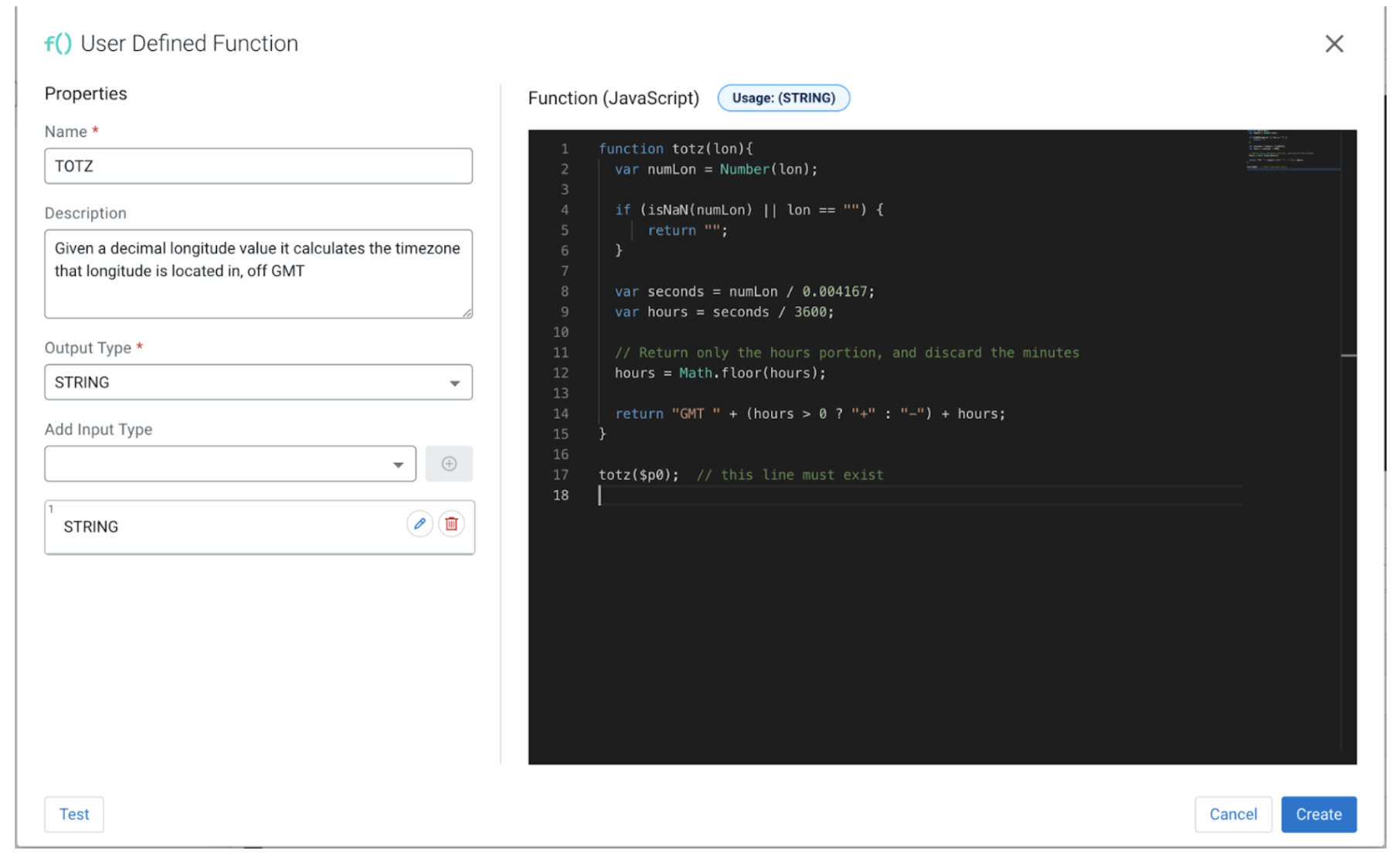
UDF code
function totz(lon){ var numLon = Number(lon); if (isNaN(numLon) || lon == "") { return ""; } var seconds = numLon / 0.004167; var hours = seconds / 3600; // Return only the hours portion, and discard the minutes hours = Math.floor(hours); return "GMT " + (hours > 0 ? "+" : "-") + hours; } totz($p0); // this line must exist
Testing the UDF
After creating our UDF we can try our SQL and see what it produces.
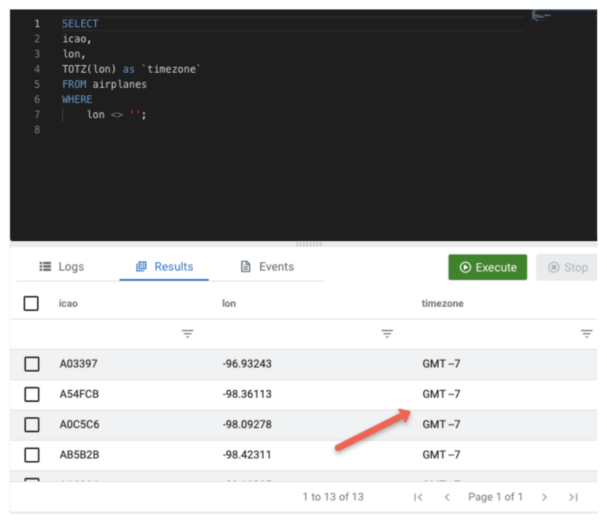
Our TOTZ UDF did the job! We were able to quickly and easily extend the SQL language, and use the new UDF as if it was a native SQL function, and based off of the longitude value it was able to produce a string representing the time zone that the plane is flying through at the time.
Conclusion
In summary, Cloudera Stream Processing gives us the ability to build UDF’s and deploy continuous jobs directly from the SQL Stream Builder interface so that you can build streaming analytics pipelines that execute advanced/custom business logic. The creation and use of UDFs is simple, and the logic can be written using the usually familiar JavaScript programming language.
Try it out yourself!
Anybody can try out SSB using the Stream Processing Community Edition (CSP-CE). CE makes developing stream processors easy, as it can be done right from your desktop or any other development node. Analysts, data scientists, and developers can now evaluate new features, develop SQL-based stream processors locally using SQL Stream Builder powered by Flink, and develop Kafka Consumers/Producers and Kafka Connect Connectors, all locally before moving to production in CDP.
Editor's Choice

