

Apache YuniKorn (Incubating) has just released 0.10.0 (release announcement). As part of this release, a new feature called Gang Scheduling has become available. By leveraging the Gang Scheduling feature, Spark jobs scheduling on Kubernetes becomes more efficient.
What is Apache YuniKorn (Incubating)?
Apache YuniKorn (Incubating) is a new Apache incubator project that offers rich scheduling capabilities on Kubernetes. It fills the scheduling gap while running Big Data workloads on Kubernetes, with a ton of useful features such as hierarchical queues, elastic queue quotas, resource fairness, and job ordering. To learn more about what is YuniKorn, please read our previous article: YuniKorn – a universal resources scheduler and Spark on Kubernetes – how YuniKorn helps.
What is Gang Scheduling?
According to wikipedia, Gang Scheduling refers to a scheduling algorithm for parallel systems that schedules related threads or processes to run simultaneously on different processors. In the distributed computing world, this refers to the mechanism to schedule correlated tasks in an All or Nothing manner. In another word, this means the resource scheduler instead of scheduling task by task, it looks at overall how many slots needed for an application and assigns resources to satisfy the demands altogether, or postpone the scheduling until it reaches this state.
Why is Gang Scheduling needed?
Gang scheduling is very useful for multi-task applications which require launching tasks simultaneously. This is a common requirement for machine learning workloads, such as TensorFlow. The second use case is that the Gang Scheduling avoids the resource segmentation problem for batch jobs, this is extremely useful for computing engines like Spark.
With Gang Scheduling, YuniKorn “understands” how many applications can be launched in a queue without exceeding the resource quota, therefore the maximum number of jobs can be launched concurrently in the queue.
Gang Scheduling in YuniKorn
YuniKorn introduces TaskGroups type to define the gangs for the application. This is a generic way to define gang scheduling requirements and can be utilized by any application. The TaskGroups type is self-explanatory, each taskGroup represents a “gang” for the application, which is a group of homogenous pod requests. See here to find out how to define the TaskGroups. Please refer to this doc to learn how to define TaskGroups.
When an app with TaskGroups is submitted, it will be gang scheduled. Instead of directly assigning resources for an app’s pod, the scheduling procedure will be different. It mainly has 4 phases:
Prepare: in this phase, YuniKorn proactively creates a certain number of placeholder pods based on the taskGroups definition. For each task group, a minMember number of placeholder pods will be created, using the resources, constraints defined in this group.
Resource Reservation: in this phase, YuniKorn allocates resources to the placeholder pods, and waits for all of them to be allocated. A placeholder pod is just running a lightweight “pause” command to reserve a spot on a node.
Swap: once all placeholders are allocated, YuniKorn starts to allocate resources to the real app’s pods by “swapping” the placeholder pods. The placeholder pods’ resources must be exactly the same as the real pod in the same group, so the swap can happen with trivial effort. YuniKorn tries best to place the real pod to the reserved spot, if not then fallback to other qualified nodes.
Finalize: in this phase, YuniKorn finishes assigning resources for the app and starts to operate on the necessary cleanup tasks. If any of the placeholder pods are no longer needed by any taskGroup, e.g over-reserved, they will be garbage collected.
Schedule Spark jobs with Gang Scheduling
Without gang scheduling, the Spark job scheduling in YuniKorn is based on the StateAware policy, this policy puts a small scheduling delay between jobs to avoid race conditions. However, it brings some inefficiency when the cluster heavily depends on auto scaling. Gang Scheduling solves these problems and schedules jobs more efficiently. Here is an example in case Gang Scheduling is enabled for Spark jobs.
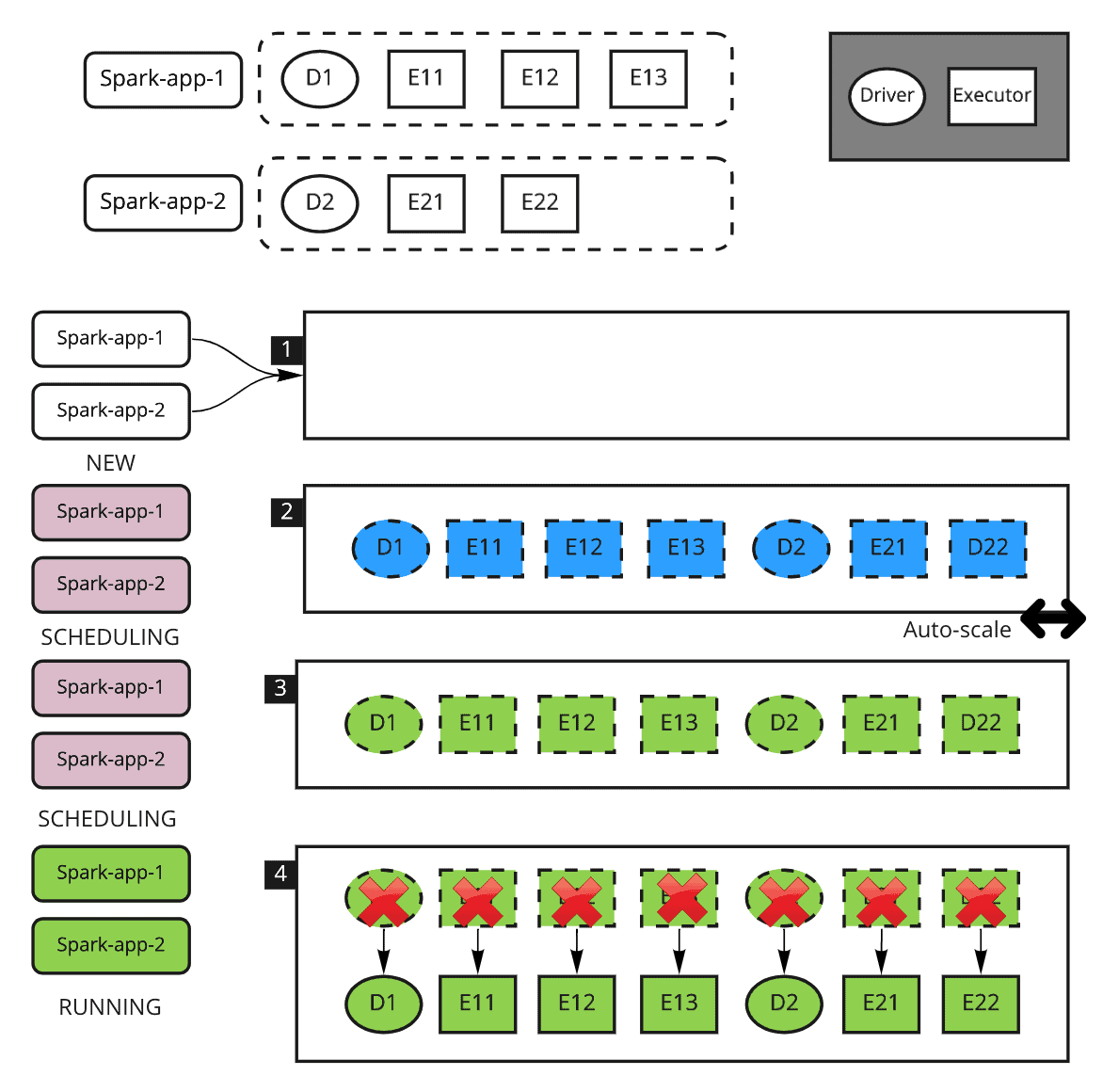
Explanation:
- 2 Spark jobs are submitted to a resource queue simultaneously
- Once the 2 Spark driver pods are allocated on Kubernetes, YuniKorn retrieves the gang scheduling metadata from the TaskGroups definition, and then it starts to reserve required resources for each job by proactively creating the placeholder pods. In this step, the placeholder pods will trigger the upscaling if the cluster has auto-scaler enabled. The upscaling kicks in much earlier than before because it no longer needs to wait for the driver to create the executors.
- Once the cluster scales up, the placeholders are allocated
- Once all the placeholders are allocated, YuniKorn starts to swap the placeholder pods with the real pods in the taskGroup until all the real pods are allocated. Then the 2 jobs are running.
Advantages
Avoid Resource Segmentations Problem
Resource segmentation problems are very common when the cluster doesn’t have sufficient resources for all coming jobs. In the following chart, green boxes represent the job’s allocated pods, red boxes represent the pods that are pending allocation. When running jobs simultaneously on the cluster that has no sufficient resources, jobs could be competing resources with each other badly like:
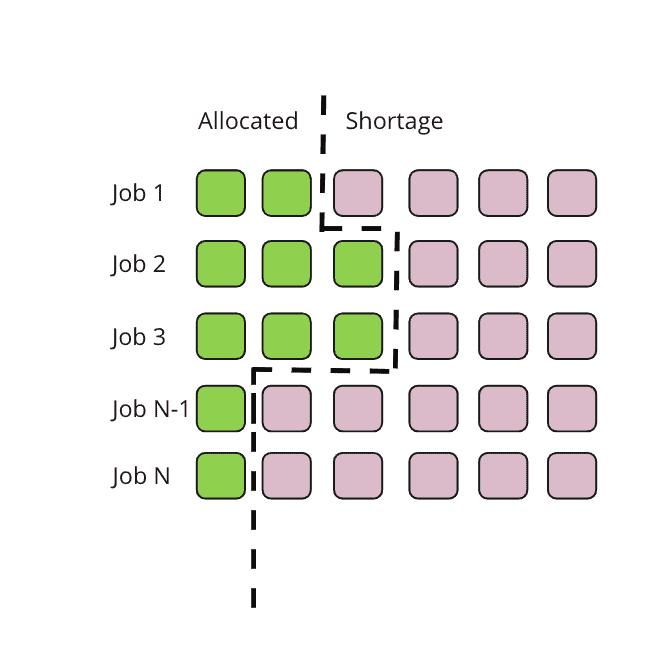
Jobs from 1 to N, all have partially required resources allocated but not all. This is highly inefficient. Worst-case scenario, each job could only get 1 pod allocated. If this happens to Spark, with only the driver pod started, all the jobs will be stuck as there are no resources left for the executors.
With Gang Scheduling, the scheduler guarantees that each job could get the minimal resources for itself to start. The same scenario will look like this:
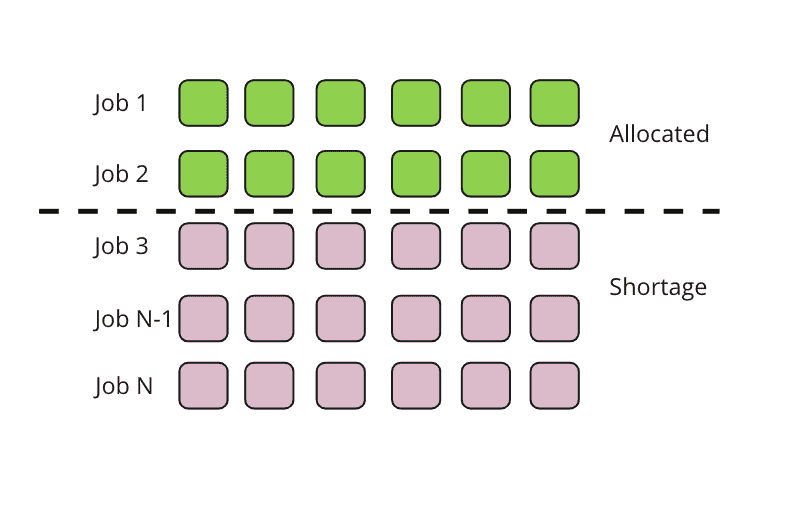
In this case, the resources are allocated to only Job 1 and Job 2, because these 2 jobs are using all the available queue resources. The remaining jobs will be pending until job 1 or 2 releases resources. This way, the job execution time is more predictable and there is no resource segmentation nor deadlock issue anymore.
Improved Performance for Running Spark on Cloud
One of the most beneficial things the Cloud gives us is elasticity, a cluster can grow or shrink on demand with the presence of the cluster-autoscaler. Without Gang Scheduling, the Spark scheduling on Kubernetes looks like the following:
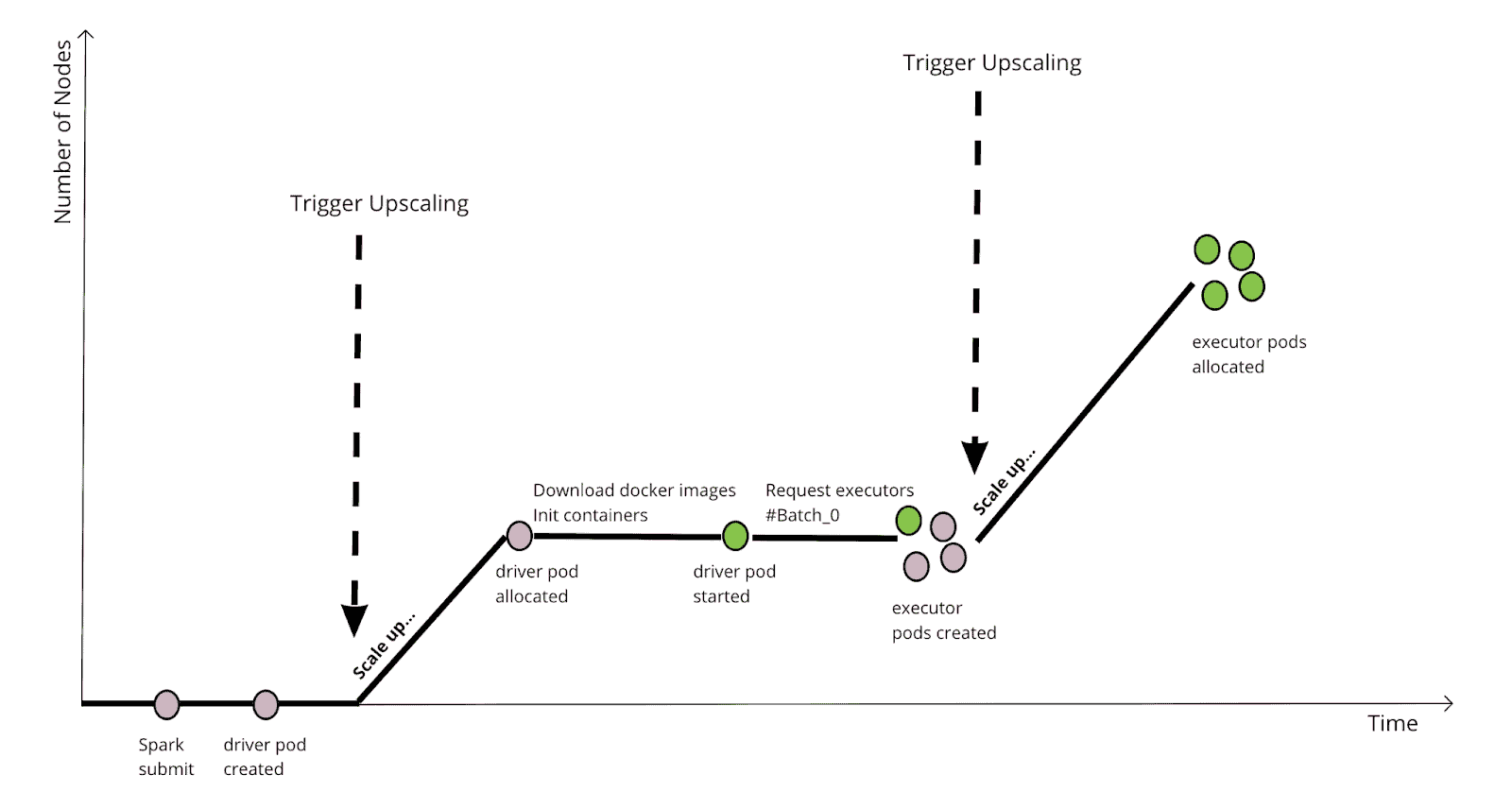
This chart illustrates the scenario that submits a Spark job to a “cold” cluster, where there are 0 compute nodes available. It needs several steps in order to scale up the cluster to the desired size. There is a significant delay between the 2 triggers because of the time spent for downloading docker images, Spark driver’s initialization, downloading dependencies, requesting for executors, etc. When the driver applies executors in batches, this is even worse.
With Gang Scheduling, the workflow changes to the following:
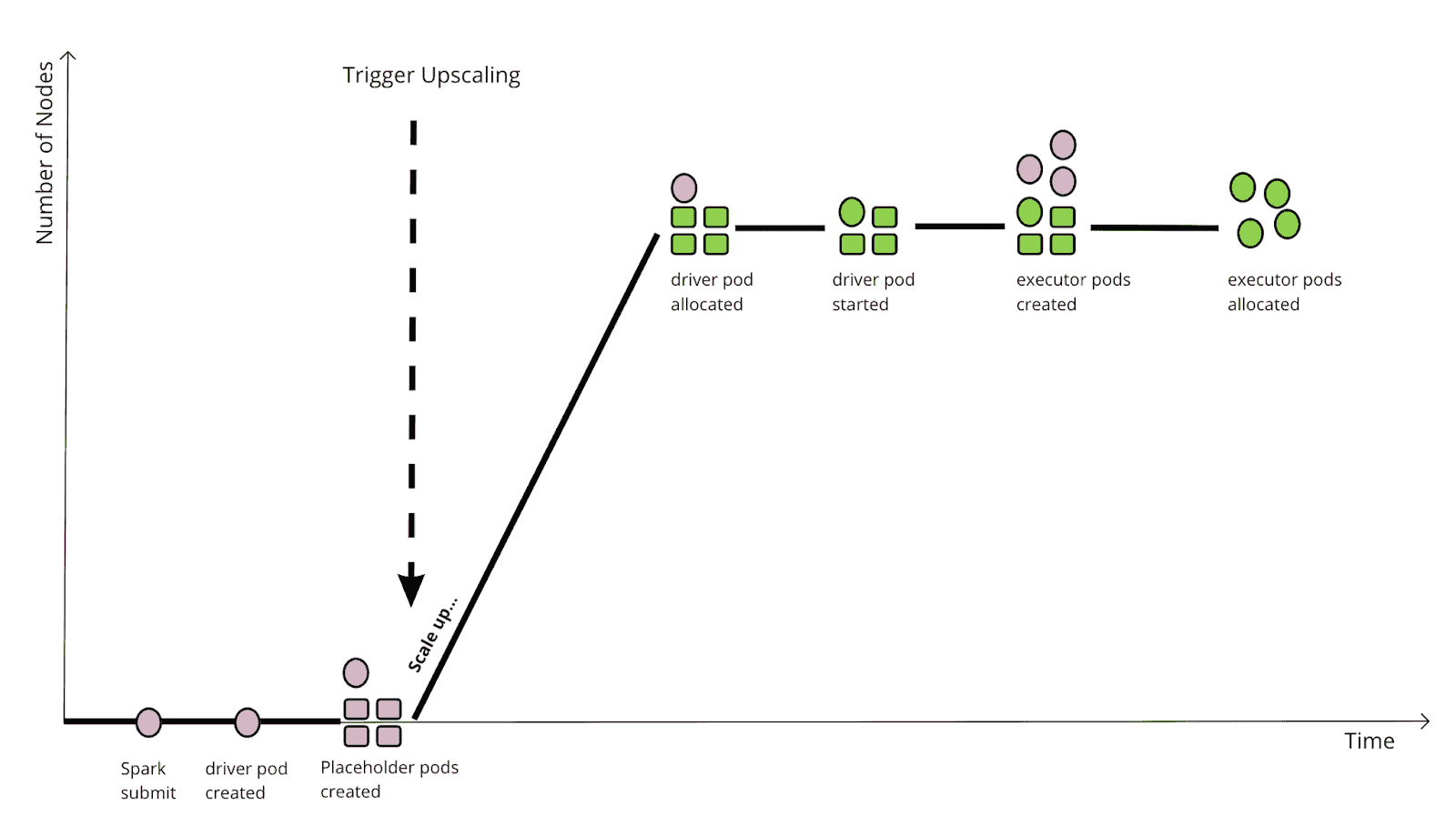
Instead of waiting for Spark to create the driver/executor pods to trigger the upscaling, YuniKorn creates placeholder pods beforehand and that triggers the upscaling in one big step, and directly scales the cluster to the desired size. And the rest of the steps do not need to wait for cluster upscaling anymore. This is more efficient when each Spark job has different batches, as well as when there are batch jobs submitted to the cluster.
Next step
The YuniKorn community will work on further integration with Spark K8s operator, in order to bring end-to-end experience to run Spark on Kubernetes with Gang Scheduling. The issue is tracked in YUNIKORN-643.
More Resources
The Gang Scheduling feature is available now in Apache YuniKorn (Incubating) 0.10 release, you can find out what has been included in this release from the release announcements. To learn how to use Gang Scheduling, please read the Gang Scheduling user guide. If you want to understand more about the design details, you can find the design doc here. You can also find more information from our previous blog series.
Editor's Choice

