



Hello world, it’s been a while!
We are super excited today to announce the open-sourcing of one of the exciting new projects we’ve been working behind the scenes at the intersection of big-data and computation platforms – YuniKorn!
Yunikorn is a new standalone universal resource-scheduler responsible for allocating/managing resources for big-data workloads including batch jobs and long-running services.
Let’s dive right in!
Introduction
YuniKorn is a light-weight, universal resource scheduler for container orchestrator systems. It is created to achieve fine-grained resource sharing for various workloads efficiently on large scale, multi-tenant environments on one hand and dynamically brought up cloud-native environment on the other. YuniKorn brings a unified, cross-platform scheduling experience for mixed workloads consists of stateless batch workloads and stateful services, with support for, but not limited to, YARN and Kubernetes.
YuniKorn [‘ju:nikɔ:n] is a made-up word, “Y” for YARN, “K” for K8s, “Uni” for Unified, and its pronunciation is the same as “Unicorn”. It is created to initially support these two systems, but the ultimate purpose is to create a unified scheduler that can support any container orchestrator systems.
There are presently 4 components in YuniKorn:
We will go deeper into each of these a little later below.
Background
Enterprise users run workloads on different platforms such as YARN and Kubernetes. They need to work with different resource schedulers in order to plan their workloads to run on these platforms efficiently.
Currently, the scheduler ecosystem is fragmented, and the implementations are suboptimal with respect to balancing existing use-cases like batch workloads along with new needs such as cloud-native architecture, autoscaling etc. For example:
- YARN has Capacity Scheduler and Fair Scheduler for batch workloads.
- K8s has default scheduler for services. For batch workloads, the community has Kube-batch, Poseidon, Rubix (Scheduler extension for Spark).
We investigated these projects and realized there’s no silver bullet so far to have a single scheduler to support both stateless batch jobs (which needs fairness, high scheduling throughput, etc.) and long-running services (which need persistent volumes, complex placement constraints, etc.). This motivated us to create a unified scheduling framework to address all these important needs and benefit both big data as well as cloud-native communities.
Architecture
When designing YuniKorn, one objective is to decouple the scheduler from the underneath resource management system, and in order to do so, we have created a common scheduler interface which defines communication protocols. By leveraging that, scheduler-core and shim work together to handle scheduling requests. Some more explanation about YuniKorn components follows.
YuniKorn Architecture
Major modules in YuniKorn are:
- Scheduler Interface: Scheduler interface is an abstract layer which resource management platform (like YARN/K8s) will speak with, via API like GRPC/programing language bindings.
- YuniKorn Core: YuniKorn core encapsulates all scheduling algorithms, it collects resources from underneath resource management platform (like YARN/K8s), and responsible for resource allocation requests. It makes decisions about the best placement for each request and then sends response allocations to the resource management platform. Scheduler core is agnostic to the underneath platforms, all the communications are through the scheduler interface.
- Scheduler Shim Layers: Scheduler shim runs inside of host system (like YARN/K8s), it is responsible for translating host system resources, and resource requests via scheduler interface and send them to scheduler core. And when a scheduler decision is made, it is responsible for the actual pod/container bindings.
- Scheduler UI: Scheduler UI provides a simple view for managed nodes, resources, applications and queues.
Features
The following is a list of scheduling features currently supported in YuniKorn:
- Scheduling features supporting both batch jobs and long-running/stateful services
- Hierarchical pools / queues with min/max resource quotas
- Resource fairness between queues, users and apps
- Cross-queue preemption based on fairness
- Customized resource types (like GPU) scheduling support
- Rich placement constraints support
- Automatically map incoming container requests to queues by policies
- Node partitioning clusters to sub-clusters with dedicated quota/ACL management
Specific features supported when running YuniKorn on K8s as a scheduler:
- Support K8s predicates. Such as pod affinity/anti-affinity, node selectors
- Support Persistent Volumes, Persistent Volume Claims, etc
- Load scheduler configuration from configmap dynamically (hot-refresh)
- Deployable on top of Kubernetes
The YuniKorn Web supports monitoring scheduler queues, resource usage, applications etc.
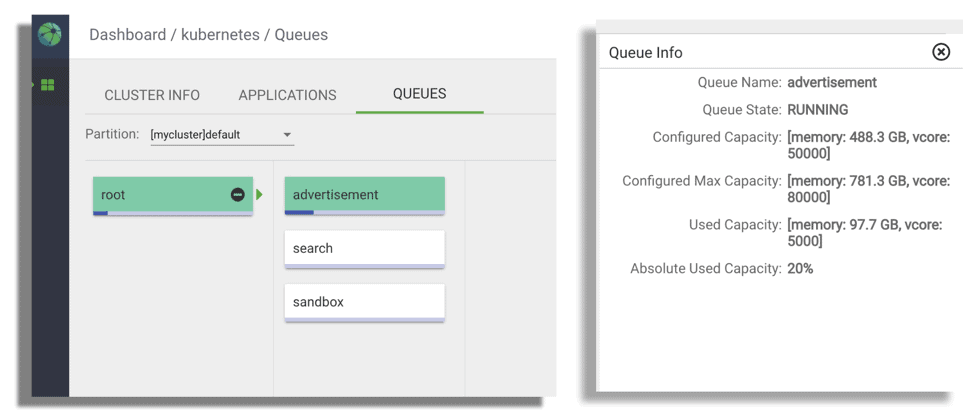
Web UI for monitoring of YuniKorn’s queue resource usage.
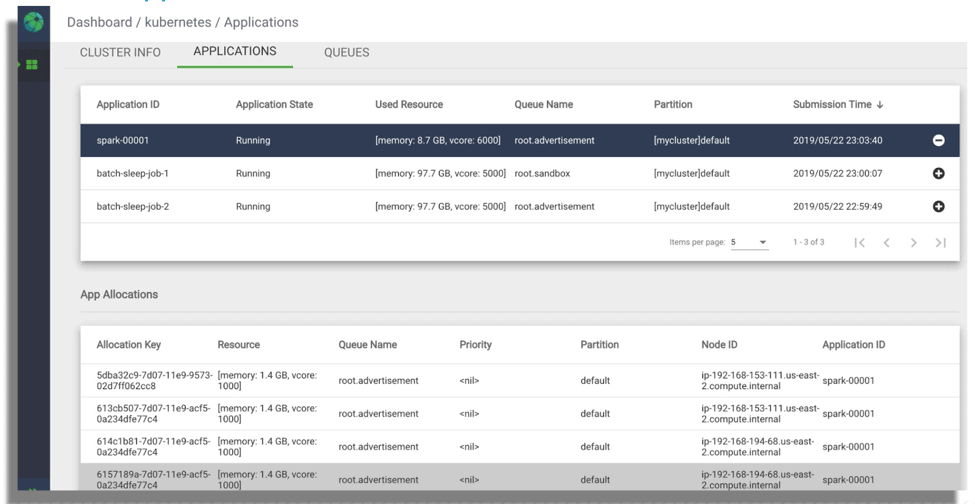
Web UI for monitoring of YuniKorn’s application management & resource usage.
What’s Next
There are many challenges to running mixed workloads on a single system, YuniKorn is our bet to make this path easier. Our goal is to start with supporting various big data workloads landing on an existing K8s cluster. We are working on supporting workloads such as Spark, Flink, and Tensorflow on K8s better.
You can find the project roadmap here. Our ultimate goal is to bring the best-of-breed scheduling experiences to both big data and cloud-native worlds together.
Excited about YuniKorn? Please follow the links to Get Started and Contribute to this project!
About the authors
Weiwei Yang, Staff Software Engineer at Cloudera, Apache Hadoop committer and PMC Member, focusing on resource scheduling on distributed systems.
Wangda Tan, Senior Engineering Manager of computation platform (K8s/YARN) teams. Apache Hadoop PMC Member and committer. Apache Hadoop since 2011. Resource management, scheduling systems, deep learning on computation platforms.
Sunil Govindan, Engineering Manager at Cloudera Bengaluru. Apache Hadoop project since 2013, contributor, Committer & PMC Member. Hadoop YARN Scheduling.
Wilfred Spiegelenburg, Staff Software Engineer @ Cloudera Australia. 6 years of Apache Hadoop mainly on YARN, MapReduce and Spark.
Vinod Kumar Vavilapalli, Director of Engineering at Hortonworks/Cloudera. Apache Hadoop PMC Chair. ASF Member. Apache Hadoop since 2007. Hadoop YARN from day one. Big data, scheduling, containers, scale, open source.
Editor's Choice


Can you please make a article how to integrate Yunikorn with Hadoop components?? Can we use it in HDP??
Hi Asish
YuniKorn currently only provides a K8shim, which means it can only work with K8s.
It won’t be able to work with the Hadoop YARN cluster at this point of time.
If I run the flink application on k8s with this and the requirement of containner memory increases day by day because of increament of data cache. Can this make it that memory automatically expands ?