

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This post is authored by Omkar Vinit Joshi with Vinod Kumar Vavilapalli and is the ninth post in the multi-part blog series on Apache Hadoop YARN – a general-purpose, distributed, application management framework that supersedes the classic Apache Hadoop MapReduce framework for processing data in Hadoop clusters. Other posts in this series:
- Introducing Apache Hadoop YARN
- Apache Hadoop YARN – Background and an Overview
- Apache Hadoop YARN – Concepts and Applications
- Apache Hadoop YARN – ResourceManager
- Apache Hadoop YARN – NodeManager
- Running existing applications on Hadoop 2 YARN
- Stabilizing YARN APIs for Apache Hadoop 2
- Management of Application Dependencies
- Resource Localization in YARN: Deep Dive
Introduction
In the previous post, we explained the basic concepts of LocalResources and resource localization in YARN. In this post, we’ll dig deeper into the innards explaining how the localization happens inside NodeManager.
Recap of definitions
A brief recap of some definitions follows.
- Localization: Localization is the process of copying/download remote resources onto the local file-system. Instead of always accessing a resource remotely, it is copied to the local machine which can then be accessed locally.
- LocalResource: LocalResource represents a file/library required to run a container. The NodeManager is responsible for localizing the resource prior to launching the container. For each LocalResource, Applications can specify
- URL: Remote location from where a LocalResource has to be downloaded
- Size: Size in bytes of the LocalResource
- Creation timestamp of the resource on the remote file-system
- LocalResourceType: Specifies the type of a resource localized by the NodeManager – FILE, ARCHIVE and PATTERN
- Pattern: the pattern that should be used to extract entries from the archive (only used when type is PATTERN).
- LocalResourceVisibility: Specifies the visibility of a resource localized by the NodeManager. The visibility can be one of PUBLIC, PRIVATE and APPLICATION
- ResourceLocalizationService: The service inside NodeManager that is responsible for localization.
- DeletionService: A service that runs inside the NodeManager and deletes local paths as and when instructed to do so.
- Localizer: The actual thread or process that does Localization. There are two types of Localizers – PublicLocalizer for PUBLIC resources and ContainerLocalizers for PRIVATE and APPLICATION resources.
- LocalCache: NodeManager maintains and manages serveral local-cache of all the files downloaded. The resources are uniquely identified based on the remote-url originally used while copying that file.
How localization works
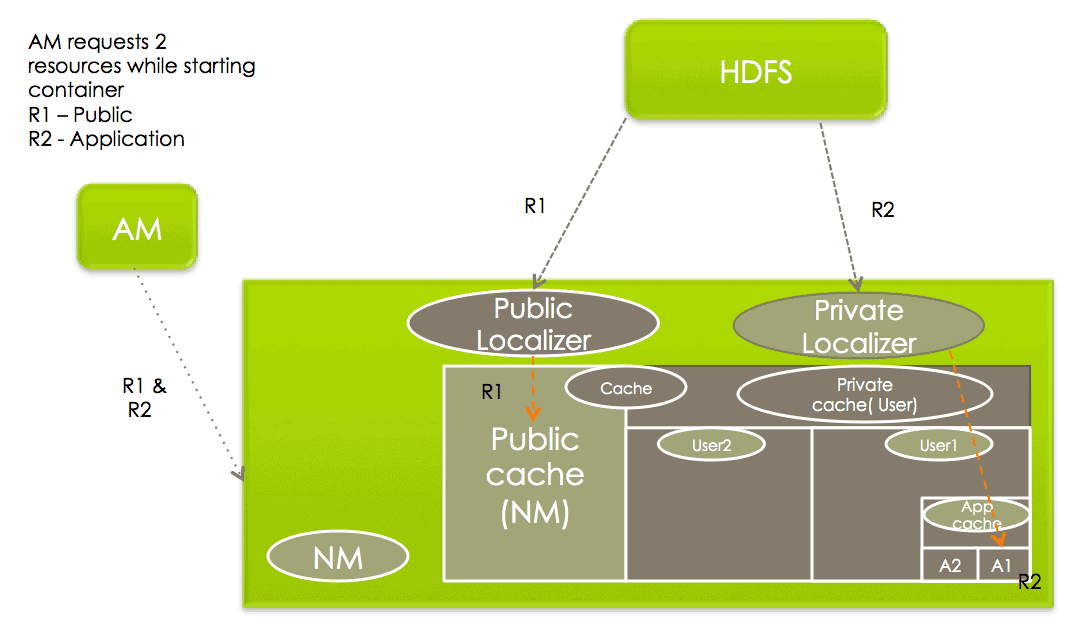
As you recall from the previous post, there are three types of LocalResources – PUBLIC, PRIVATE and APPLICATION specific resources. PUBLIC LocalResources are localized separately by the NodeManager from PRIVATE/APPLICATION LocalResources because of security implications.
Localization of PUBLIC resources
Localization of PUBLIC resources is taken care of by a pool of threads called PublicLocalizers.
- PublicLocalizers run inside the address-space of the NodeManager itself.
- The number of PublicLocalizer threads is controlled by the configuration property yarn.nodemanager.localizer.fetch.thread-count – maximum parallelism during downloading of PUBLIC resources is equal to this thread count.
- While localizing PUBLIC resources, the localizer validates that all the requested resources are indeed PUBLIC by checking their permissions on the remote file-system. Any LocalResource that doesn’t fit that condition is rejected for localization.
- Each PublicLocalizer uses credentials passed as part of ContainerLaunchContext to securely copy the resources from the remote file-system.
Localization of PRIVATE/APPLICATON resources
Localization of PRIVATE/APPLICATION resources is not done inside the NodeManager and hence is not centralized. The process is a little involved and is outlined below:
- Localization of these resources happen in a separate process called ContainerLocalizer.
- Every ContainerLocalizer process is managed by a single thread in NodeManager called LocalizerRunner. Every container will trigger one LocalizerRunner if it has any resources that are not yet downloaded.
- LocalResourcesTracker is a per-user or per-application object that tracks all the LocalResources for a given user or an application.
- When a container first requests a PRIVATE/APPLICATION LocalResource, if it is not found in LocalResourcesTracker (or found but in INITIALIZED state) then it is added to pending-resources list.
- A LocalizerRunner may( or may not) get created depending on the need for downloading something new.
- The LocalResources is added to its LocalizerRunner’s pending-resources list.
- One requirement for NodeManager in secure mode is to download/copy these resources as the application-submitter and not as a yarn-user (privileged user). Therefore LocalizerRunner starts a LinuxContainerExecutor(LCE) (a process running as application-submitter) which then execs a ContainerLocalizer to download these resources.
- Once started, ContainerLocalizer starts heartbeating with the NodeManager process.
- On each heartbeat, LocalizerRunner either assigns one resource at a time to a ContainerLocalizer or asks it to die. ContainerLocalizer informs LocalizerRunner about the status of the download.
- If it fails to download a resource, then that particular resource is removed from LocalResourcesTracker and the container eventually is marked as failed. When this happens LocalizerRunners stops the running ContainerLocalizers and exits.
- If it is a successful download, then LocalizerRunner gives a ContainerLocalizer another resource again and again until all pending resources are successfully downloaded.
- At present, each ContainerLocalizer doesn’t support parallel download of mutliple PRIVATE/APPLICATION resources which we are trying to fix via YARN-574.
Note that because of the above, the maximum parallelism that we can get at present is the number of containers requested for same user on same node manager at THAT point of time. This in the worst case is one when an ApplicationMaster itself is starting. So if AM needs any resources to be localized then today they will be downloaded serially before its container starts.
Target locations of LocalResources
On each of the NodeManager machines, LocalResources are ultimately localized in the following target directories, under each local-directory:
- PUBLIC:
<local-dir>/filecache - PRIVATE:
<local-dir>/usercache//filecache - APPLICATION:
<local-dir>/usercache//appcache/<app-id>/
Configuration for resources’ localization
Administrators can control various things related to resource-localization by setting or changing certain configuration parameters in yarn-site.xml when starting a NodeManager.
- yarn.nodemanager.local-dirs: This is a comma separated list of local-directories that one can configure to be used for copying files during localization. The idea behind allowing multiple directories is to use multiple disks for localization – it helps both fail-over (one/few disk(s) going bad doesn’t affect all containers) and load balancing (no single disk is bottlenecked with writes). Thus, individual directories should be configured if possible on different local disks.
- yarn.nodemanager.local-cache.max-files-per-directory: Limits the maximum number of files which will be localized in each of the localization directories (separately for PUBLIC / PRIVATE / APPLICATION resources). Its default value is 8192 and should not typically be assigned a large value (configure a value which is sufficiently less than the per directory maximum file limit of the underlying file-system e.g ext3).
- yarn.nodemanager.localizer.address: The network address where ResourceLocalizationService listens to for various localizers.
- yarn.nodemanager.localizer.client.thread-count: Limits the number of RPC threads in ResourceLocalizationService that are used for handling localization requests from Localizers. Defaults to 5, which means that by default at any point of time, only 5 Localizers will be processed while others wait in the RPC queues.
- yarn.nodemanager.localizer.fetch.thread-count: Configures the number of threads used for localizing PUBLIC resources. Recall that localization of PUBLIC resources happens inside the NodeManager address space and thus this property limits how many threads will be spawned inside NodeManager for localization of PUBLIC resources. Defaults to 4.
- yarn.nodemanager.delete.thread-count: Controls the number of threads used by DeletionService for deleting files. This DeletionUser is used all over the NodeManager for deleting log files as well as local cache files. Defaults to 4.
- yarn.nodemanager.localizer.cache.target-size-mb: This decides the maximum disk space to be used for localizing resources. (At present there is no individual limit for PRIVATE / APPLICATION / PUBLIC cache. YARN-882). Once the total disk size of the cache exceeds this then Deletion service will try to remove files which are not used by any running containers. At present there is no limit (quota) for user cache / public cache / private cache. This limit is applicable to all the disks as a total and is not based on per disk basis.
- yarn.nodemanager.localizer.cache.cleanup.interval-ms: After this interval resource localization service will try to delete the unused resources if total cache size exceeds the configured max-size. Unused resources are those resources which are not referenced by any running container. Every time container requests a resource, container is added into the resources’ reference list. It will remain there until container finishes avoiding accidental deletion of this resource. As a part of container resource cleanup (when container finishes) container will be removed from resources’ reference list. That is why when reference count drops to zero it is an ideal candidate for deletion. The resources will be deleted on LRU basis until current cache size drops below target size.
Conclusion
That concludes our exposition of resource-localization in NodeManager. It is one of the chief services offered by NodeManagers to the applications. Next time, we’ll continue with more gritty details of YARN, stay tuned.
To get started with YARN, take a look at these resources.
Editor's Choice


Hi,
I am Amit Chavan currently working at sattrix software solution pvt. ltd. We have used apache hadoop open source 2.7.1. In this version from last 5 months we have faced “Container is not running, current state is localizing” this issue is occurring. We have done every possible solution for this like configuration changes,we have increased spark core and memory even we have deleted the production data. Yet the error was not gone.
So m requesting you to please give me the possible solution for this issue