

Recently, I worked with a large fortune 500 customer on their migration from Apache Storm to Apache NiFi. If you’re asking yourself, “Isn’t Storm for complex event processing and NiFi for simple event processing?”, you’re correct. A few customers chose a complex event engine like Apache Storm for their simple event processing, even when Apache NiFi is the more practical choice, cutting drastically down on SDLC (software development lifecycle) time. Fast-forwarding today, Storm has been deprecated in the Cloudera Data Platform in favor of Apache Flink. Therefore, customers must migrate from Storm to another solution simpler, no-coding and get the same requirement done faster, and in this case, their use cases were a fantastic fit for NiFi. Since all the flows were simple event processing, the NiFi flows were built out in a matter of hours (drag-and-drop) instead of months (coding in Java).

Nifi Flows
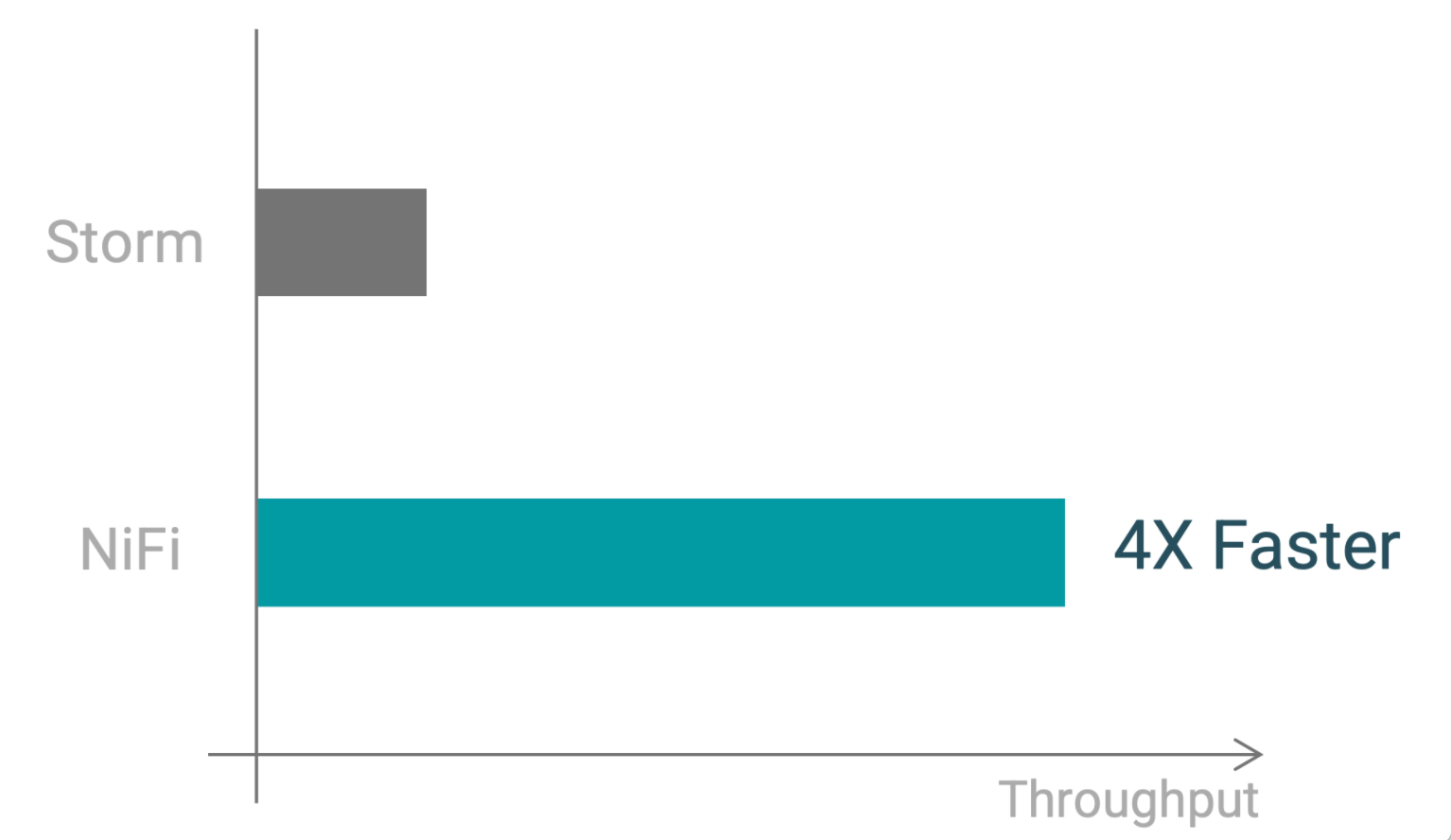
My customer’s biggest concern was performance, which they wanted like-for-like, using the same hardware profile (4 nodes) for Storm and NiFi. They asked, “Can NiFi keep up with the same throughput as Storm?” As you’ll see in this blog, NiFi is not only keeping up with Storm; it beats Storm by 4x throughput.
Setting the context, why would a customer want to use Apache NiFi, Apache Kafka, and Apache HBase? Because, they’ll be able to store massive amounts of data, process this data in real-time or batch, and serve the data to other applications. My customer had reconciliation data that needed to be processed throughout the day. In their case, they had another external application that published events to Kafka. Once the reconciliation data was put into different Kafka topics, NiFi would consume from them, performing simple transformations until writing to HBase. Many applications would use the data in HBase, to create reports given certain event criteria. The reconciliation data needed to be stored in its final state in HBase for a minimum of two years.
Before we can discuss the optimizations, it’s important to understand a customer’s flows. What are the source, target, and transformations in-between for each flow? If your source is Kafka, where Kafka polls messages in batches of 1,000+, Record Oriented processors will excel throughput. If the target can also handle batches such as HBase, you’re even in a better spot. And then the transformations, such as JoltTransformRecord, ConvertRecord, QueyRecord, PartitionRecord, and ScriptedTransformRecord. A common theme in all of these processors is using “Record,” meaning instead of handling a single file in each processor, we’re able to batch together multiple files in a single FlowFile in NiFi. The Record Oriented processors have been around for several years (2017), but some customers have yet to adopt the Records.
Record Oriented processors are far beyond just reading/writing from one format to another. If you can process more work in a single task (aka batching), you’re creating efficiencies within NiFi in things like provenance. If the provenance has fewer FlowFiles to track, you’re saving disk I/O. To provide an example, here is a flow before using Record Oriented processors:
(Source) ConsumeKafka -> (Transform) ConvertAvroToJSON -> EvaluateJsonPath -> RouteOnAttribute -> SplitJSON -> TransformJSON -> MergeContent -> (Target) PutHBase
This flow likely feels familiar if you haven’t used Record Oriented processors (eight processors). This flow is what my customer was gaining slightly over 30 GB in five minutes, matching the throughput of Storm. Once we adopted Record Oriented processors, the flow changed to (five processors):
(Source) ConsumeKafkaRecord -> (Transform) PartitionRecord -> RouteOnAttribute -> TransformRecord -> (Target) PutHBaseRecord
Going from eight processors to five processors may not seem like much of a change, but this simplifies and optimizes the overall number of tasks available within NiFi. Those NiFi tasks/threads can be spent on other processors. By using Record Oriented processors, my customer was able to gain over 160+ GB in five minutes, shattering their throughput concerns. The bulk of the throughput gains were from batching multiple Kafka messages (1,000+) into one FlowFile. A common misconception is that you need to use Schema Registry for the Record Oriented processors. My customer has yet to use Schema Registry, but created an internal Schema Controller Service within NiFi. By using this internal Controller Service, the Record readers and writers could gather their schemas from one centralized location.
I hope you’ve gained new insights into the gigantic performance improvements by using Record Oriented processors. The latest version of NiFi is part of Cloudera Flow Management (CFM) 2.2.1.
Take the next steps to:
Editor's Choice


Hello,
Can you give us some info about Nifi HA / SPoF? It seems that if one Nifi node goes down, we have to wait for it to get back as there is no retry operation on a different node. Was this recently fixed or there is any roadmap for it to be soon fixed?
Thanks.
Hi IA,
Thanks for your question! This feature (hard drives being a single point of failure for data – where RAID redundancy was the fix in the past) has been solved in DataFlow Experience (DFX). DFX uses K8S for HA on your data amongst multiple nodes.
You can try out DFX with CDP Public Cloud today.
Thanks again,
Ryan Cicak