

In this post, I will demonstrate how to use the Cloudera Data Platform (CDP) and its streaming solutions to set up reliable data exchange in modern applications between high-scale microservices, and ensure that the internal state will stay consistent even under the highest load.
Introduction
Many modern application designs are event-driven. An event-driven architecture enables minimal coupling, which makes it an optimal choice for modern, large-scale distributed systems. Microservices, as part of their business logic, sometimes do not only need to persist data into their own local storage, but they also need to fire an event and notify other services about the change of the internal state. Writing to a database and sending messages to a message bus is not atomic, which means that if one of these operations fails, the state of the application can become inconsistent. The Transactional Outbox pattern provides a solution for services to execute these operations in a safe and atomic manner, keeping the application in a consistent state.
In this post I am going to set up a demo environment with a Spring Boot microservice and a streaming cluster using Cloudera Public Cloud.
The Outbox Pattern
The general idea behind this pattern is to have an “outbox” table in the service’s data store. When the service receives a request, it not only persists the new entity, but also a record representing the message that will be published to the event bus. This way the two statements can be part of the same transaction, and since most modern databases guarantee atomicity, the transaction either succeeds or fails completely.
The record in the “outbox” table contains information about the event that happened inside the application, as well as some metadata that is required for further processing or routing. Now there is no strict schema for this record, but we’ll see that it is worth defining a common interface for the events to be able to process and route them in a proper way. After the transaction commits, the record will be available for external consumers.
This external consumer can be an asynchronous process that scans the “outbox” table or the database logs for new entries, and sends the message to an event bus, such as Apache Kafka. As Kafka comes with Kafka Connect, we can leverage the capabilities of the pre-defined connectors, for example the Debezium connector for PostgreSQL, to implement the change data capture (CDC) functionality.
Scenario
Let’s imagine a simple application where users can order certain products. An OrderService receives requests with order details that a user just sent. This service is required to do the following operations with the data:
- Persist the order data into its own local storage.
- Send an event to notify other services about the new order. These services might be responsible for checking the inventory (eg. InventoryService) or processing a payment (eg. PaymentService).
Since the two required steps are not atomic, it is possible that one of them is successful while the other fails. These failures can result in unexpected scenarios, and eventually corrupt the state of the applications.
In the first failure scenario, if the OrderService persists the data successfully but fails before publishing the message to Kafka, the application state becomes inconsistent:
Similarly, if the database transaction fails, but the event is published to Kafka, the application state becomes inconsistent.
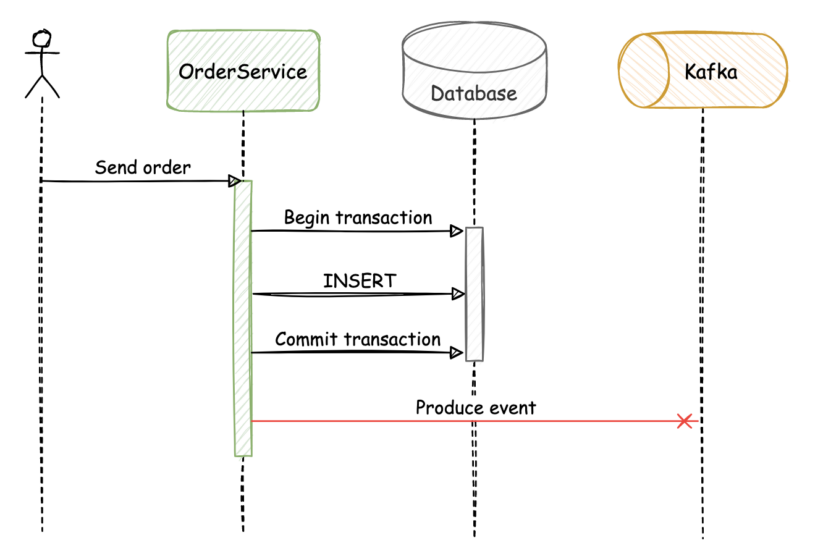
Solving these consistency problems in a different way would add unnecessary complexity to the business logic of the services, and might require implementing a synchronous approach. An important downside in this approach is that it introduces more coupling between the two services; another is that it does not let new consumers join the event stream and read the events from the beginning.
The same flow with an outbox implementation would look something like this:
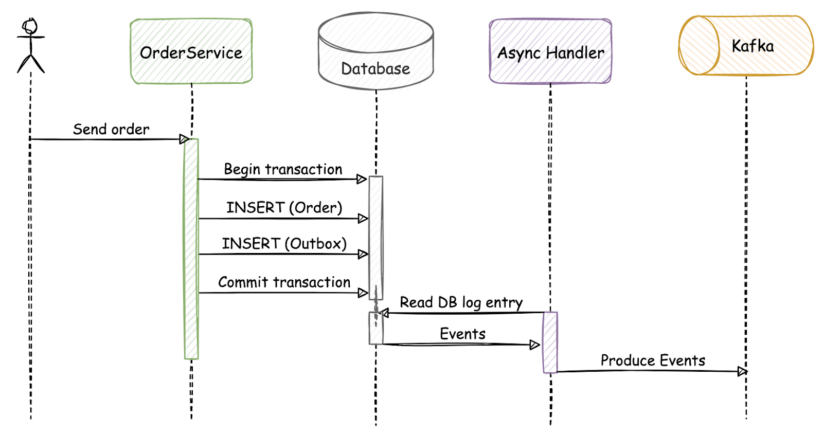
In this scenario, the “order” and “outbox” tables are updated in the same atomic transaction. After a successful commit, the asynchronous event handler that continuously monitors the database will notice the row-level changes, and send the event to Apache Kafka through Kafka Connect.
Implementation based on Cloudera Public Cloud and Debezium
The source code of the demo application is available on github. In the example, an order service receives new order requests from the user, saves the new order into its local database, then publishes an event, which will eventually end up in Apache Kafka. It is implemented in Java using the Spring framework. It uses a Postgres database as a local storage, and Spring Data to handle persistence. The service and the database run in docker containers.
For the streaming part, I am going to use the Cloudera Data Platform with Public Cloud to set up a Streams Messaging DataHub, and connect it to our application. This platform makes it very easy to provision and set up new workload clusters efficiently.
NOTE: Cloudera Data Platform (CDP) is a hybrid data platform designed for unmatched freedom to choose—any cloud, any analytics, any data. CDP delivers faster and easier data management and data analytics for data anywhere, with optimal performance, scalability, security, and governance.
The architecture of this solution looks like this on a high level:
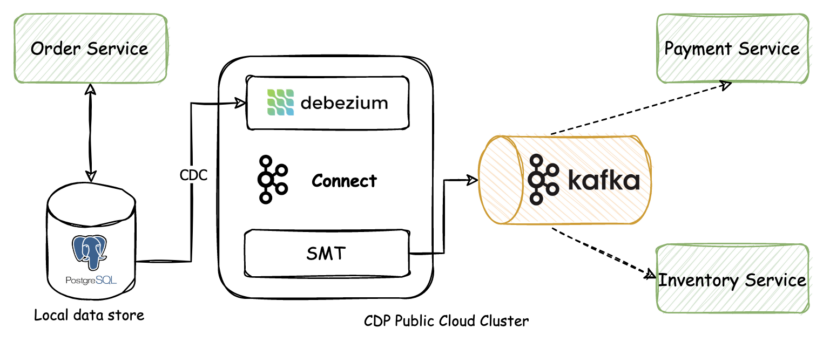
The outbox table
The outbox table is part of the same database where the OrderService saves its local data. When defining a schema for our database table, it is important to think about what fields are needed to process and route the messages to Kafka. The following schema is used for the outbox table:
| Column | Type |
| uuid | uuid |
| aggregate_type | character varying(255) |
| created_on | timestamp without time zone |
| event_type | character varying(255) |
| payload | character varying(255) |
The fields represent these:
- uuid: The identifier of the record.
- aggregate_type: The aggregate type of the event. Related messages will have the same aggregate type, and it can be used to route the messages to the correct Kafka topic. For example, all records related to orders can have an aggregate type “Order,” which makes it easy for the event router to route these messages to the “Order” topic.
- created_on: The timestamp of the order.
- event_type: The type of the event. It is required so that consumers can decide whether to process and how to process a given event.
- payload: The actual content of the event. The size of this field should be adjusted based on the requirements and the maximum expected size of the payload.
The OrderService
The OrderService is a simple Spring Boot microservice, which exposes two endpoints. There is a simple GET endpoint for fetching the list of orders, and a POST endpoint for sending new orders to the service. The POST endpoint’s handler not only saves the new data into its local database, but also fires an event inside the application.

The method uses the transactional annotation. This annotation enables the framework to inject transactional logic around our method. With this, we can make sure that the two steps are handled in an atomic way, and in case of unexpected failures, any change will be rolled back. Since the event listeners are executed in the caller thread, they use the same transaction as the caller.

Handling the events inside the application is quite simple: the event listener function is called for each fired event, and a new OutboxMessage entity is created and saved into the local database, then immediately deleted. The reason for the quick deletion is that the Debezium CDC workflow does not examine the actual content of the database table, but instead it reads the append-only transaction log. The save() method call creates an INSERT entry in the database log, while the delete() call creates a DELETE entry. For every INSERT event, the message will be forwarded to Kafka. Other events such as DELETE can be ignored now, as it does not contain useful information for our use case. Another reason why deleting the record is practical is that no additional disk space is needed for the “Outbox” table, which is especially important in high-scale streaming scenarios.
After the transaction commits, the record will be available for Debezium.
Setting up a streaming environment
To set up a streaming environment, I am going to use CDP Public Cloud to create a workload cluster using the 7.2.16 – Streams Messaging Light Duty template. With this template, we get a working streaming cluster, and only need to set up the Debezium related configurations. Cloudera provides Debezium connectors from 7.2.15 (Cloudera Data Platform (CDP) public cloud release, supported with Kafka 2.8.1+):
The streaming environment runs the following services:
- Apache Kafka with Kafka Connect
- Zookeeper
- Streams Replication Manager
- Streams Messaging Manager
- Schema Registry
- Cruise Control
Now setting up Debezium is worth another tutorial, so I will not go into much detail about how to do it. For more information refer to the Cloudera documentation.
Creating a connector
After the streaming environment and all Debezium related configurations are ready, it is time to create a connector. For this, we can use the Streams Messaging Manager (SMM) UI, but optionally there is also a Rest API for registering and handling connectors.
The first time our connector connects to the service’s database, it takes a consistent snapshot of all schemas. After that snapshot is complete, the connector continuously captures row-level changes that were committed to the database. The connector generates data change event records and streams them to Kafka topics.
A sample predefined json configuration in a Cloudera environment looks like this:
{ "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "database.history.kafka.bootstrap.servers": "${cm-agent:ENV:KAFKA_BOOTSTRAP_SERVERS}", "database.hostname": "[***DATABASE HOSTNAME***]", "database.password": "[***DATABASE PASSWORD***]", "database.dbname": "[***DATABASE NAME***]", "database.user": "[***DATABASE USERNAME***]", "database.port": "5432", "tasks.max": "1",, "producer.override.sasl.mechanism": "PLAIN", "producer.override.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"[***USERNAME***]\" password=\"[***PASSWORD***]\";", "producer.override.security.protocol": "SASL_SSL", "plugin.name": "pgoutput", "table.whitelist": "public.outbox", "transforms": "outbox", "transforms.outbox.type": "com.cloudera.kafka.connect.debezium.transformer.CustomDebeziumTopicTransformer", "slot.name": "slot1" } |
Description of the most important configurations above:
- database.hostname: IP address or hostname of the PostgreSQL database server.
- database.user: Name of the PostgreSQL database user for connecting to the database.
- database.password: Password of the PostgreSQL database user for connecting to the database.
- database.dbname: The name of the PostgreSQL database from which to stream the changes.
- plugin.name: The name of the PostgreSQL logical decoding plug-in installed on the PostgreSQL server.
- table.whitelist: The white list of tables that Debezium monitors for changes.
- transforms: The name of the transformation.
- transforms.<transformation>.type: The SMT plugin class that is responsible for the transformation. Here we use it for routing.
To create a connector using the SMM UI:
- Go to the SMM UI home page, select “Connect” from the menu, then click “New Connector”, and select PostgresConnector from the source templates.
- Click on “Import Connector Configuration…” and paste the predefined JSON representation of the connector, then click “Import.”
- To make sure the configuration is valid, and our connector can log in to the database, click on “Validate.”
- If the configuration is valid, click “Next,” and after reviewing the properties again, click “Deploy.”
- The connector should start working without errors.
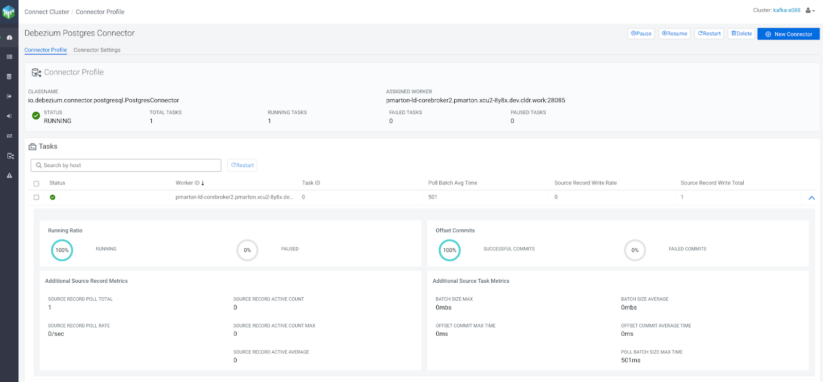
Once everything is ready, the OrderService can start receiving requests from the user. These requests will be processed by the service, and the messages will eventually end up in Kafka. If no routing logic is defined for the messages, a default topic will be created:
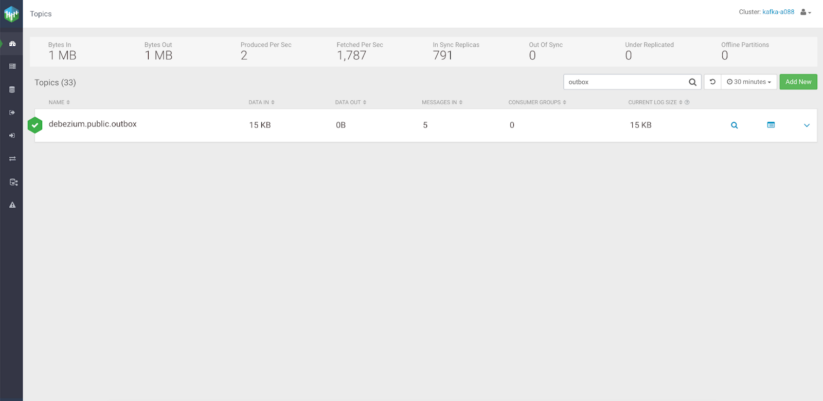
SMT plugin for topic routing
Without defining a logic for topic routing, Debezium will create a default topic in Kafka named “serverName.schemaName.tableName,” where:
- serverName: The logical name of the connector, as specified by the “database.server.name” configuration property.
- schemaName: The name of the database schema in which the change event occurred. If the tables are not part of a specific schema, this property will be “public.”
- tableName: The name of the database table in which the change event occurred.
This auto generated name might be suitable for some use cases, but in a real-world scenario we want our topics to have a more meaningful name. Another problem with this is that it does not let us logically separate the events into different topics.
We can solve this by rerouting messages to topics based on a logic we specify, before the message reaches the Kafka Connect converter. To do this, Debezium needs a single message transform (SMT) plugin.
Single message transformations are applied to messages as they flow through Connect. They transform incoming messages before they are written to Kafka or outbound messages before they are written to the sink. In our case, we need to transform messages that have been produced by the source connector, but not yet written to Kafka. SMTs have a lot of different use cases, but we only need them for topic routing.
The outbox table schema contains a field called “aggregate_type.” A simple aggregate type for an order related message can be “Order.” Based on this property, the plugin knows that the messages with the same aggregate type need to be written to the same topic. As the aggregate type can be different for each message, it is easy to decide where to route the incoming message.
A simple SMT implementation for topic routing looks like this:

The operation type can be extracted from the Debezium change message. If it is delete, read or update, we simply ignore the message, as we only care about create (op=c) operations. The destination topic can be calculated based on the “aggregate_type.” If the value of “aggregate_type” is “Order,” the message will be sent to the “orderEvents” topic. It is easy to see that there are a lot of possibilities of what we can do with the data, but for now the schema and the value of the message is sent to Kafka along with the destination topic name.
Once the SMT plugin is ready it has to be compiled and packaged as a jar file. The jar file needs to be present on the plugin path of Kafka Connect, so it will be available for the connectors. Kafka Connect will find the plugins using the plugin.path worker configuration property, defined as a comma-separated list of directory paths.
To tell the connectors which transformation plugin to use, the following properties must be part of the connector configuration:
| transforms | outbox |
| transforms.outbox.type | com.cloudera.kafka.connect.debezium.transformer.CustomDebeziumTopicTransformer |
After creating a new connector with the SMT plugin, instead of the default topic the Debezium producer will create a new topic called orderEvents, and route each message with the same aggregate type there:
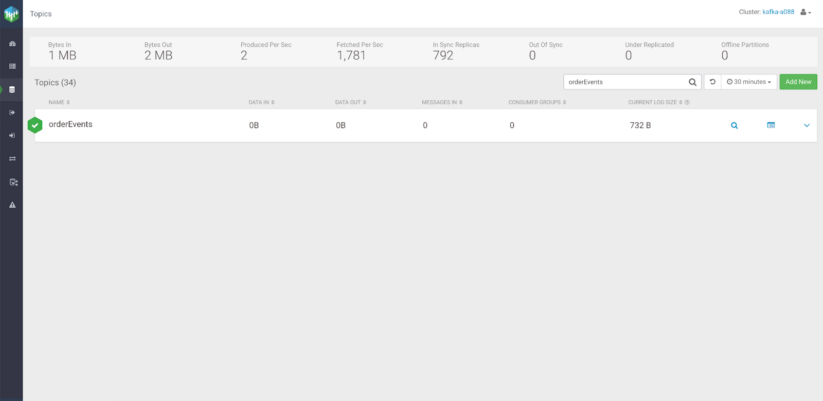
For existing SMT plugins, check the Debezium documentation on transformations.
Aggregate types and partitions
Earlier when creating the schema for the outbox table, the aggregate_type field was used to show which aggregate root the event is related to. It uses the same idea as a domain-driven design: related messages can be grouped together. This value can also be used to route these messages to the correct topic.
While sending messages that are part of the same domain to the same topic helps with separating them, sometimes other, stronger guarantees are needed, for example having related messages in the same partition so they can be consumed in order. For this purpose the outbox schema can be extended with an aggregate_id. This ID will be used as a key for the Kafka message, and it only requires a small change in the SMT plugin. All messages with the same key will go to the same partition. This means that if a process is reading only a subset of the partitions in a topic, all the records for a single key will be read by the same process.
At least once delivery
When the application is running normally, or in case of a graceful shutdown, the consumers can expect to see the messages exactly once. However, when something unexpected happens, duplicate events can occur.
In case of an unexpected failure in Debezium, the system might not be able to record the last processed offset. When they are restarted, the last known offset will be used to determine the starting position. Similar event duplication can be caused by network failures.
This means that while duplicate messages might be rare, consuming services need to expect them when processing the events.
Result
At this point, the outbox pattern is fully implemented: the OrderService can start receiving requests, persisting the new entities into its local storage and sending events to Apache Kafka in a single atomic transaction. Since the CREATE events need to be detected by Debezium before they are written to Kafka, this approach results in eventual consistency. This means that the consumer services may lag a bit behind the producing service, which is fine in this use case. This is a tradeoff that needs to be evaluated when using this pattern.
Having Apache Kafka in the core of this solution also enables asynchronous event-driven processing for other microservices. Given the right topic retention time, new consumers are also capable of reading from the beginning of the topic, and building a local state based on the event history. It also makes the architecture resistant to single component failures: if something fails or a service is not available for a given amount of time, the messages will be simply processed later—no need to implement retries, circuit breaking, or similar reliability patterns.
Try it out yourself!
Application developers can use the Cloudera Data Platform’s Data in Motion solutions to set up reliable data exchange between distributed services, and make sure that the application state stays consistent even under high load scenarios. To start, check out how our Cloudera Streams Messaging components work in the public cloud, and how easy it is to set up a production ready workload cluster using our predefined cluster templates.
Further reading
MySQL CDC with Kafka Connect/Debezium in CDP Public Cloud
The usage of secure Debezium connectors in Cloudera environments
Using Kafka Connect Securely in the Cloudera Data Platform
Editor's Choice

