

We just announced the general availability of Cloudera DataFlow Designer, bringing self-service data flow development to all CDP Public Cloud customers. In our previous DataFlow Designer blog post, we introduced you to the new user interface and highlighted its key capabilities. In this blog post we will put these capabilities in context and dive deeper into how the built-in, end-to-end data flow life cycle enables self-service data pipeline development.
Key requirements for building data pipelines
Every data pipeline starts with a business requirement. For example, a developer may be asked to tap into the data of a newly acquired application, parsing and transforming it before delivering it to the business’s favorite analytical system where it can be joined with existing data sets. Usually this is not just a one-off data delivery pipeline, but needs to run continuously and reliably deliver any new data from the source application. Developers who are tasked with building these data pipelines are looking for tooling that:
- Gives them a development environment on demand without having to maintain it.
- Allows them to iteratively develop processing logic and test with as little overhead as possible.
- Plays nice with existing CI/CD processes to promote a data pipeline to production.
- Provides monitoring, alerting, and troubleshooting for production data pipelines.
With the general availability of DataFlow Designer, developers can now implement their data pipelines by building, testing, deploying, and monitoring data flows in one unified user interface that meets all their requirements.
The data flow life cycle with Cloudera DataFlow for the Public Cloud (CDF-PC)
Data flows in CDF-PC follow a bespoke life cycle that starts with either creating a new draft from scratch or by opening an existing flow definition from the Catalog. New users can get started quickly by opening ReadyFlows, which are our out-of-the-box templates for common use cases.
Once a draft has been created or opened, developers use the visual Designer to build their data flow logic and validate it using interactive test sessions. When a draft is ready to be deployed in production, it is published to the Catalog, and can be productionalized with serverless DataFlow Functions for event-driven, micro-bursty use cases or auto-scaling DataFlow Deployments for low latency, high throughput use cases.

Figure 1: DataFlow Designer, Catalog, Deployments, and Functions provide a complete, bespoke flow life cycle in CDF-PC
Let’s take a closer look at each of these steps.
Creating data flows from scratch
Developers access the Flow Designer through the new Flow Design menu item in Cloudera DataFlow (Figure 2), which will show an overview of all existing drafts across workspaces that you have access to. From here it’s easy to continue working on an existing draft simply by clicking on the draft name, or creating a new draft and building your flow from scratch.
You can think of drafts as data flows that are in development and may end up getting published into the Catalog for production deployments but may also get discarded and never make it to the Catalog. Managing drafts outside the Catalog keeps a clean distinction between phases of the development cycle, leaving only those flows that are ready for deployment published in the Catalog. Anything that isn’t ready to be deployed to production should be treated as a draft.
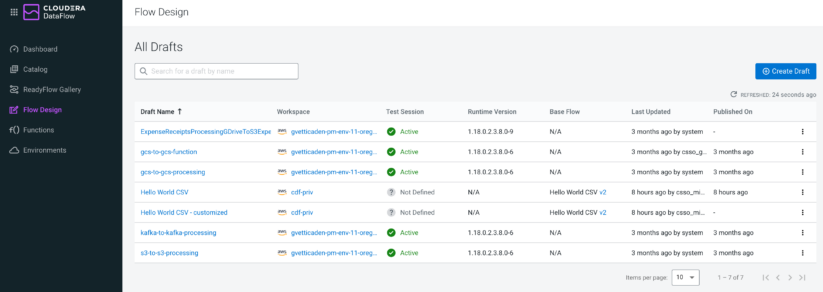
Figure 2: The Flow Design page provides an overview of all drafts across workspaces that you have permissions to
Creating a draft from ReadyFlows
CDF-PC provides a growing library of ReadyFlows for common data movement use cases in the public cloud. Until now, ReadyFlows served as an easy way to create a deployment through providing connection parameters without having to build any actual data flow logic. With the Designer being available, you can now create a draft from any ReadyFlow and use it as a baseline for your use case.
ReadyFlows jumpstart flow development and allow developers to onboard new data sources or destinations faster while getting the flexibility they need to adjust the templates to their use case.
You want to see how to get data from Kafka and write it to Iceberg? Just create a new draft from the Kafka to Iceberg ReadyFlow and explore it in the Designer.
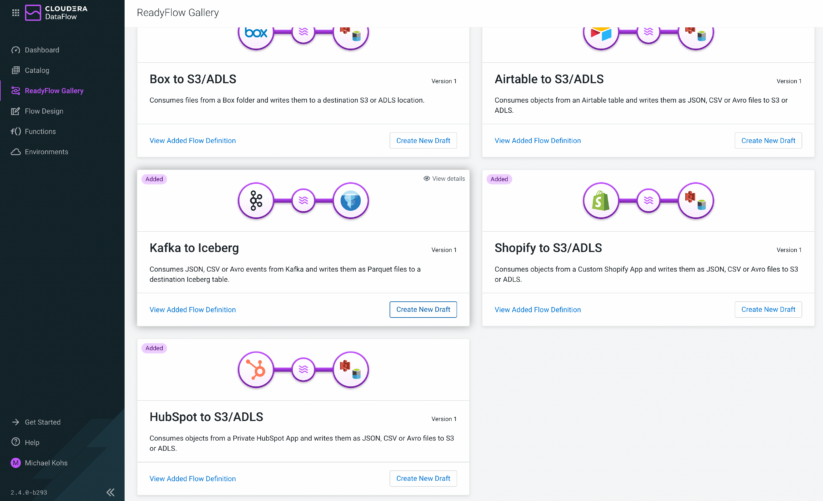
Figure 3: You can create a new draft based on any ReadyFlow in the gallery
After creating a new draft from a ReadyFlow, it immediately opens in the Designer. Labels explaining the purpose of each component in the flow help you understand their functionality. The Designer gives you full flexibility to modify this ReadyFlow, allowing you to add new data processing logic, more data sources or destinations, as well as parameters and controller services. ReadyFlows are carefully tested by Cloudera experts so you can learn from their best practices and make them your own!
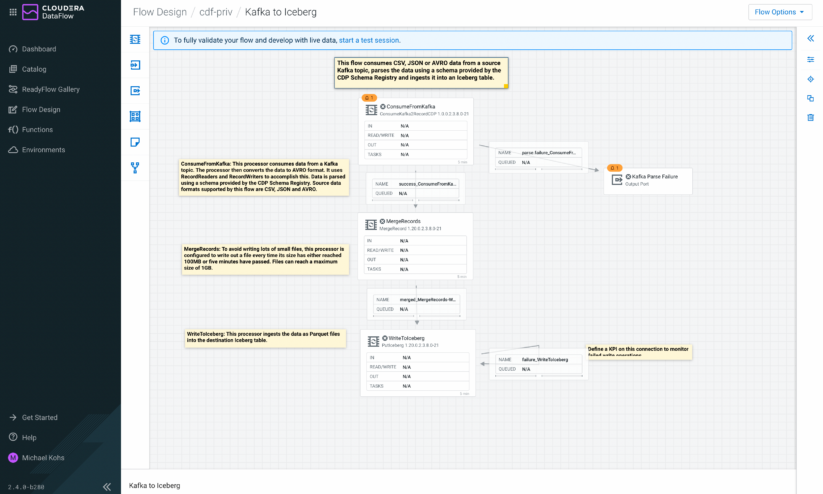
Figure 4: After creating a draft from a ReadyFlow, you can customize it to fit your use case
Agile, iterative, and interactive development with Test Sessions
When opening a draft in the Designer, you are instantly able to add more processors, modify processor configuration, or create controller services and parameters. A critical feature for every developer however is to get instantaneous feedback like configuration validations or performance metrics, as well as previewing data transformations for each step of their data flow.
In the DataFlow Designer, you can create Test Sessions to turn the canvas into an interactive interface that gives you all the feedback you need to quickly iterate your flow design.
Once a test session is active, you can start and stop individual components on the canvas, retrieve configuration warnings and error messages, as well as view recent processing metrics for each component.
Test Sessions provide this functionality by provisioning compute resources on the fly within minutes. Compute resources are only allocated until you stop the Test Session, which helps reduce development costs compared to a world where a development cluster would have to be running 24/7 regardless of whether it’s being used or not.
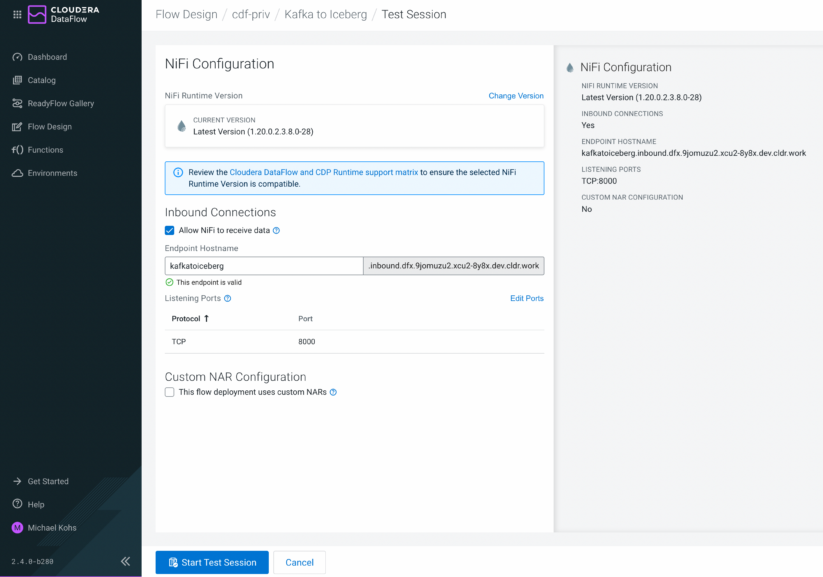
Figure 5: Test sessions now also support Inbound Connections, allowing you to test data flows that are receiving data from applications
Test sessions now also support Inbound Connections, making it easy to develop and validate a flow that listens and receives data from external applications using TCP, UDP, or HTTP. As part of the test session creation, CDF-PC creates a load balancer and generates the required certificates for clients to establish secure connections to your flow.
Inspect data with the built-in Data Viewer
To validate your flow, it’s crucial to have quick access to the data before and after applying transformation logic. In the Designer, you have the ability to start and stop each step of the data pipeline, resulting in events being queued up in the connections that link the processing steps together.
Connections allow you to list their content and explore all the queued up events and their attributes. Attributes contain key metadata like the source directory of a file or the source topic of a Kafka message. To make navigating through hundreds of events in a queue easier, the Flow Designer introduces a new attribute pinning feature allowing users to keep key attributes in focus so they can easily be compared between events.
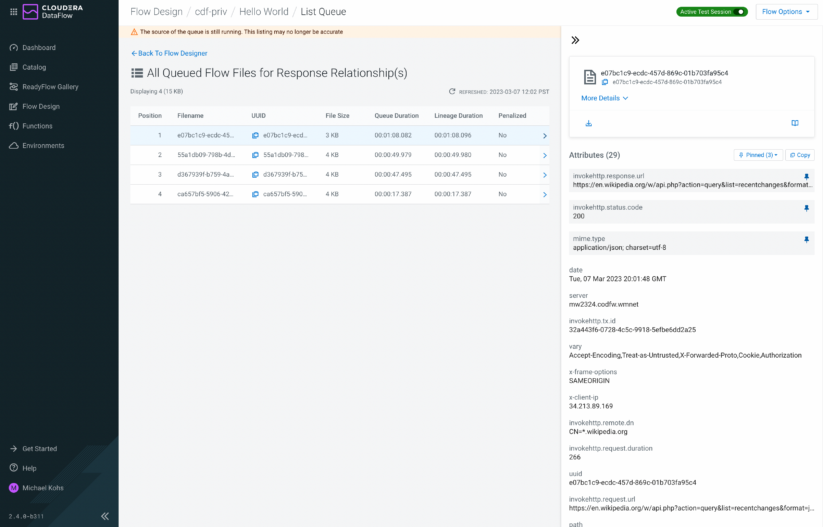
Figure 6: While listing the content of a queue, you can pin attributes for easy access
The ability to view metadata and pin attributes is very useful to find the right events that you want to explore further. Once you have identified the events you want to explore, you can open the new Data Viewer with one click to take a look at the actual data it contains. The Data Viewer automatically parses the data according to its MIME type and is able to format CSV, JSON, AVRO, and YAML data, as well as displaying data in its original format or HEX representation for binary data.
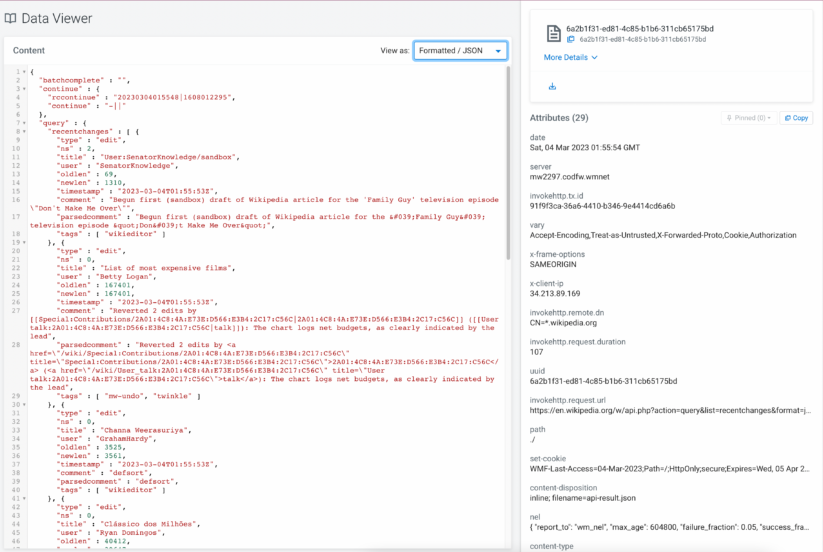
Figure 7: The built-in Data Viewer allows you to explore data and validate your transformation logic
By running data through processors step by step and using the data viewer as needed, you’re able to validate your processing logic during development in an iterative way without having to treat your entire data flow as one deployable unit. This results in a rapid and agile flow development process.
Publish your draft to the Catalog
After using the Flow Designer to build and validate your flow logic, the next step is to either run larger scale performance tests or deploy your flow in production. CDF-PC’s central Catalog makes the transition from a development environment to production seamless.
When you are developing a data flow in the Flow Designer, you can publish your work to the Catalog at any time to create a versioned flow definition. You can either publish your flow as a new flow definition, or as a new version of an existing flow definition.
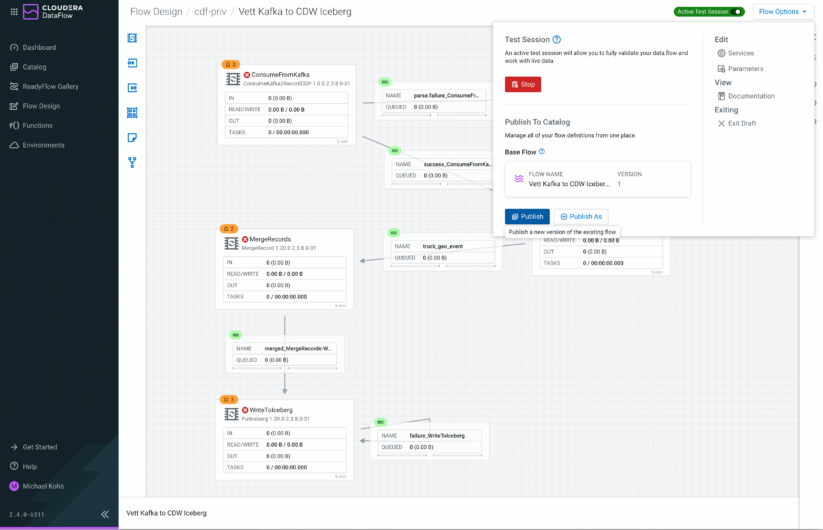
Figure 8: Publish your data flow as a new flow definition or new version to the Catalog
DataFlow Designer provides first class versioning support that developers need to stay on top of ever-changing business requirements or source/destination configuration changes.
In addition to publishing new versions to the Catalog, you can open any versioned flow definition in the Catalog as a draft in the Flow Designer and use it as the foundation for your next iteration. The new draft is then associated with the corresponding flow definition in the Catalog and publishing your changes will automatically create a new version in the Catalog.
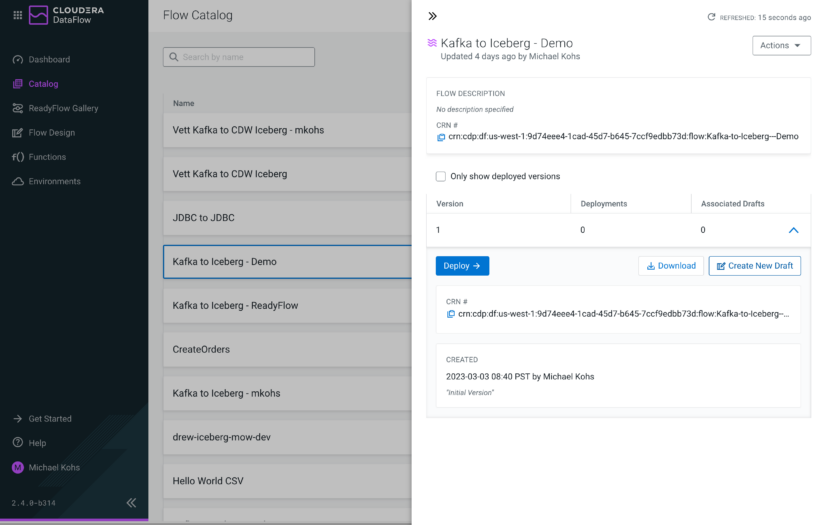
Figure 9: You can create new drafts from any version of published flow definitions in the Catalog
Run your data flow as an auto-scaling deployment or serverless function
CDF-PC offers two cloud-native runtimes for your data flows: DataFlow Deployments and DataFlow Functions. Any flow definition in the Catalog can be executed as a deployment or a function.
DataFlow Deployments provide a stateful, auto-scaling runtime, which is ideal for high throughput use cases with low latency processing requirements. DataFlow Deployments are typically long running, handle streaming or batch data, and automatically scale up and down between a defined minimum and maximum number of nodes. You can create DataFlow Deployments using the Deployment Wizard, or automate them using the CDP CLI.
DataFlow Functions provides an efficient, cost optimized, scalable way to run data flows in a completely serverless fashion. DataFlow Functions are typically short lived and executed following a trigger, like a file arriving in an object store location or an event being published to a messaging system. To run a data flow as a function, you can use your favorite cloud provider’s tooling to create and configure a function and link it to any data flow that has been published to the DataFlow Catalog. DataFlow Functions are supported on AWS Lambda, Azure Functions, and Google Cloud Functions.
Looking ahead and next steps
The general availability of the DataFlow Designer represents an important step to deliver on our vision of a cloud-native service that organizations can use to enable Universal Data Distribution, and is accessible to any developer regardless of their technical background. Cloudera DataFlow for the Public Cloud (CDF-PC) now covers the entire data flow life cycle from developing new flows with the Designer through testing and running them in production using DataFlow Deployments or DataFlow Functions.
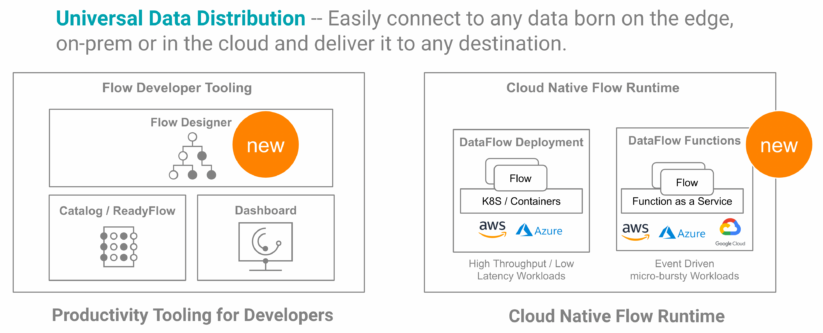
Figure 10: Cloudera DataFlow for the Public Cloud (CDF-PC) enables Universal Data Distribution
The DataFlow Designer is available to all CDP Public Cloud customers starting today. We are excited to hear your feedback and we hope you will enjoy building your data flows with the new Designer.
To learn more, take the product tour or check out the DataFlow Designer documentation.
Editor's Choice

