

As the use of ChatGPT becomes more prevalent, I frequently encounter customers and data users citing ChatGPT’s responses in their discussions. I love the enthusiasm surrounding ChatGPT and the eagerness to learn about modern data architectures such as data lakehouses, data meshes, and data fabrics. ChatGPT is an excellent resource for gaining high-level insights and building awareness of any technology. However, caution is necessary when delving deeper into a particular technology. ChatGPT is trained on historical data and depending on how one phrases their question, it may offer inaccurate or misleading information.
I took the free version of ChatGPT on a test drive (in March 2023) and asked some simple questions on data lakehouse and its components. Here are some responses that weren’t exactly right, and our explanation on where and why it went wrong. Hopefully this blog will give ChatGPT an opportunity to learn and correct itself while counting towards my 2023 contribution to social good.
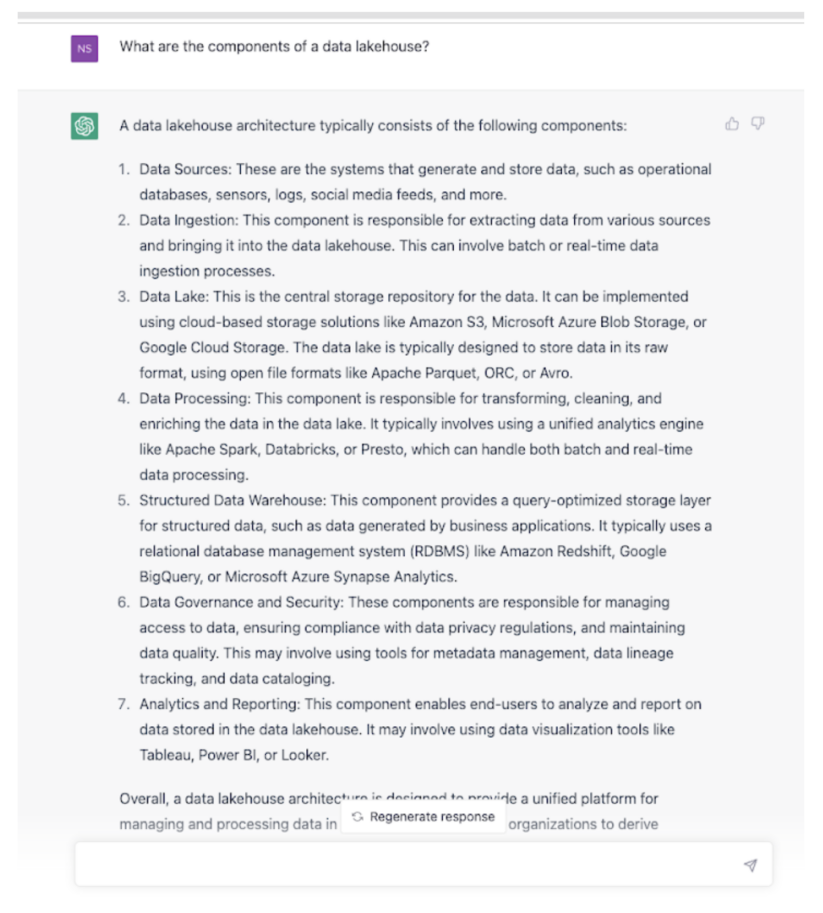
I thought this was a fairly comprehensive list. The one key component that is missing is a common, shared table format, that can be used by all analytic services accessing the lakehouse data. When implementing a data lakehouse, the table format is a critical piece because it acts as an abstraction layer, making it easy to access all the structured, unstructured data in the lakehouse by any engine or tool, concurrently. The table format provides the necessary structure for the unstructured data that is missing in a data lake, using a schema or metadata definition, to bring it closer to a data warehouse. Some of the popular table formats are Apache Iceberg, Delta Lake, Hudi, and Hive ACID.
Also, the data lake layer is not limited to cloud object stores. Many companies still have massive amounts of data on premises and data lakehouses are not limited to public clouds. They can be built on premises or as hybrid deployments leveraging private clouds, HDFS stores, or Apache Ozone.
At Cloudera, we also provide machine learning as part of our lakehouse, so data scientists get easy access to reliable data in the data lakehouse to quickly launch new machine learning projects and build and deploy new models for advanced analytics.

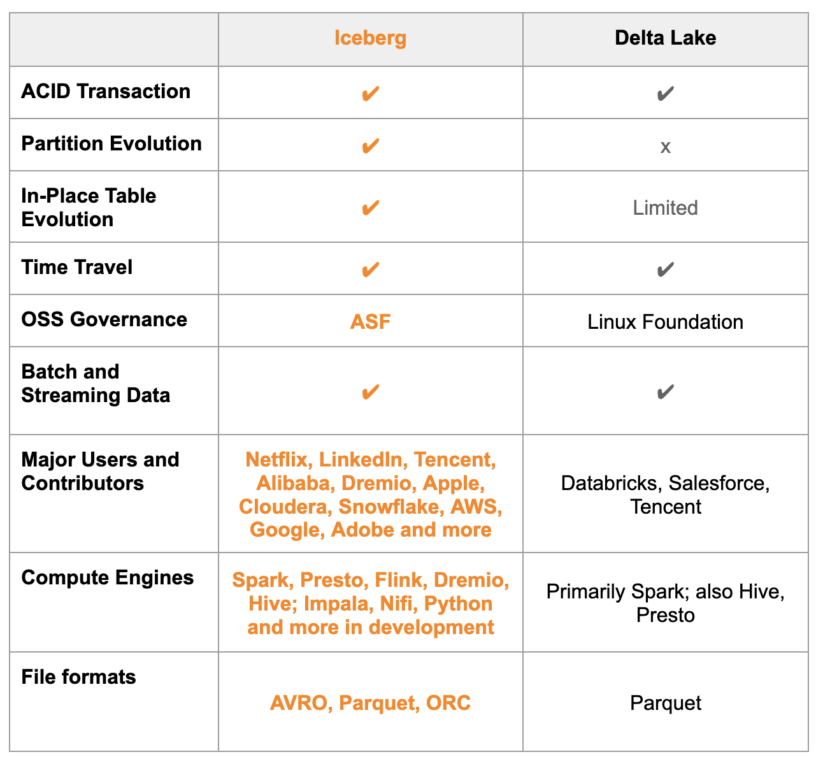
I like how ChatGPT started this answer, but it quickly jumps into features and even gives an incorrect response on the feature comparison. Features are not the only way of deciding which is a better table format. It depends on compatibility, openness, versatility, and other factors that can guarantee broader usage for varied data users, guarantee security and governance, and future-proof your architecture.
Here is a high-level feature comparison chart if you want to go into the details of what’s available on Delta Lake versus Apache Iceberg.

This response is a little dangerous because of its incorrectness and demonstrates why I feel these tools are not ready for deeper analysis. At first glance it may look like a reasonable response, but its premise is wrong, which makes you doubt the entire response and other responses as well. Saying “Delta Lake is built on top of Apache Iceberg” is incorrect as the two are completely different, unrelated table formats and one has nothing to do with the conception of the other. They were created by different organizations to solve common data problems.

I am impressed that ChatGPT got this one right, although it made a few mistakes with our product names, and missed a few that are critical for a lakehouse implementation.
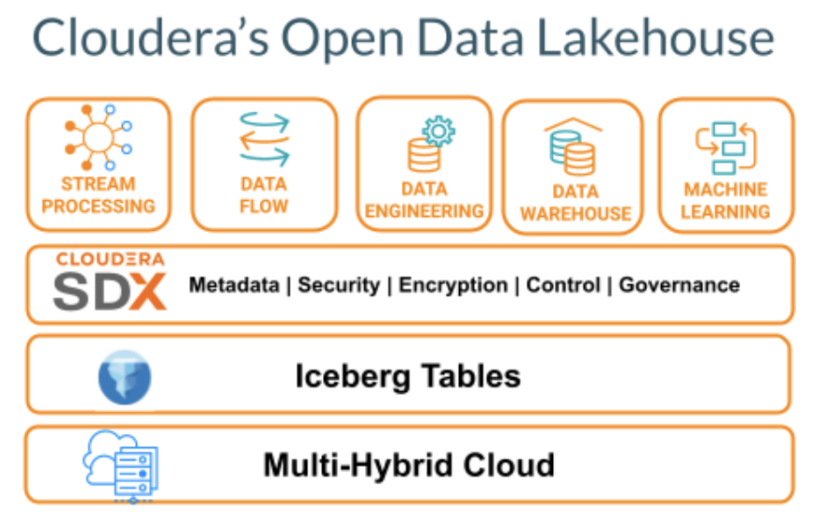
CDP’s components that support a data lakehouse architecture include:
- Apache Iceberg table format that is integrated into CDP to provide structure to the massive amounts of structured, unstructured data in your data lake.
- Data services, including cloud native data warehouse called CDW, data engineering service called CDE, data streaming service called data in motion, and machine learning service called CML.
- Cloudera Shared Data Experience (SDX), which provides a unified data catalog with automatic data profilers, unified security, and unified governance over all your data both in the public and private cloud.
ChatGPT is a great tool to get a high-level view of new technologies, but I’d say use it carefully, validate its responses, and use it only for the awareness stage of the buying cycle. As you go into the consideration or comparison stage, it’s not reliable yet.
Also, answers on ChatGPT keep updating so hopefully it corrects itself before you read this blog.
To learn more about Cloudera’s lakehouse visit the webpage and if you are ready to get started watch the Cloudera Now demo.
Editor's Choice

