

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
According to a recent study from Marketwatch, the Hadoop market is expected to exceed more than $50.0 billion by 2022. The global Hadoop market is positioned for staggering growth in the upcoming years. Since its birth over a decade ago, Hadoop has evolved into a robust platform for Big Data storage and analysis. A recent study from Transparency Market Research states that not only is it growing, the global Hadoop market revenue is expected to expand to a 29% CAGR between 2017 – 2023.
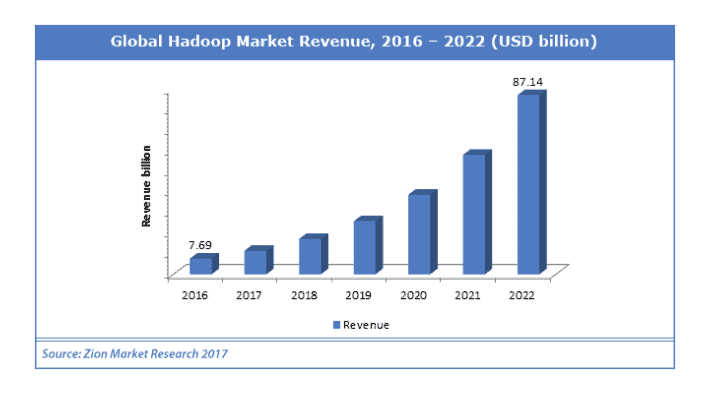
Another study from Zion Market Research shows the the Hadoop market is expected to reach $87 billion by 2022 developing at a CAGR of almost 50% from 2017 to 2022. Although these numbers differ slightly, they are all pointing in the direction of growth!
Hadoop means innovation
As the product marketing lead for Hortonworks Data Platform who has been with Hortonworks for the last 3 years, I need to speak out in support of Apache Hadoop and all the innovation surrounding it. Over these last 3 years, I have seen interest in Hadoop and big data turn more mainstream to the point where we no longer just speak about Apache Hadoop. Hadoop is much more than HDFS and MapReduce. At present, with the explosion of data due to increasing use of electronic devices has necessitated the adoption of a reliable tool to manage and utilize this data. Hadoop is one of these tools!
Hadoop is about helping big data become more mainstream to support current enterprise needs and use cases. It’s about the vibrance of the community, the continued innovation, and the value of our platform, Hortonworks Data Platform (HDP). Hadoop has been embraced and is also at the core of all the cloud providers including Amazon Web Services, Microsoft Azure, and Google Cloud Platform. Microsoft uses Hortonworks Data Platform under the hood for Azure HDInsight, their managed Hadoop-as-a-Service platform and IBM, uses HDP as their core Hadoop platform. In addition, with the recent release of Hadoop 3.1, there are some incredible innovations around containerization, GPU support, erasure coding and improvements in intra-queue preemption to prioritize jobs based on user limits and/or application priority. There are so many more innovations in this latest release!
Why has Hadoop grown so fast?
It’s because of its native open source roots which requires tremendous commitment and dedication from the open-source community and ecosystem. There is a tremendous following! It’s about capturing all the new data – data that originates in the cloud, sensor data, clickstream data and helping companies get insights from all the data. Hortonworks, has proved that you can turn this technology into a successful business model with total revenue growth of 40 percent year over year. Quite amazing!

With that said, as we see Hadoop and big data continue to evolve, we see new requirements appearing. Deployment models continue to expand to migrate to the cloud and various forms of multi-cloud, hybrid and private cloud. Customers want to see consistent security and governance across on-prem and cloud. Data scientists and analysts want immediate insights from all this data. Developers want to create and launch new applications quickly (machine learning and AI). Line of business leaders want to solve problems that help create new revenue streams for the business with operational ease and real cost savings. IT wants to manage their environment more efficiently at a lower cost. The big data ecosystem and Hadoop can address these challenges of today as well as new market requirements of the future with the use of other Apache projects on top of Hadoop including Apache Hive, Apache Spark, Apache Kafka, Apache Ranger, Apache Atlas and Apache HBase, just to name a few. This shows the maturity of the market and the signs of a strong ecosystem that is meeting the demands of businesses.
Closing remarks
As in all growth phases of technology (for example; PCs, client server, servers to virtualization and big data, palm pilots, flip phones to smartphones), one growth phase leads to the new beginnings of another growth phase of the technology. What’s great about big data and the Hadoop ecosystem is all the innovations from the community to take things to a new level. Working with customers, it has become clear that Hortonworks Data Platform based on Apache Hadoop has evolved into a global data management platform that enables enterprises to embark on their digital transformation journey and grow their business with scale. It is more than just Hadoop. Based on the customers I’ve spoken with and the interest in our platform, the open source community, attendance at conferences, webinars and all our blog views on Hadoop, we are just at the beginning of taking Hadoop to a new level!
For more information – read our Hadoop blog series.
Hadoop 3.X
- Apache Hadoop 3.1.0 released. And a look back!
- Apache Hadoop 3.1 – A Giant Leap for Big Data
- How Apache Hadoop 3 Adds Value Over Apache Hadoop 2
- Announcing HDP 3.0 – Faster, Smarter, Hybrid Data
- Announcing the General Availability of HDP 3.0, Ambari 2.7, and SmartSense 1.5
- Upgrading your clusters from Apache Hadoop 2 to Apache Hadoop
Faster time-to-insight – Containerization support on YARN
- Trying Out Containerized Applications on Apache Hadoop YARN 3.1
- Containerized Apache Spark on YARN in Apache Hadoop 3.1
Long-running services support on YARN
- Apache Hive LLAP as a YARN Service
- First-Class Support for Long Running Services on Apache Hadoop YARN
- Enforcing Applications Lifetime SLAs on YARN
GPU Support – Machine Learning and Deep Learning apps
Lower Total-cost-of ownership – Erasure Coding
Read our Data Science blog series – which is enabled by Hadoop
Read our white paper
- White paper: Apache Hadoop 3 Improves Big Data Workloads
Watch our webinar
- Ventana Research & Hortonworks: Improve Big Data Workloads with Apache Hadoop 3 and Containerization
Learn about the Open Hybrid Architecture Initiative – Read the blog from Arun Murthy
Editor's Choice

