

When working on complex, or rigorous enterprise machine learning projects, Data Scientists and Machine Learning Engineers experience various degrees of processing lag training models at scale. While model training on small data can typically take minutes, doing the same on large volumes of data can take hours or even weeks. To overcome this, practitioners often turn to NVIDIA GPUs to accelerate machine learning and deep learning workloads.
CPUs and GPUs can be used in tandem for data engineering and data science workloads. A typical machine learning workflow involves data preparation, model training, model scoring, and model fitting. Practitioners can use existing general-purpose CPUs, or they can accelerate the workflow end-to-end with GPUs. While in the past effectively leveraging GPUs has been difficult, enabling this capability today on the Cloudera Data Platform (CDP) is turn-key. Data scientists can leverage best-in-class GPU computing frameworks from NVIDIA natively in CDP on any cloud and on-premises through CDP Private Cloud Base. Cloudera, together with NVIDIA make it easier than ever to optimize data science workflows and execute compute-heavy processes in a fraction of the time as before.
In this blog post series, we are going to explore options to get access, utilize, and benefit from using GPUs in Cloudera Machine Learning (CML) on CDP.
In this post, we will provision and configure GPU resources for a CML Workspace.
Using GPUs in CML
First, log in to CDP Control Plane and click to Machine Learning.
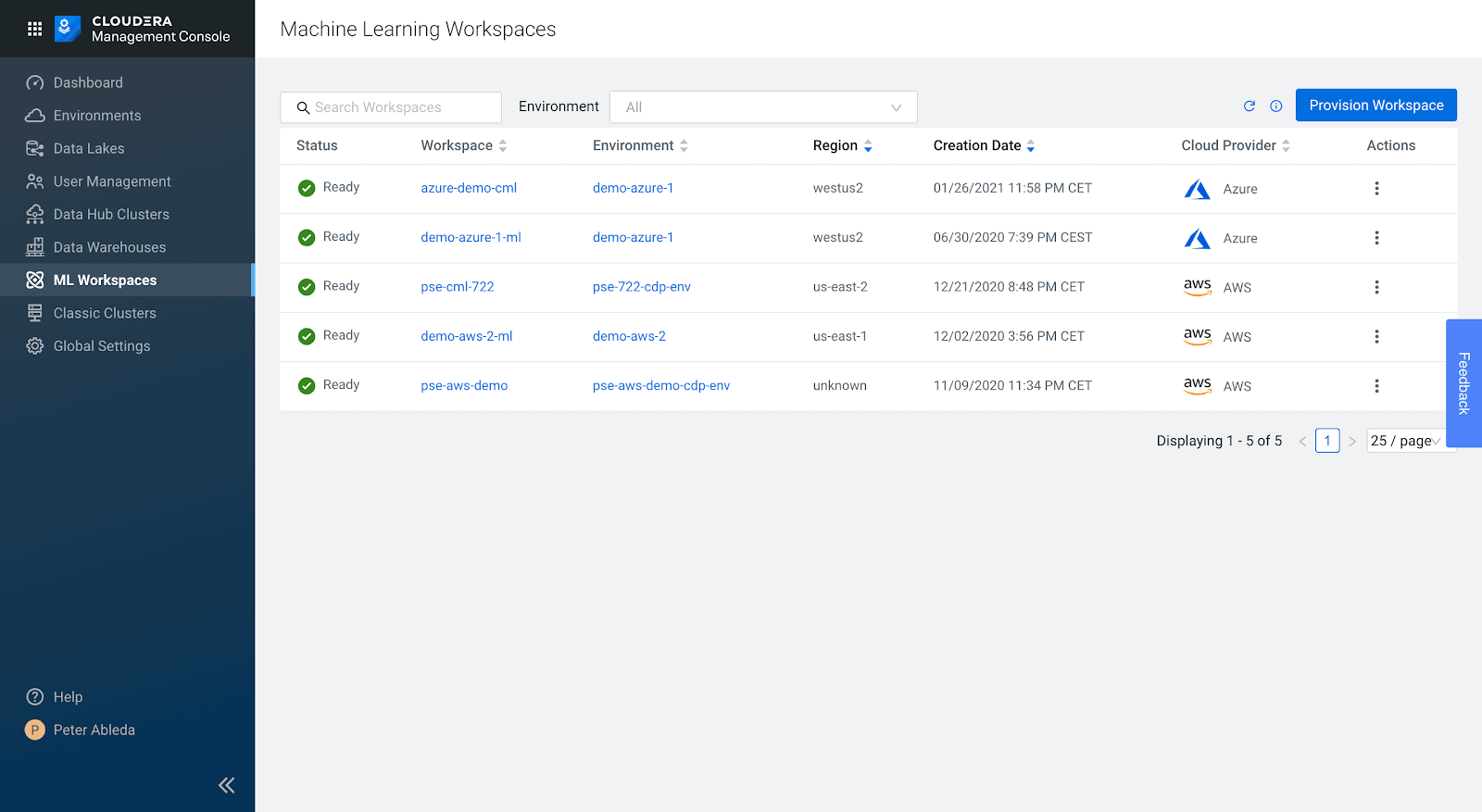
Create a New Machine Learning Workspace by clicking on Provision Workspace.
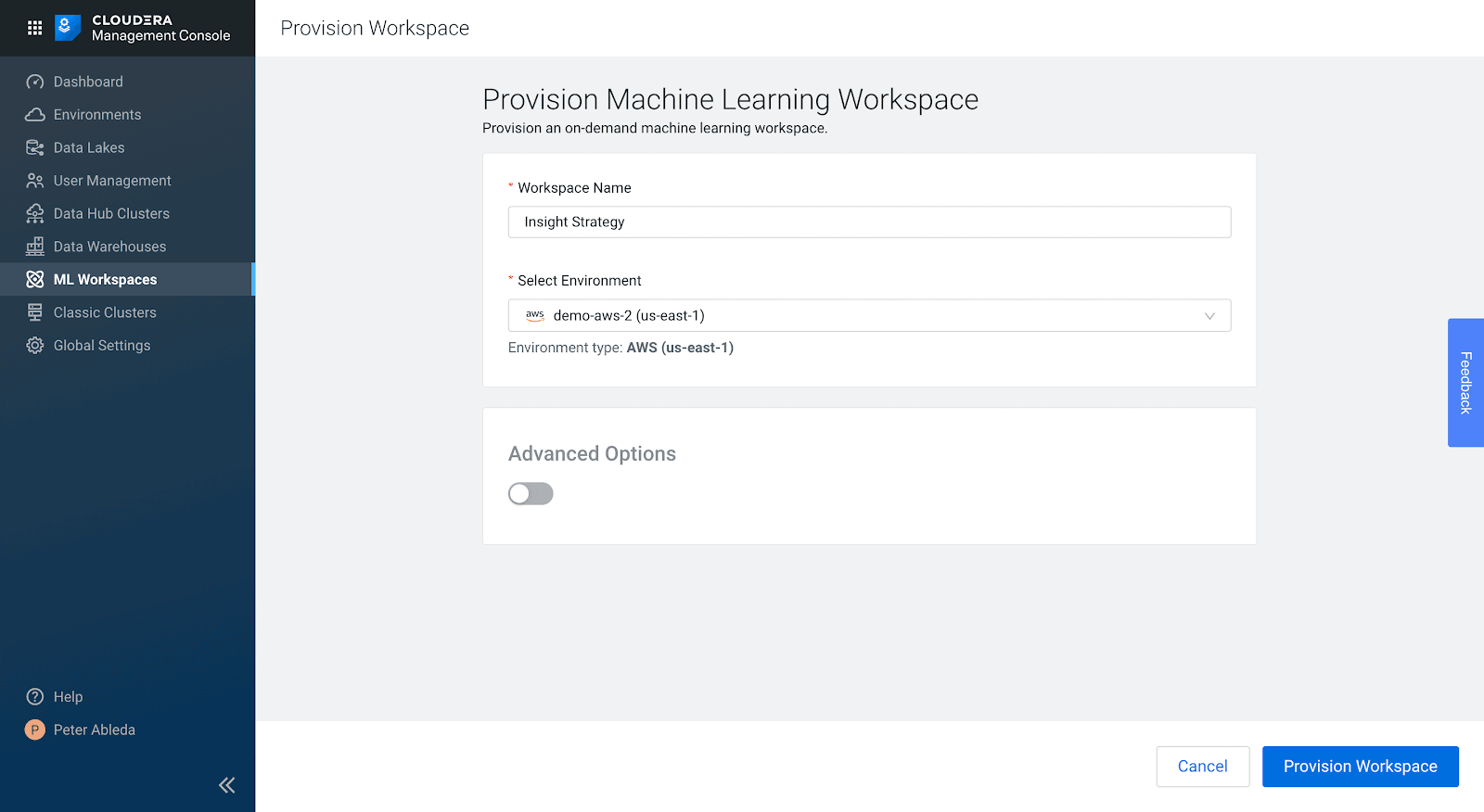
Name the workspace and select the Environment to use. Click on Advanced Options at the bottom. Here you can designate GPUs for your workspace.
Select the GPU instance type you are looking to use.
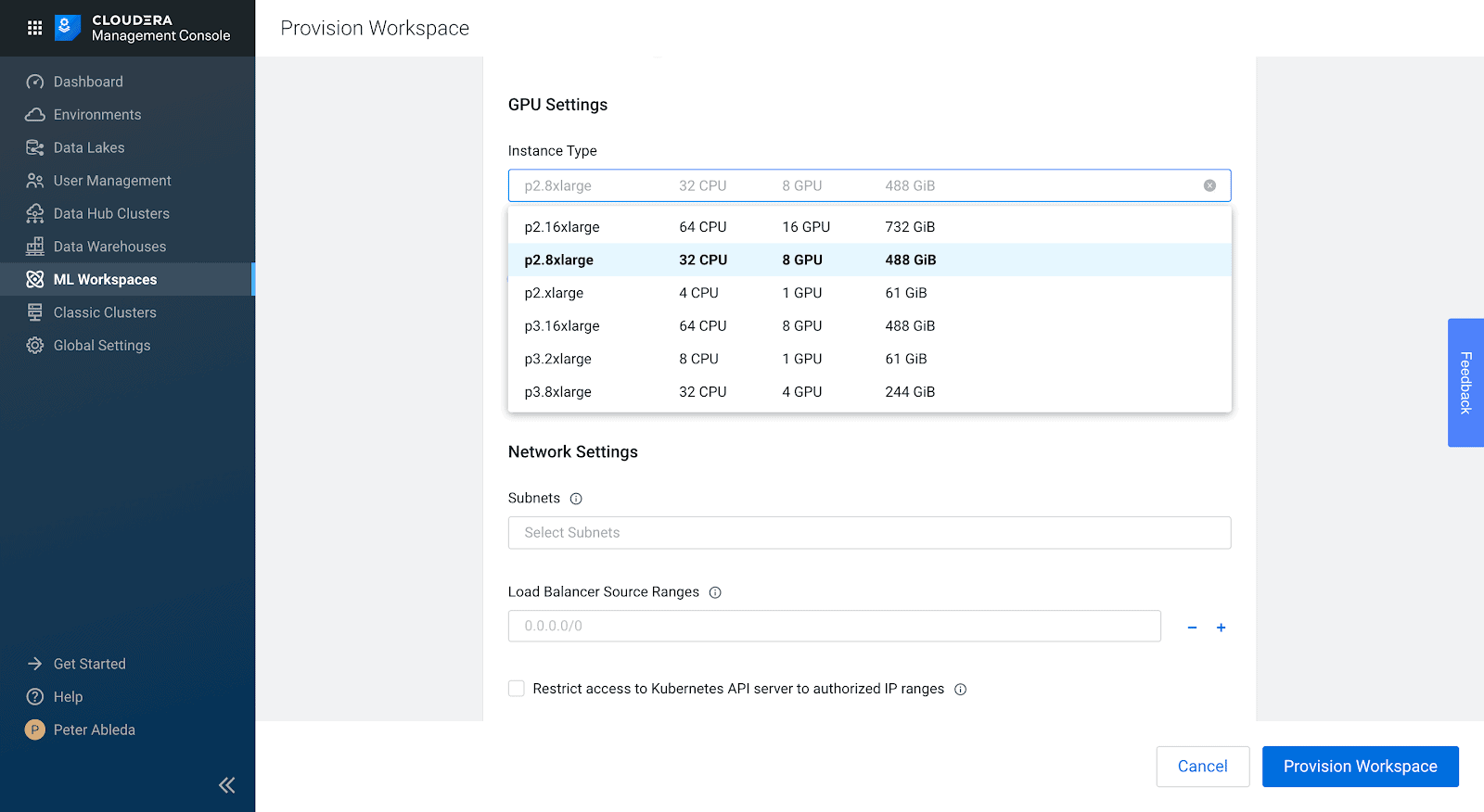
Selecting the GPU Instance types needs careful consideration of the numbers and types of GPU workloads expected to run in the workspace.
____________________________________________________________________________________________________
GPU Selection
Different instance types will have different GPU instances. Generally, newer GPUs will have more features and run code faster but libraries may need to be recompiled to best take advantage of these. At the time of writing, A100s available in AWS EC2 P4 instances are the newest generation of GPUs available. Different GPUs also have different RAM capacities, since GPU VRAM is usually the main constraint for data processing ensuring you select a GPU model that can ideally fit all your data within its VRAM is another consideration.
A general rule of thumb is to select the newest generation of GPU instances that you can afford with the maximum number of GPUs that you can program for. With machine learning applications, leveraging multiple GPUs require sometimes complex code changes so consider whether the use case being undertaken justifies the extra engineering effort. The GPU you select for a machine learning application generally also needs to be able to fully fit the model that you are training on it. With NVIDIA RAPIDS and Spark 3 GPU applications, ensuring that you have enough VRAM available to process all your data without blowing out processing costs is the main consideration.
____________________________________________________________________________________________________
Select the GPU autoscaling range.
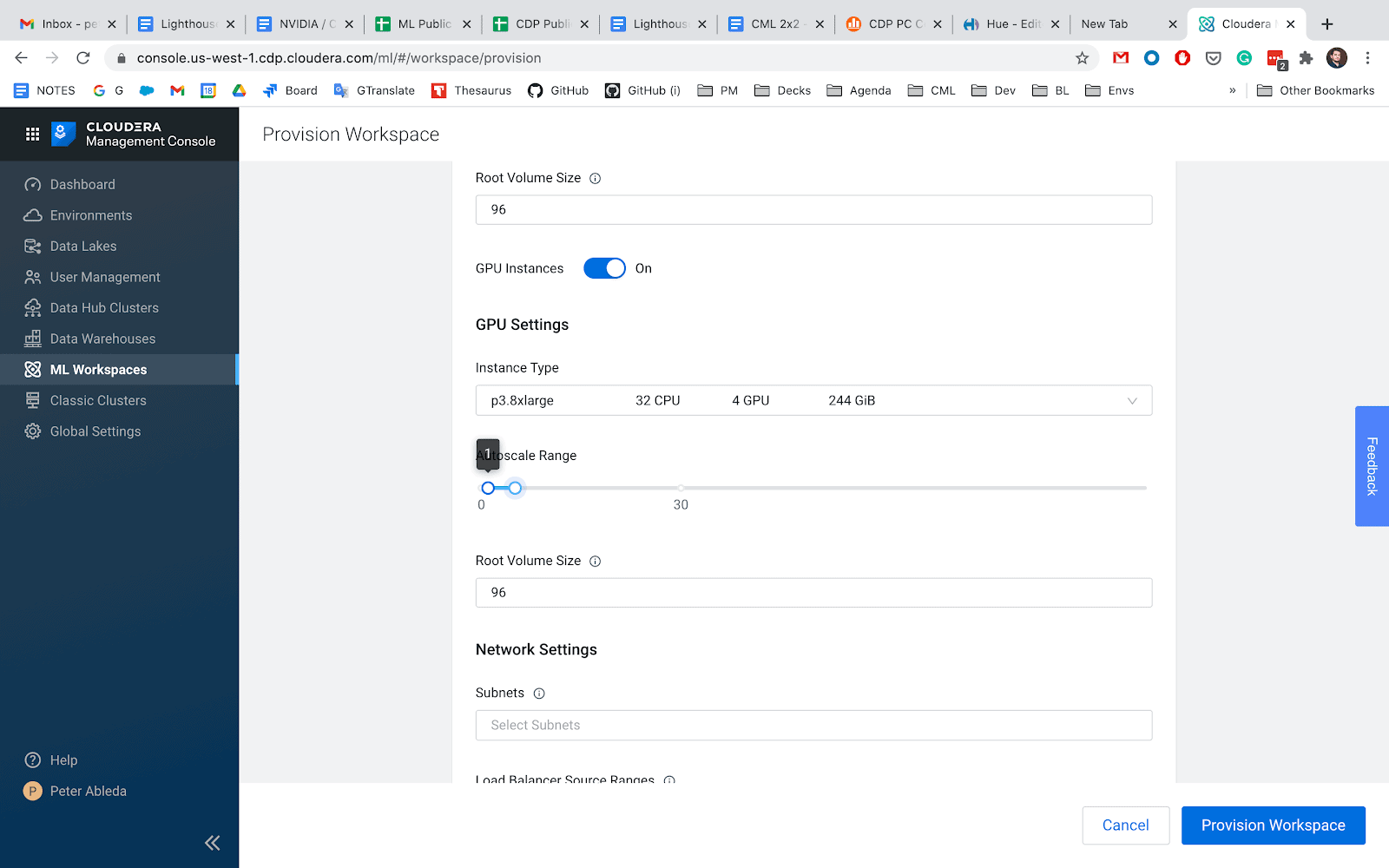
By setting the autoscaling range you can configure the minimum and the maximum number of instances that can run in the CML Workspace. The number of running instances will be dynamically adjusted considering the number and resource requirements of your GPU workloads.
There are tradeoffs to make while selecting the Autoscale Ranges. When the autoscale range starts at zero, the first GPU workload will take several minutes to start. This is not ideal if you need immediate compute for real-time projects. During this time a new GPU instance will be provisioned and attached to the CML Workspace.
Setting the minimum range higher will provision the GPU instances during the workspace creation and will enable workloads to start up in a matter of seconds. Having GPU instances available introduces additional operation costs regardless of actual resource usage
Create a New Project and Start a GPU Session:
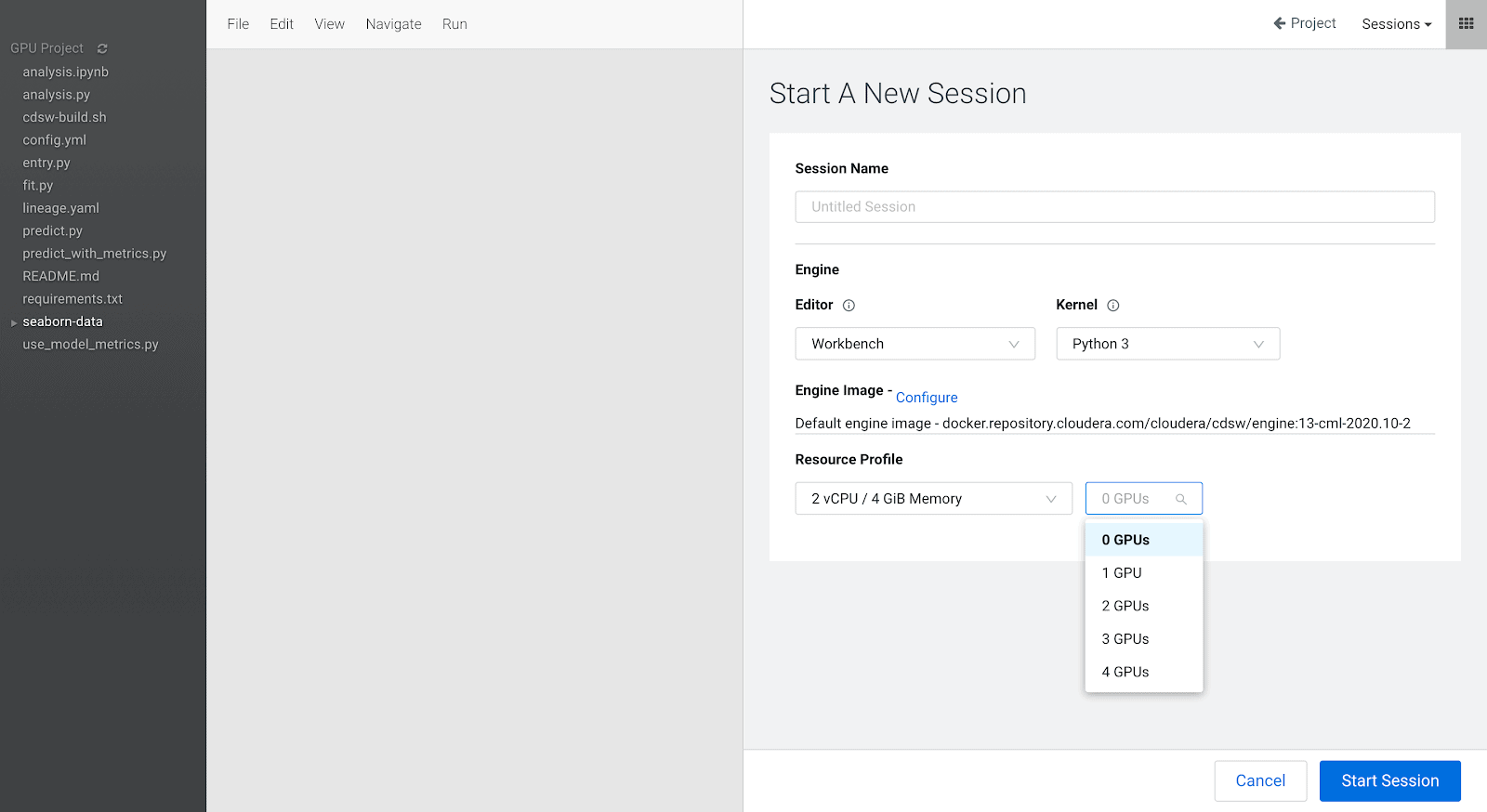
If you configure the Workspace with a zero minimum autoscaling range we will need to wait a few minutes while the first GPU node gets provisioned and added to the cluster:
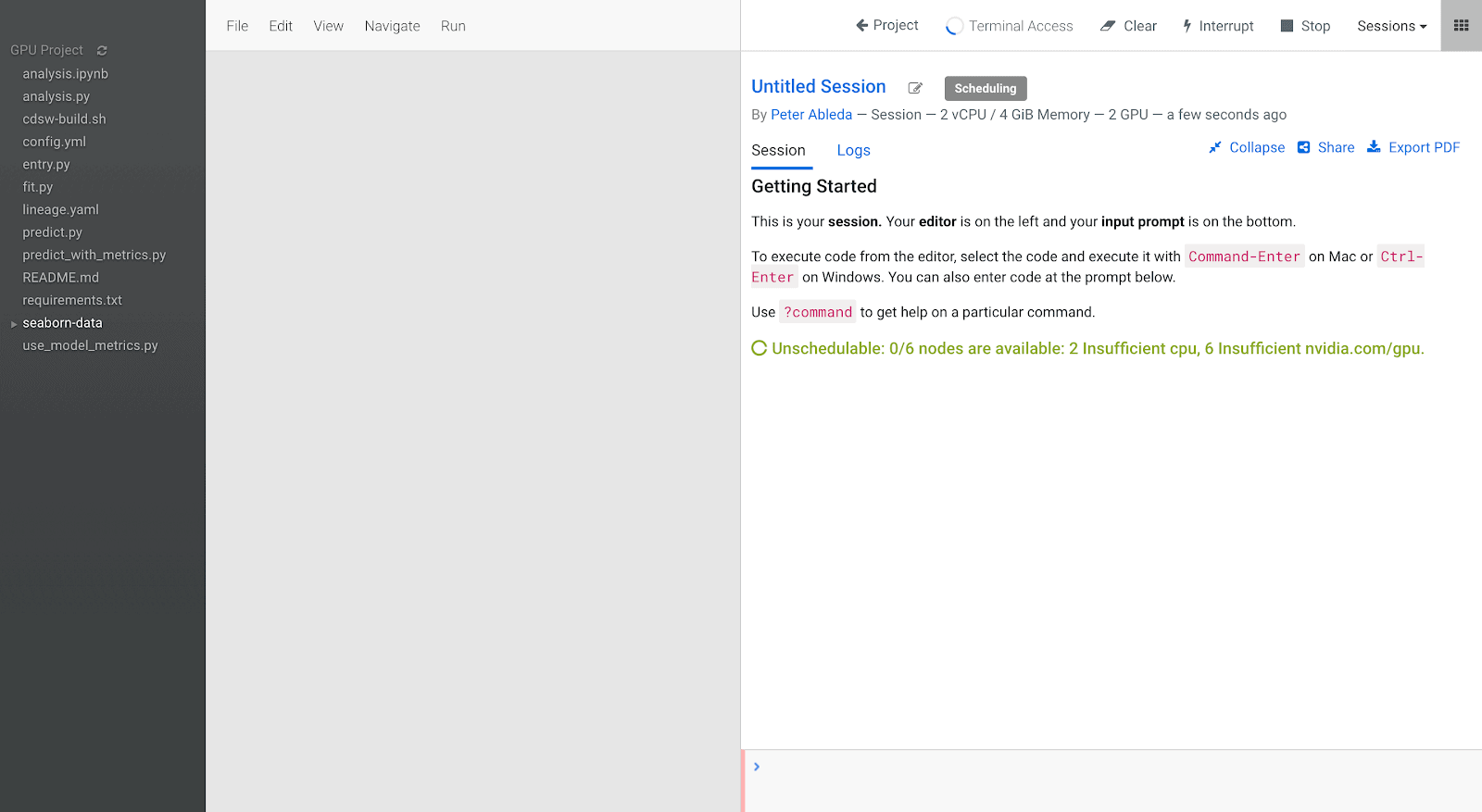
Once it’s provisioned we can see that 2 GPUs are available:
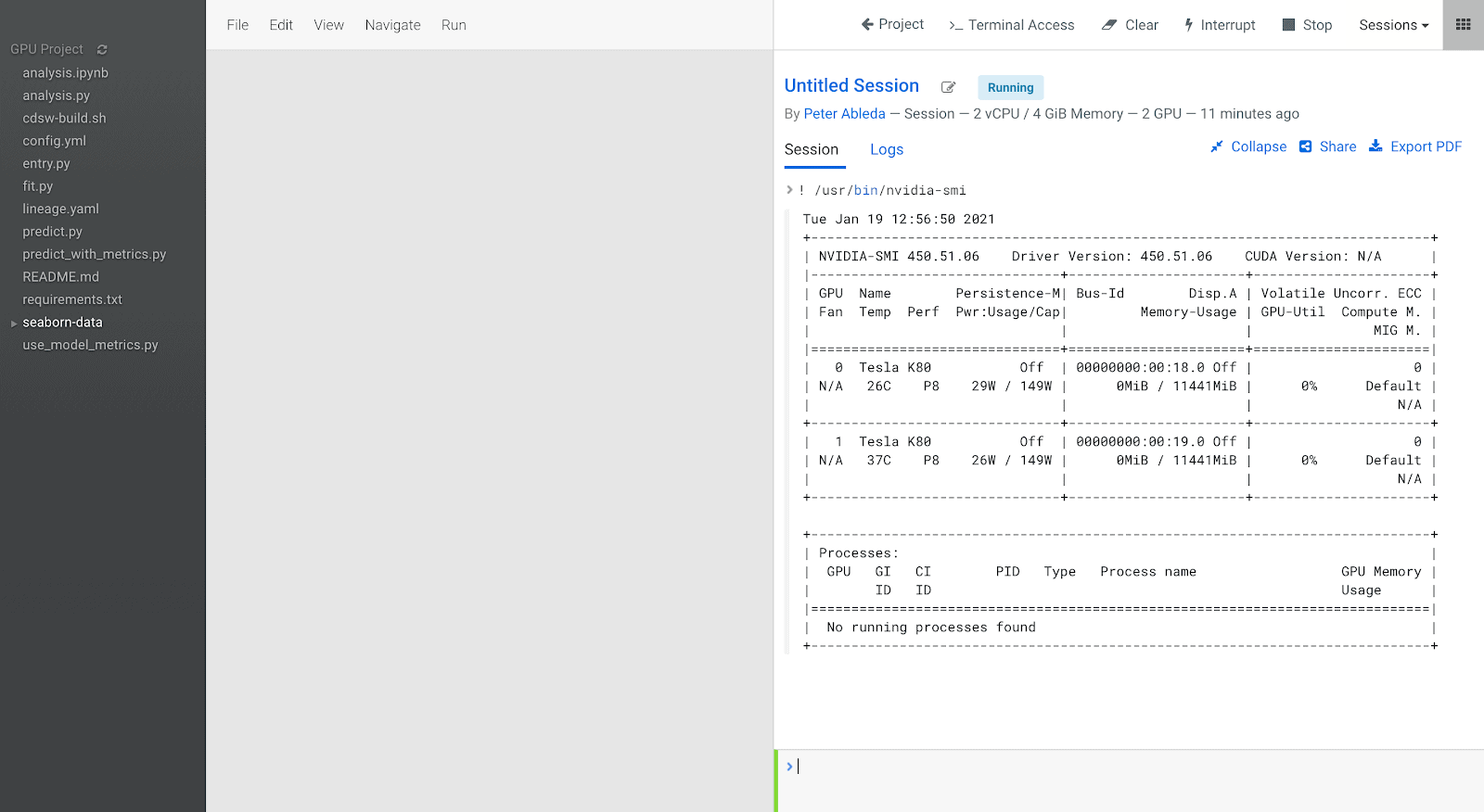
Meanwhile, on the CML Dashboard we can see both consumption and availability of compute resources:
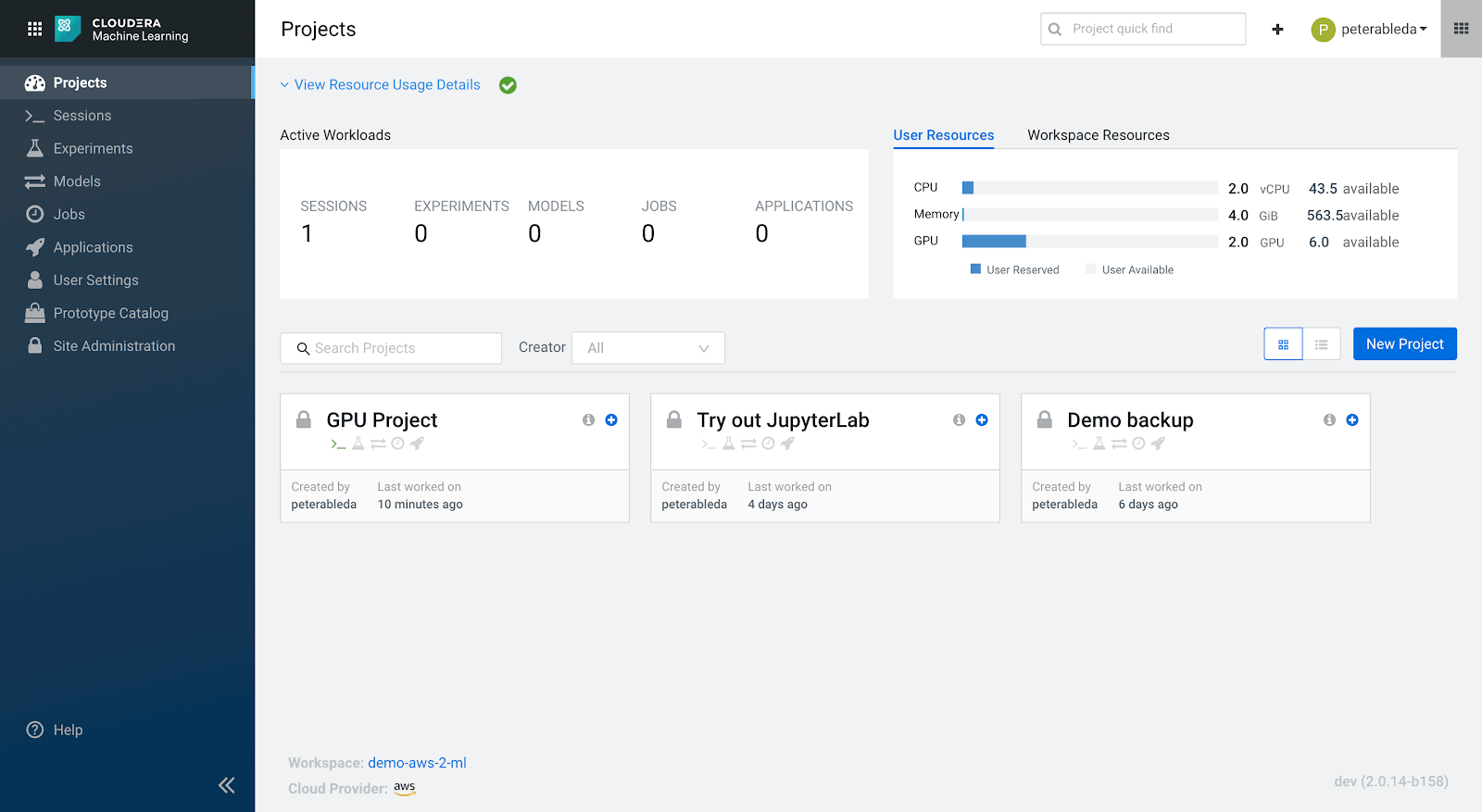
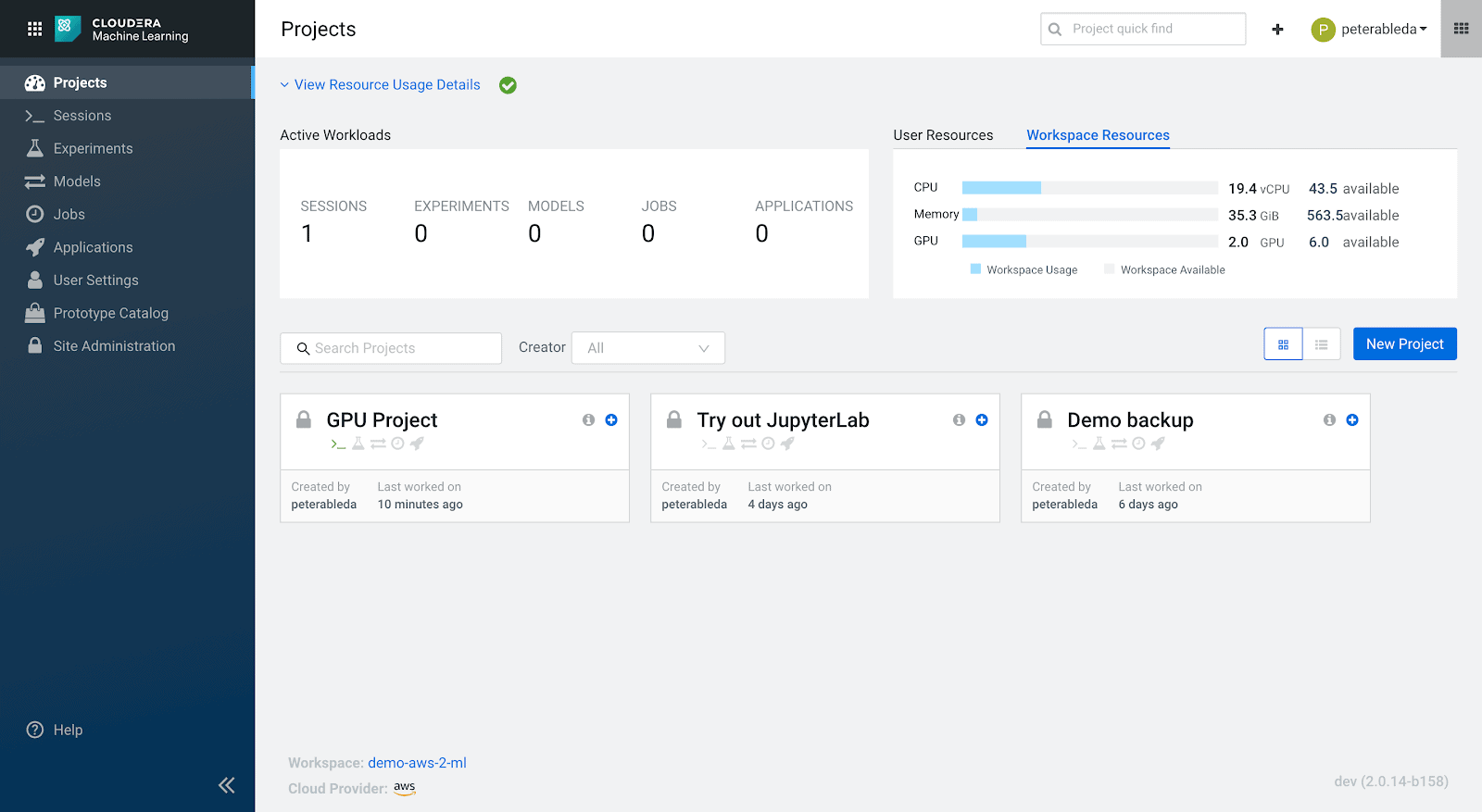
Workspace consumed/available resources:
More to come
In this post, we reviewed how to provision and configure GPUs for Cloudera Machine Learning Workspaces in CDP. Next, we will review different options and building blocks to utilize GPUs end-to-end.
Get started with GPU accelerated Machine Learning in CDP Now, you can start here.
Editor's Choice

