

Support for transparent, end-to-end encryption in HDFS is now available and production-ready (and shipping inside CDH 5.3 and later). Here’s how it works.
Apache Hadoop 2.6 adds support for transparent encryption to HDFS. Once configured, data read from and written to specified HDFS directories will be transparently encrypted and decrypted, without requiring any changes to user application code. This encryption is also end-to-end, meaning that data can only be encrypted and decrypted by the client. HDFS itself never handles unencrypted data or data encryption keys. All these characteristics improve security, and HDFS encryption can be an important part of an organization-wide data protection story.
Cloudera’s HDFS and Cloudera Navigator Key Trustee (formerly Gazzang zTrustee) engineering teams did this work under HDFS-6134 in collaboration with engineers at Intel as an extension of earlier Project Rhino work. In this post, we’ll explain how it works, and how to use it.
Background
In a traditional data management software/hardware stack, encryption can be performed at different layers, each with different pros and cons:
- Application-level encryption is the most secure and flexible one. The application has ultimate control over what is encrypted and can precisely reflect the requirements of the user. However, writing applications to handle encryption is difficult. It also relies on the application supporting encryption, which may rule out this approach with many applications already in use by an organization. If integrating encryption in the application isn’t done well, security can be compromised (keys or credentials can be exposed).
- Database-level encryption is similar to application-level encryption. Most database vendors offer some form of encryption; however, database encryption often comes with performance trade-offs. One example is that indexes cannot be encrypted.
- Filesystem-level encryption offers high performance, application transparency, and is typically easy to deploy. However, it can’t model some application-level policies. For instance, multi-tenant applications might require per-user encryption. A database might require different encryption settings for each column stored within a single file.
- Disk-level encryption is easy to deploy and fast but also quite inflexible. In practice, it protects only against physical theft.
HDFS transparent encryption sits between database- and filesystem-level encryption in this stack. This approach has multiple benefits:
- HDFS encryption can provide good performance and existing Hadoop applications can run transparently on encrypted data.
- HDFS encryption prevents attacks at the filesystem-level and below (so-called “OS-level attacks”). The operating system and disk only interact with encrypted bytes because the data is already encrypted by HDFS.
- Data is encrypted all the way to the client, securing data both when it is at rest and in transit.
- Key management is handled externally from HDFS, with its own set of per-key ACLs controlling access. Crucially, this approach allows a separation of duties: the key administrator does not have to be the HDFS administrator, and acts as another policy evaluation point.
This type of encryption can be an important part of a certification process for industrial or governmental regulatory compliance. And that requirement is important in industries like healthcare (HIPAA), card payment (PCI DSS), and the US government (FISMA).
Design
Securely implementing encryption in HDFS presents some unique challenges. As a distributed filesystem, performance and scalability are primary concerns. Data also needs to be encrypted while being transferred over the network. Finally, as HDFS is typically run as a multi-user system, we need to be careful not to expose sensitive information to other users of the system, particularly admins who might have HDFS superuser access or root shell access to cluster machines.
With transparent encryption being a primary goal, all the above needs to happen without requiring any changes to user application code. Encryption also needs to support the standard HDFS access methods, including WebHDFS, HttpFS, FUSE, and NFS.
Key Management via the Key Management Server
Integrating HDFS with an enterprise keystore, such as Cloudera Navigator Key Trustee, was an important design goal. However, most keystores are not designed for the request rates driven by Hadoop workloads, and also do not expose a standardized API. For these reasons, we developed the Hadoop Key Management Server (KMS).
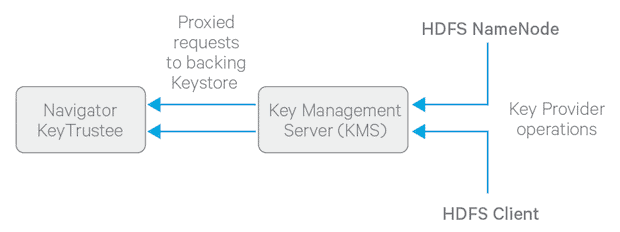
Figure 1: High-level architecture of how HDFS clients and the NameNode interact with an enterprise keystore through the Hadoop Key Management Server
The KMS acts as a proxy between clients on the cluster and a backing keystore, exposing Hadoop’s KeyProvider interface to clients via a REST API. The KMS was designed such that any keystore with the required functionality can be plugged in with a little integration effort.
Note that the KMS doesn’t itself store keys (other than temporarily in its cache). It’s up to the enterprise keystore to be the authoritative storage for keys, and to ensure that keys can never be lost—as a lost key is equivalent to destruction of data. For production use, two or more redundant enterprise key stores should be deployed.
The KMS also supports a range of ACLs that control access to keys and key operations on a granular basis. This feature can be used, for instance, to only grant users access to certain keys, or to restrict the NameNode and DataNode from accessing key material entirely. Information on how to configure the KMS is available in our documentation.
Accessing Data Within an Encryption Zone
This new architecture introduces the concept of an encryption zone (EZ), which is a directory in HDFS whose contents will be automatically encrypted on write and decrypted on read. Encryption zones always start off empty, and renames are not supported into or out of EZs. Consquently, an EZ’s entire contents are always encrypted.

Figure 2: Interaction among encryption zone keys (EZ keys), data encryption keys (DEKs), encrypted data encryption keys (EDEKs), files, and encrypted files
When an EZ is created, the administrator specifies an encryption zone key (EZ Key) that is already stored in the backing keystore. The EZ Key encrypts the data encryption keys (DEKs) that are used in turn to encrypt each file. DEKs are encrypted with the EZ key to form an encrypted data encryption key (EDEK), which is stored on the NameNode via an extended attribute on the file (1).
To encrypt a file, the client retrieves a new EDEK from the NameNode, and then asks the KMS to decrypt it with the corresponding EZ key. This step results in a DEK (2), which the client can use to encrypt their data (3).
To decrypt a file, the client needs to again decrypt the file’s EDEK with the EZ key to get the DEK (2). Then, the client reads the encrypted data and decrypts it with the DEK (4).
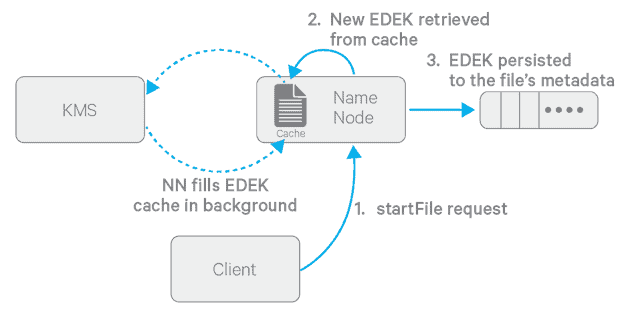
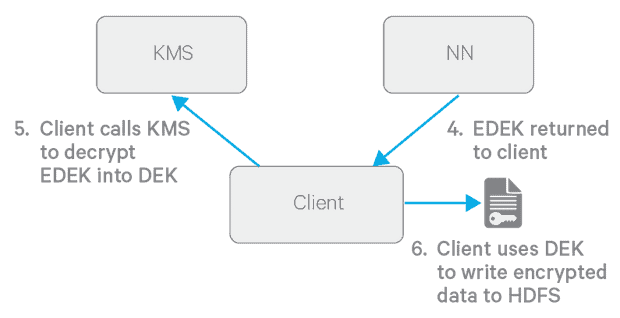
Figures 3 & 4: The flow of events required to write a new file to an encryption zone
The above diagrams describe the process of writing a new encrypted file in more detail. One important detail is the per-EZ EDEK cache on the NameNode, which is populated in the background. This approach obviates having to call the KMS to create a new EDEK on each create call. Furthermore, note that the EZ key is never directly handled by HDFS, as generating and decrypting EDEKs happens on the KMS.
For more in-depth implementation details, please refer to the design document posted on HDFS-6134 and follow-on work at HDFS-6891.
With regard to security, there are a few things worth mentioning:
- First, the encryption is end-to-end. Encryption and decryption happens on the client, so unencrypted data is never available to HDFS and data is encrypted when it is at-rest as well as in-flight. This approach limits the need for the user to trust the system, and precludes threats such as an attacker walking away with DataNode hard drives or setting up a network sniffer.
- Second, HDFS never directly handles or stores sensitive key material (DEKs or EZ keys)—thus compromising the HDFS daemons themselves does not leak any sensitive material. Encryption keys are stored separately on the keystore (persistently) and KMS (cached in-memory). A secure environment will also typically separate the roles of the KMS/keystore administrator and the HDFS administrator, meaning that no single person will have access to all the encrypted data and also all the encryption keys. KMS ACLs will also be configured to only allow end-users access to key material.
- Finally, since each file is encrypted with a unique DEK and each EZ can have a different key, the potential damage from a single rogue user is limited. A rogue user can only access EDEKs and ciphertext of files for which they have HDFS permissions, and can only decrypt EDEKs for which they have KMS permissions. Their ability to access plaintext is limited to the intersection of the two. In a secure setup, both sets of permissions will be heavily restricted.
Configuration and New APIs
Interacting with the KMS and creating encryption zones requires the use of two new CLI commands: hadoop key and hdfs crypto. A fuller explanation is available in our documentation, but here’s a short example snippet for how you might quickly get started on a dev cluster.
As a normal user, create a new encryption key:
$ hadoop key create myKey
As the superuser, create a new empty directory anywhere in the HDFS namespace and make it an encryption zone:
$ sudo -u hdfs hadoop fs -mkdir /zone $ sudo -u hdfs hdfs crypto -createZone -keyName myKey -path /zone
Change its ownership to the normal user:
$ sudo -u hdfs hadoop fs -chown myuser:myuser /zone
As the normal user, put a file in, read it out:
$ hadoop fs -put helloWorld /zone $ hadoop fs -cat /zone/helloWorld
Performance
Currently, AES-CTR is the only supported encryption algorithm and can be used either with a 128- or 256-bit encryption key (when the unlimited strength JCE is installed). A very important optimization was making use of hardware acceleration in OpenSSL 1.0.1e using the AES-NI instruction set, which can be an order of magnitude faster than software implementations of AES. With AES-NI, our preliminary performance evaluation with TestDFSIO shows negligible overhead for writes and only a minor impact on reads (~7.5%) with datasets larger than memory.
The cipher suite was designed to be pluggable. Adding support for additional cipher suites like AES-GCM that provide authenticated encryption is future work.
Conclusion
Transparent encryption in HDFS enables new use cases for Hadoop, particularly in high-security environments with regulatory requirements. This encryption is end-to-end, meaning that data is encrypted both at-rest and in-flight; encryption and decryption can only be done by the client. HDFS and HDFS administrators never have access to sensitive key material or unencrypted plaintext, further enhancing security. Furthermore, when using AES-NI optimizations, encryption imposes only a minor performance overhead on read and write throughput.
Acknowledgements
Transparent encryption for HDFS was developed upstream as part of a community effort involving contributors from multiple companies. The HDFS aspects of this feature were developed primarily by the authors of this blog post: Charles Lamb, Yi Liu, and Andrew Wang. Alejandro Abdelnur was instrumental in overseeing the overall design. Alejandro and Arun Suresh were responsible for implementation of the KMS, as well as encryption-related work within MapReduce. Mat Crocker and Anthony Young-Garner were responsible for integrating Navigator Key Trustee with the KMS.
Charles Lamb is a Software Engineer at Cloudera, primarily working on HDFS.
Yi Liu is a Senior Process Engineer at Intel and a Hadoop committer.
Andrew Wang is a Software Engineer at Cloudera, and a Hadoop committer/PMC member.
Learn more about Project Rhino—work done and work still to be completed—in this live Webinar on Thurs., Jan. 29, at 10am PT.
Editor's Choice

