

Learn how to set up a Hadoop cluster in a way that maximizes successful production-ization of Hadoop and minimizes ongoing, long-term adjustments.
Previously, we published some recommendations on selecting new hardware for Apache Hadoop deployments. That post covered some important ideas regarding cluster planning and deployment such as workload profiling and general recommendations for CPU, disk, and memory allocations. In this post, we’ll provide some best practices and guidelines for the next part of the implementation process: configuring the machines once they arrive. Between the two posts, you’ll have a great head start toward production-izing Hadoop.
Specifically, we’ll cover some important decisions you must make to ensure network, disks, and hosts are configured correctly. We’ll also explain how disks and services should be laid out to be utilized efficiently and minimize problems as your data sets scale.
Networking: May All Your SYNs Be Forgiven
Hostname Resolution, DNS and FQDNs
A Hadoop Java process such as the DataNode gets the hostname of the host on which it is running and then does a lookup to determine the IP address. It then uses this IP to determine the canonical name as stored in DNS or /etc/hosts. Each host must be able to perform a forward lookup on its own hostname and a reverse lookup using its own IP address. Furthermore, all hosts in the cluster need to resolve other hosts. You can verify that forward and reverse lookups are configured correctly using the Linux host command.
$ host `hostname` bp101.cloudera.com has address 10.20.195.121 $ host 10.20.195.121 121.195.20.10.in-addr.arpa domain name pointer bp101.cloudera.com
Cloudera Manager uses a quick Python command to test proper resolution.
$ python -c 'import socket; print socket.getfqdn(), socket.gethostbyname(socket.getfqdn())'
While it is tempting to rely on /etc/hosts for this step, we recommend using DNS instead. DNS is much less error-prone than using the hosts file and makes changes easier to implement down the line. Hostnames should be set to the fully-qualified domain name (FQDN). It is important to note that using Kerberos requires the use of FQDNs, which is important for enabling security features such as TLS encryption and Kerberos. You can verify this with
$ hostname --fqdn bp101.cloudera.com
If you do use /etc/hosts, ensure that you are listing them in the appropriate order.
192.168.2.1 bp101.cloudera.com bp101 master1 192.168.2.2 bl102.cloudera.com bp102 master2
Name Service Caching
Hadoop makes extensive use of network-based services such as DNS, NIS, and LDAP. To help weather network hiccups, alleviate stress on shared infrastructure, and improve the latency of name resolution, it can be helpful to enable the name server cache daemon (nscd). nscd caches the results of both local and remote calls in memory, often avoiding a latent round-trip to the network. In most cases you can enable nscd, let it work, and leave it alone. If you’re running Red Hat SSSD, you’ll need to modify the nscd configuration; with SSSD enabled, don’t use nscd to cache passwd, group, or netgroup information.
Link Aggregation
Also known as NIC bonding or NIC teaming, this refers to combining network interfaces for increased throughput or redundancy. Exact settings will depend on your environment.
There are many different ways to bond interfaces. Typically, we recommend bonding for throughput as opposed to availability, but that tradeoff will depend greatly on the number of interfaces and internal network policies. NIC bonding is one of Cloudera’s highest case drivers for misconfigurations. We typically recommend enabling the cluster and verifying everything work before enabling bonding, which will help troubleshoot any issues you may encounter.
VLAN
VLANs are not required, but they can make things easier from the network perspective. It is recommended to move to a dedicated switching infrastructure for production deployments, as much for the benefit of other traffic on the network as anything else. Then make sure all of the Hadoop traffic is on one VLAN for ease of troubleshooting and isolation.
Operating System (OS)
Cloudera Manager does a good job of identifying known and common issues in the OS configuration, but double-check the following:
IPTables
Some customers disable IPTables completely in their initial cluster setup. Doing makes things easier from an administration perspective of course, but also introduces some risk. Depending on the sensitivity of data in your cluster you may wish to enable IP Tables. Hadoop requires many ports to communicate over the numerous ecosystem components but our documentation will help navigate this.
SELinux
It is challenging to construct an SELinux policy that governs all the different components in the Hadoop ecosystem, and so most of our customers run with SELinux disabled. If you are interested in running SELinux make sure to verify that it is on a supported OS version. We recommend only enabling permissive mode initially so that you can capture the output to define a policy that meets your needs.
Swappiness
The traditional recommendation for worker nodes was to set swappiness (vm.swappiness) to 0. However, this behavior changed in newer kernels and we now recommend setting this to 1. (This post has more details.)
$ sysctl vm.swappiness=1 $ echo "vm.swappiness = 1" >> /etc/sysctl.conf
Limits
The default file handle limits (aka ulimits) of 1024 for most distributions are likely not set high enough. Cloudera Manager will fix this issue, but if you aren’t running Cloudera Manager, be aware of this fact. Cloudera Manager will not alter users’ limits outside of Hadoop’s default limits. Nevertheless, it is still beneficial to raise the global limits to 64k.
Transparent Huge Pages (THP)
Most Linux platforms supported by CDH 5 include a feature called Transparent Huge Page compaction, which interacts poorly with Hadoop workloads and can seriously degrade performance. Red Hat claims versions past 6.4 patched this bug but there are still remnants that can cause performance issues. We recommend disabling defrag until further testing can be done.
Red Hat/CentOS: /sys/kernel/mm/redhat_transparent_hugepage/defrag
Ubuntu/Debian, OEL, SLES: /sys/kernel/mm/transparent_hugepage/defrag
$ echo 'never' > defrag_file_pathname
**Remember to add this to your /etc/rc.local file to make it reboot persistent.**
Time
Make sure you enable NTP on all of your hosts.
Storage
Properly configuring the storage for your cluster is one of the most important initial steps. Failure to do so correctly will lead to pain down the road as changing the configuration can be invasive and typically requires a complete redo of the current storage layer.
OS, Log Drives and Data Drives
Typical 2U machines come equipped with between 16 and 24 drive bays for dedicated data drives, and some number of drives (usually two) dedicated for the operating system and logs. Hadoop was designed with a simple principle: “hardware fails.” As such, it will sustain a disk, node, or even rack failure. (This principle really starts to take hold at massive scale but let’s face it: if you are reading this blog, you probably aren’t at Google or Facebook.)
Even at normal-person scale (fewer than 4,000 nodes), Hadoop survives hardware failure like a boss but it makes sense to build in a few extra redundancies to reduce these failures. As a general guideline, we recommend using RAID-1 (mirroring) for OS drives to help keep the data nodes ticking a little longer in the event of losing an OS drive. Although this step is not absolutely necessary, in smaller clusters the loss of one node could lead to a significant loss in computing power.
The other drives should be deployed in a JBOD (“Just a Bunch Of Disks”) configuration with individually mounted ext4 partitions on systems running RHEL6+, Debian 7.x, or SLES11+. In some hardware profiles, individual RAID-0 volumes must be used when a RAID controller is mandatory for that particular machine build. This approach will have the same effect as mounting the drives as individual spindles.
There are some mount options that can be useful. These are covered well in Hadoop Operations and by Alex Moundalexis, but echoed here.
Root Reserved Space
By default, both ext3 and ext4 reserve 5% of the blocks on a given filesystem for the root user. This reserve isn’t needed for HDFS data directories, however, and you can adjust it to zero when creating the partition or after using mkfs and tune2fs respectively.
$ mkfs.ext4 -m 0 /dev/sdb1 $ tune2fs -m 0 /dev/sdb1
File Access Time
Linux filesystems maintain metadata that records when each file was last accessed—thus, even reads result in a write to disk. This timestamp is called atime and should be disabled on drives configured for Hadoop. Set it via mount option in /etc/fstab:
/dev/sdb1 /data1 ext4 defaults,noatime 0
and apply without reboot.
mount -o remount /data1
Directory Permissions
This is a minor point but you should consider changing the permissions on your directories to 700 before you mount data drives. Consequently, if the drives become unmounted, the processes writing to these directories will not fill up the OS mount.
LVM, RAID or JBOD
We are frequently asked whether a JBOD configuration, RAID configuration, or LVM configuration is required. The entire Hadoop ecosystem was created with a JBOD configuration in mind. HDFS is an immutable filesystem that was designed for large file sizes with long sequential reads. This goal plays well with stand-alone SATA drives, as they get the best performance with sequential reads. In summary, whereas RAID is typically used to add redundancy to an existing system, HDFS already has that built in. In fact, using a RAID system with Hadoop can negatively affect performance.
Both RAID-5 and RAID-6 add parity bits into the RAID stripes. These parity bits have to be written and read during standard operations and add significant overhead. Standalone SATA drives will write/read continuously without having to worry about the parity bits since they don’t exist. In contrast, HDFS takes advantage of having numerous individual mount points and can allow individual drives/volumes to fail before the node goes down—which is HDFS’s not-so secret sauce for parallelizing I/O. Setting the drives up in RAID-5 or RAID-6 arrays will create a single array or a couple very large arrays of mount points depending on the drive configuration. These RAID arrays will undermine HDFS’s natural promotion of data protection, slower sequential reads, and data locality of Map tasks.
RAID arrays will also affect other systems that expect numerous mount points. Impala, for example, spins up a thread per spindle in the system, which will perform favorably in a JBOD environment vs. a large single RAID group. For the same reasons, configuring your Hadoop drives under LVM is neither necessary nor recommended.
Deploying Heterogeneously
Many customers purchase new hardware in regular cycles; adding new generations of computing resources makes sense as data volumes and workloads increase. For such environments containing heterogeneous disk, memory, or CPU configurations, Cloudera Manager allows Role Groups, which allow the administrator to specify memory, YARN containers, and Cgroup settings per node or per groups of nodes.
While Hadoop can certainly run with mixed hardware specs, we recommend keeping worker-node configurations homogenous, if possible. In distributed computing environments, workloads are distributed amongst nodes and optimizing for local data access is preferred. Nodes configured with fewer computing resources can become a bottleneck, and running with a mixed hardware configuration could lead to a wider variation in SLA windows. There are a few things to consider:
- Mixed spindle configuration – HDFS block placement by default works in a round-robin fashion across all the directories specified by
dfs.data.dir. If you have, for example, a node with six 1.2TB drives and six 600GB drives, you will fill up the smaller drives more quickly, leading to volume imbalance. Using the Available Space policy requires additional configuration, and in this scenario I/O bound workloads could be affected as you might only be writing to a subset of your disks. Understand the implications of deploying drives in this fashion in advance. Furthermore, if you deploy nodes with more overall storage, remember that HDFS balances by percentage. - Mixed memory configuration – Mixing available memory in worker nodes can be problematic as it does require additional configuration.
- Mixed CPU configuration – Same concept; jobs can be limited by the slowest CPU, effectively negating the benefits of running updated/more cores.
It is important to be cognizant of the points above but remember that Cloudera Manager can help with allocating resources to different hosts; allowing you to easily manage and optimize your configuration.
Cloudera Manager Like A Boss
We highly recommend using Cloudera Manager to manage your Hadoop cluster. Cloudera Manager offers many valuable features to make life much easier. The Cloudera Manager documentation is pretty clear on this but in order to stamp out any ambiguity, below are the high-level steps to do a production-ready Hadoop deployment with Cloudera Manager.
- Set up an external database and pre-create the schemas needed for your deployment.
create database amon DEFAULT CHARACTER SET utf8; grant all on amon.* TO 'amon'@'%' IDENTIFIED BY 'amon_password'; create database rman DEFAULT CHARACTER SET utf8; grant all on rman.* TO 'rman'@'%' IDENTIFIED BY 'rman_password'; create database metastore DEFAULT CHARACTER SET utf8; grant all on metastore.* TO 'metastore'@'%' IDENTIFIED BY 'metastore_password'; create database nav DEFAULT CHARACTER SET utf8; grant all on nav.* TO 'nav'@'%' IDENTIFIED BY 'nav_password'; create database sentry DEFAULT CHARACTER SET utf8; grant all on sentry.* TO 'sentry'@'%' IDENTIFIED BY 'sentry_password';
(Please change the passwords in the examples above!)
- Install the cloudera-manager-server and cloudera-manager-daemons packages per documentation.
yum install cloudera-manager-server cloudera-manager-daemons
- Run the
scm_prepare_database.shscript specific to your database type./usr/share/cmf/schema/scm_prepare_database.sh mysql -h cm-db-host.cloudera.com -utemp -ptemp --scm-host cm-db-host.cloudera.com scm scm scm
- Start the Cloudera Manager Service and follow the wizard from that point forward.
This is the simplest way to install Cloudera Manager and will get you started with a production-ready deployment in under 20 minutes.
You Play It Out: Services Layout Guide
Given a Cloudera Manager-based deployment, the diagrams below present a rational way to lay out service roles across the cluster in most configurations.
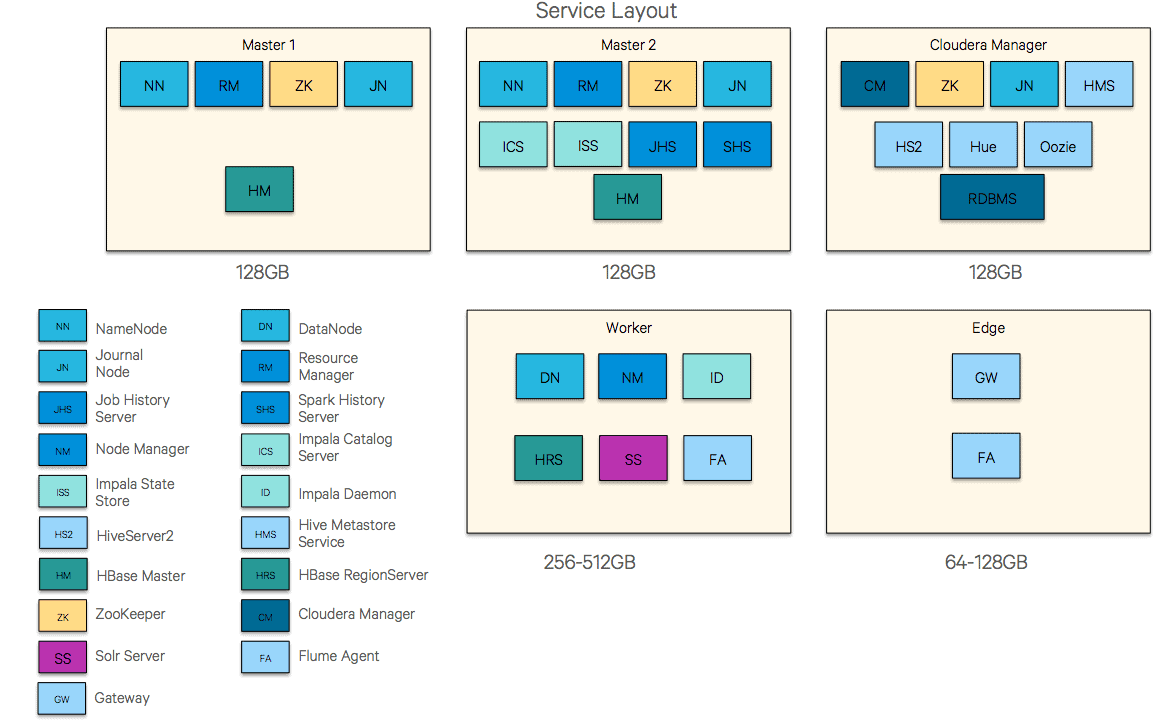
In larger clusters (50+ nodes), a move to five management nodes might be required, with dedicated nodes for the ResourceManager and NameNode pairs. Further, it is not uncommon to use an external database for Cloudera Manager, the Hive Metastore, and so on, and additional HiveServer2 or HMS services could be deployed as well.
We recommend 128GB per management node and 256-512GB for worker nodes. Memory is relatively inexpensive and as computation engines increasingly rely on in-memory execution the additional memory will be put to good use.
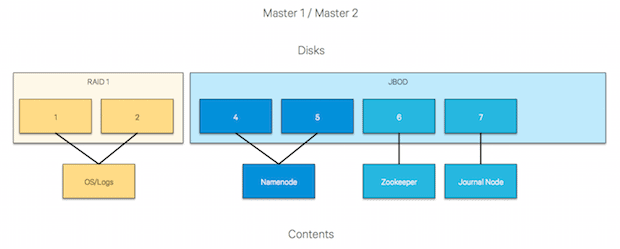
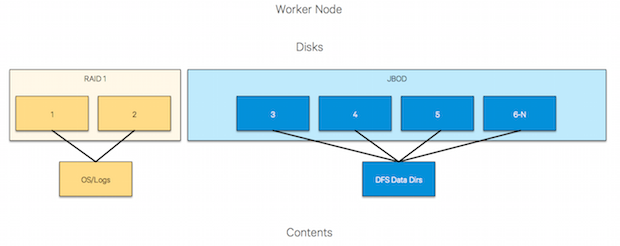
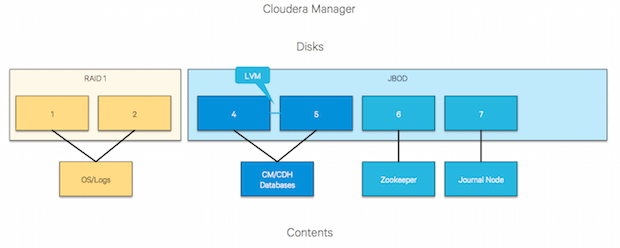
Diving a little deeper, the following charts depict the appropriate disk mappings to the various service storage components.
We specify the use of an LVM here for the Cloudera Manager databases but RAID 0 is an option, as well.
Conclusion
Setting up a Hadoop cluster is relatively straightforward once armed with the appropriate knowledge. Take the extra time to procure the right infrastructure and configure it correctly from the start. Following the guidelines described above will give you the best chance for success in your Hadoop deployment and you can avoid fussing with configuration, allowing you to focus your time on solving real business problems—like a boss.
Look for upcoming posts on security and resource management best practices.
Jeff Holoman and Kevin O’Dell are System Engineers at Cloudera.
Editor's Choice

