

This blog post was written by Guest Blogger Li Cheng, Software Engineer, Tencent Inc.
Using Hadoop-Ozone in Prod
Apache Hadoop-Ozone is a new-era object storage solution for Big Data platform. It is scalable with strong consistency. Ozone uses Raft protocol, implemented by Apache Ratis (Incubating), to achieve high availability in its distributed system.
My team in Tencent started to introduce Ozone as a backend object storage in production a few months ago and we’re onboarding more and more data warehouse users. We observed that Ozone with a singular Ratis pipeline per datanode was not able to saturate the disk bandwidth resulting in some variability in write latency..
Ozone leverages Raft protocol for data replication and global consistency. Apache Ratis is basically an implementation of Raft protocol and provides consistent writes among DataNodes. Ozone wraps a Raft group made up of datanodes (= replication factor, default is 3) as a Ratis pipeline. Before Ozone 0.5.0, Ozone allows each datanode to participate in only one Ratis pipeline(raft group) only.
In this article, we will go through our investigation on the performance of Single-Raft based Ratis pipeline and how the latest Multi-Raft based Ratis pipeline added in Ozone-0.5.0 can significantly boost the write performance.
Writing performance issue with single-raft
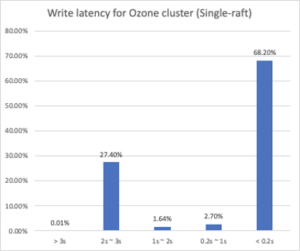
Our internal Ozone cluster has all HDD-disk physical machines with 10Gps network and each node equips 12 data disks. The upstream user is writing Hive SQL query results as files into the Ozone cluster through Ozone S3 gateways. The incoming files’ sizes vary from several bytes to gigabytes. Due to this variance of input sizes, we plot the distribution of latency in seconds. Some large file writes (GB) were filtered out to avoid noise.
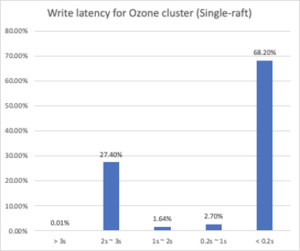
From the diagram, over 68% of writes finish within 0.2 seconds. However, what’s concerning is there are over 20% writes that can only finish in 2-3 seconds. As we take a closer look, the files that are written in 2-3 seconds have different sizes from B to MB.
Then we took a look at a DataNode’s disk usage.
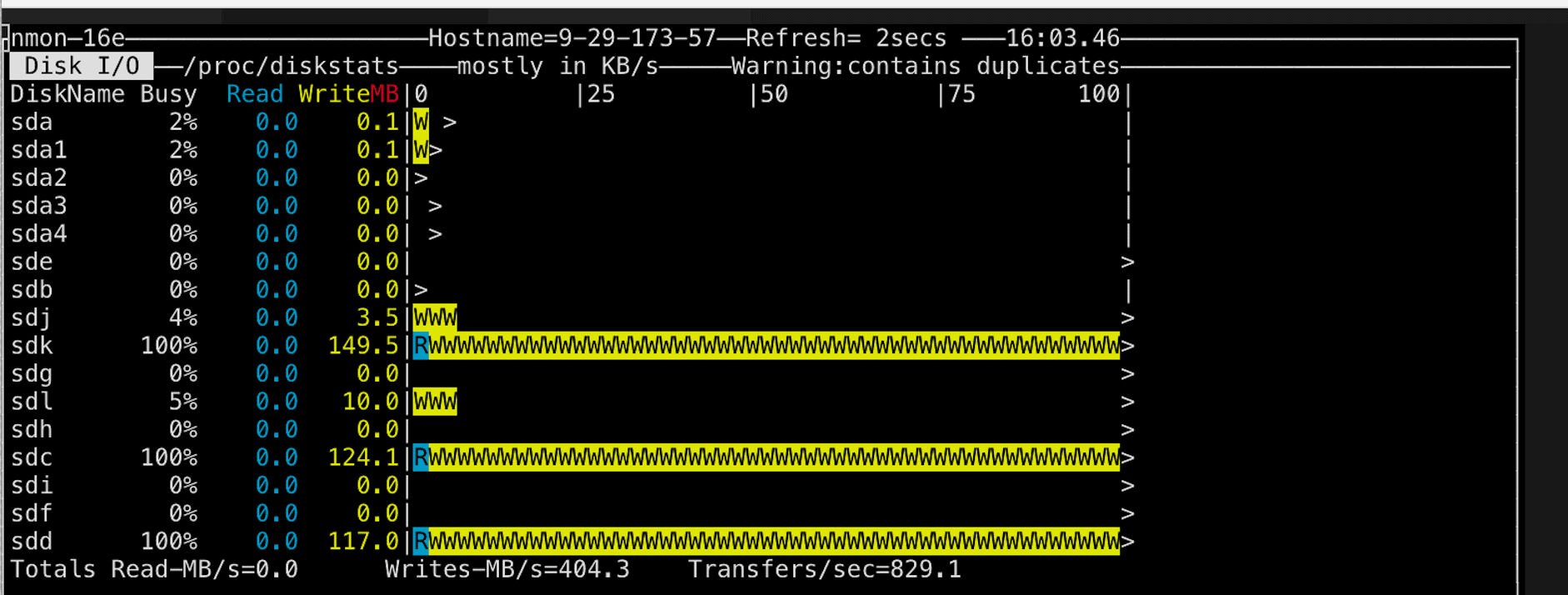
Each of our DataNodes has configured 10 HDD disks for storage. Only 4 of them are being used, while 3 of them are fully busy. It looks like our DataNodes are not efficiently used.Above analysis makes us believe that there should be queued up writes which would result in this diversity. Therefore, in order to improve the writing performance on each DataNode, Ozone cluster needs to have better disk usage.
Ozone write path
Ozone has 3 major components, Ozone Manager (OM), Storage Container Manager (SCM) and DataNodes (DN). SCM manages containers, pipelines and other metadata in RocksDB. DataNodes send SCM reports and heartbeat for communication. Ozone stores data in a vast number of containers throughout the cluster and each container allocates data blocks on DataNodes. In order to manage all the containers, Ozone creates pipelines, as logic groups, to assemble containers from several DataNodes for redundancy purposes.
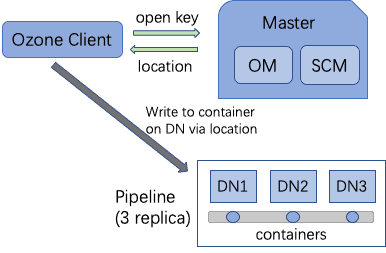
Therefore, pipelines are taking charge of Ozone’s writing path from client requests all the way to disks on DataNodes. Behind the scene, pipelines use Raft protocol to create a raft group with one elected leader.. Ozone supports three-replica mode so that there are 3 DataNodes for every pipeline created and one of them is leader. Through the pipeline, data is written into the leader DataNode and it replicates data to followers. This design helps Ozone to widely spread write traffic onto the entire cluster.
As a result, Ozone’s writing performance has a lot to do with how good pipelines are balancing the writing load onto disks on DataNodes. Pipeline takes advantage of RaftLog (a WAL implementation in Raft) to spread the write load on disks. In theory, there are two major factors to Ozone writing performance:
- more pipelines available to accelerate containers access for better bandwidth
- how efficient disks on nodes are being utilized.
What is multi-Raft and how it helps
Ozone’s pipelines are using Raft protocol for replication from leader to followers DataNodes. It starts off only allowing each DataNode to join one pipeline. For example, with 10 nodes, Ozone cluster would be deployed as 1 master and 9 DataNodes, which leads to 3 three-replica pipelines. If we try to make pipelines and containers more available, you may think of throwing in more nodes. However, the number has to be exactly a multiple of replication factor, otherwise the remainder of nodes (upto 2 for factor = 3) are unused for the write pipeline. . Knowing that, we start to think about evolving the pipeline-to-DataNodes mapping from one-to-multiple to multiple-to-multiple so that pipelines can have overlapped DataNodes. This actually adds up the pipeline number exponentially.
Here comes the multi-Raft feature which can let every DataNode be involved in multiple pipelines. Multi-Raft means every DataNode would have multiple Raft pipelines spread up RaftLog’s writing on every disk. Once we also configure all the disks to be RaftLog directories, these multi-Raft pipelines will be way more efficient on disk usage since the load on disks will be more spread up with more containers. With multi-Raft, every DataNode is likely to be the leader in a pipeline while being a follower at other pipelines. It could also balance out the network load.
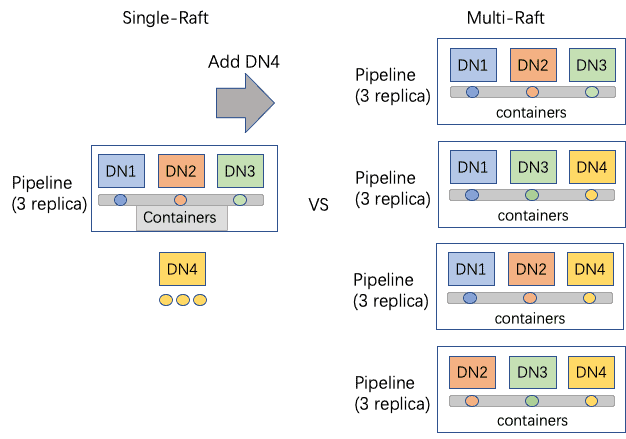
Adding DataNode 4 into a 3-DataNode multi-Raft cluster can make SCM create (4-1) = 3 more pipelines and every DataNode could join 3 pipelines, letting alone single-Raft can only leave the DN4 as a backup. Load limit of how many pipelines each DataNode is also set. Once any DataNode exceeds the load limit, the background thread ceases to create pipelines.
Given N DataNodes and load limit M, single-Raft creates N/3 pipelines while multi-Raft creates (M*N)/3 pipelines. Multi-Raft cluster’s container usage rate is also up to M times more.
With that, the Ozone cluster can stop the system from overflowing pipelines, which is mostly unnecessary creation.
Rack awareness for data pipelines
Rack awareness is also thrown in the pipeline placement policy so that pipelines would prefer to choose DataNodes on different network racks. This would help data locality of containers and ultimately helps Ozone IO throughput once the cluster gets large and spreads up on many racks.
Multi-Raft pipeline allocation is going to allocate two nodes from the same rack and one node from a different rack to have balance between data locality and data isolation for better durability. Also, multi-Raft is also balancing pipeline allocation load throughout all nodes to let every node join the same amount of pipelines.
Conclusions and some stats
Multi-Raft feature achieves 3 major goals, which eventually boost up Ozone writing performance:
- Be able to increase the containers and pipelines availability without costing more machines or disks, which are more efficient.
- Enhance IO bandwidth by better load balancing on disk IO as well as network.
- Better utilization of DataNodes without ‘wasting’ any machine in pipeline allocation.
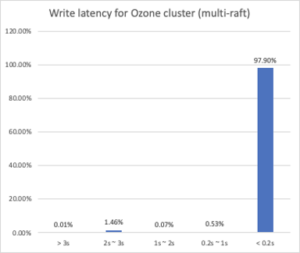
In our internal cluster, we collected some results from our user’s write traffic after multi-Raft is enabled.
When the cluster turns on multi-Raft, around 98% writes can finish within 0.2 seconds, which is 30% more than it does in single-Raft cluster.
We also did some benchmark stats for comparison.
Cluster setup:
9 physical machines, each with 10 HDD disks. 1 as the master. 8 as datanodes.
- Long-running latency comparison
Client writes to Ozone S3 gateway with all 100KB files flat.
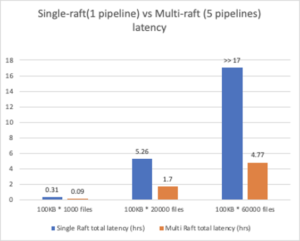
From this diagram, we can tell the multi-Raft cluster reduced writing latency to around 1/3 of the single-Raft cluster.
Not only that, it is able to finish larger scale writing which single-Raft cluster may not be able to finish
*Note that with the given test setup, a single node pipeline took 17 hours to write 60K 100 KB files.
- Disk usage measurement.
Use testDFSIO to write 1GB * 1000 file with Hadoop tasks. Writing concurrency at 90.
1 pipeline vs many pipelines
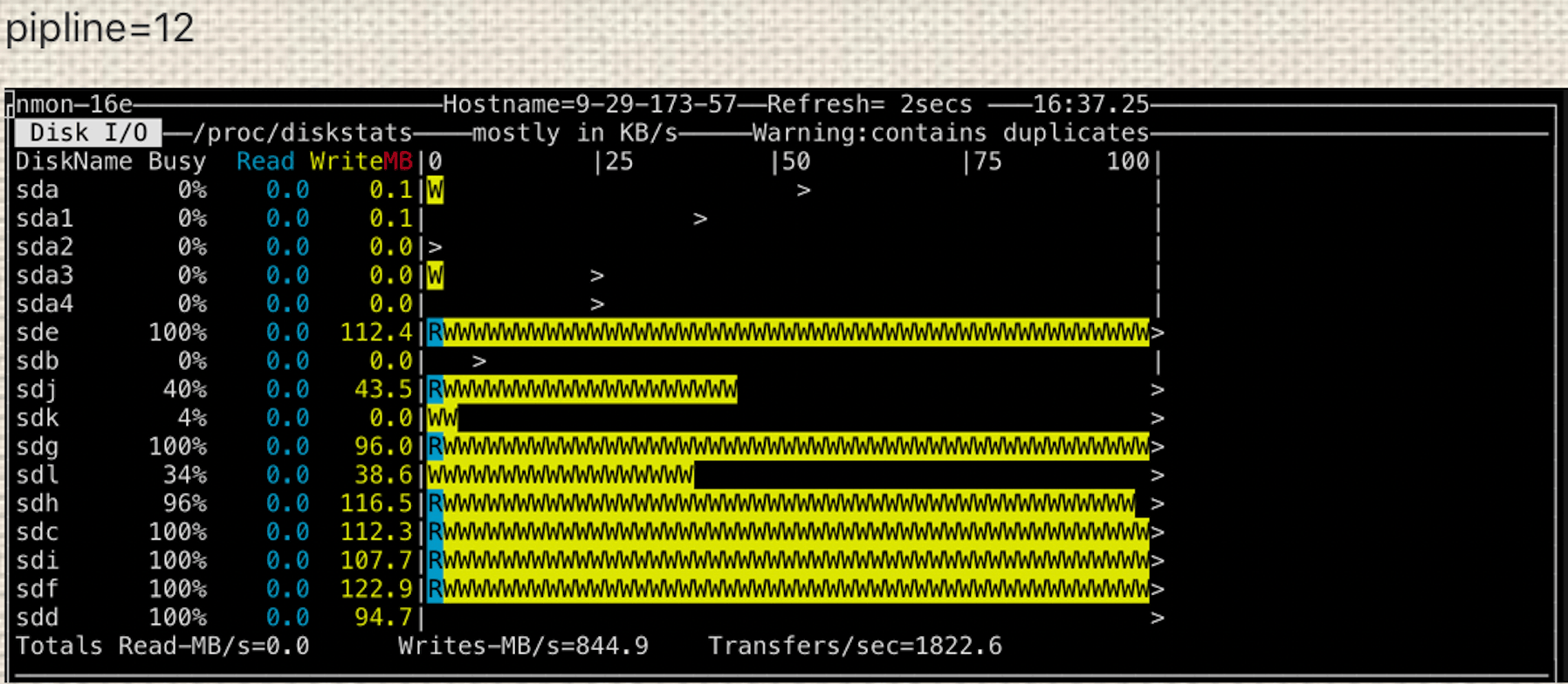
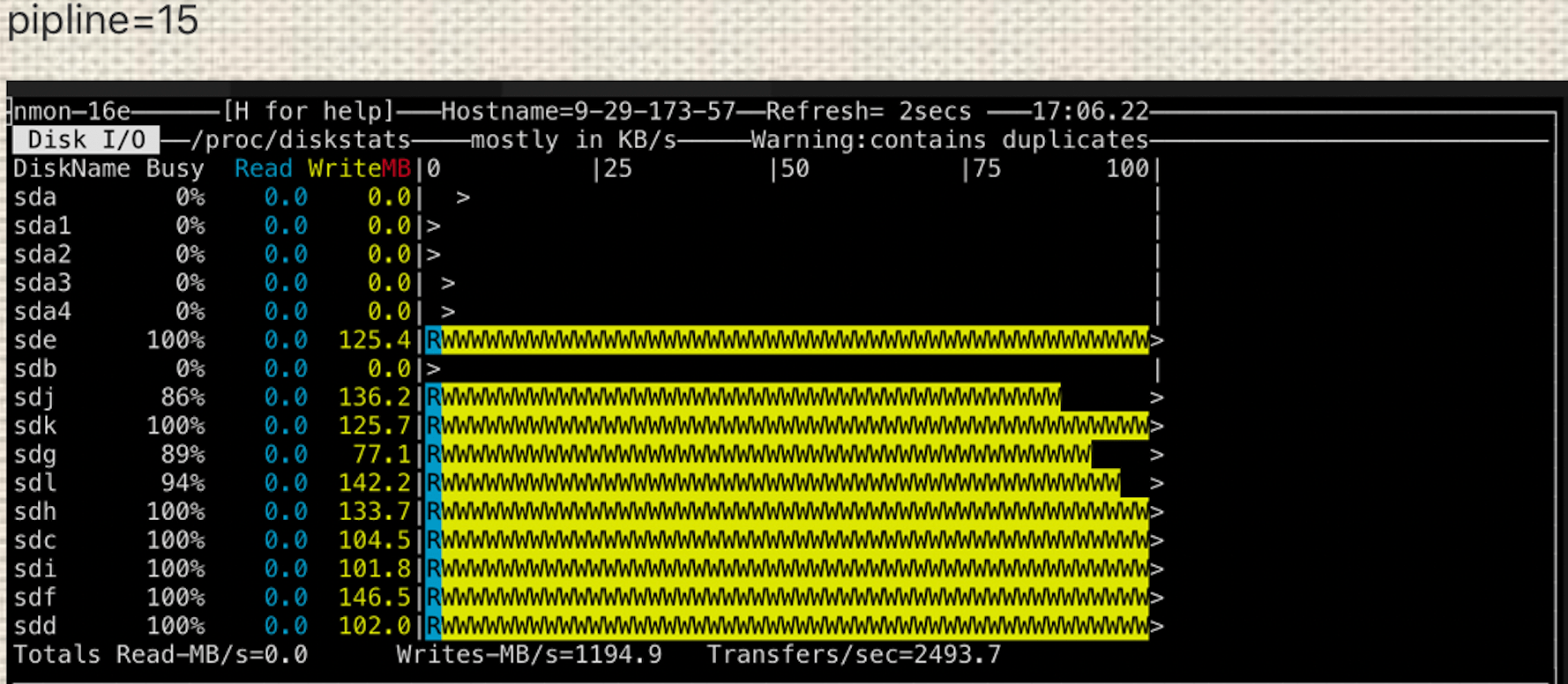
Starting from single-Raft, disk usage is still not even with 1 pipeline. As multi-Raft is enabled, we start to see some improvements with 12 pipelines (ozone.datanode.pipeline.limit is 4). The disk is overloaded when it comes to 15 pipelines (ozone.datanode.pipeline.limit is 5). Note that no more machines are added.
Multi-Raft is able to leverage all disks up for Ratis RaftLog to write to.
Acknowledgments
As multi-Raft feature successfully enhances Ozone’s writing performance, we especially want to thank Apache Hadoop-Ozone community for help on the work.
Big thanks to Xiaoyu Yao, Sid Wagle, Jitendra Pandey from Cloudera and Sammi Chen, Jerry Shao, Junping Du from Tencent as their contributions and guidance to finish this feature work!
More improvements to come
There are some ideas to further improve the multi-Raft impact on Ozone:
- Make Ozone recommend the DataNode leader to Ratis so that leaders can be more evenly spread up.
- Add ability in SCM to decide the best number of pipelines for each DataNode by taking several configurations into account, like number of DataNodes, number of disks, Ratis client’s retry policy and connection time, etc…
- If some DataNodes have upgraded the disks, multi-Raft should also find an algorithm to adjust to it and make the best out of the machines.
User guidance and Appendix
In order to turn on multi-Raft feature, you just need to add ozone.datanode.pipeline.limit into your ozone-site.xml configuration as in Ozone setup guide and set a preferable number for your cluster (more than default value: 2). We also recommend to config all hard disks and maybe reduce some ratis client retry counts so that single connection won’t get stuck for too long. Next up, we will make SCM decide the pipeline load limit by collecting different stats in the Ozone system. Therefore, users can enjoy the best writing performance brought out by multi-Raft without worrying about any configuration.
For your reference, config names are:
| Config | description | default value |
| ozone.datanode.pipeline.limit | Load limit per DataNode to join pipelines.
If ozone.datanode.pipeline.limit=4, multi-raft will try to create up to 3 Ratis-three pipeline and 1 Ratis-one pipeline |
2 // multi-raft is disabled by default. The default setting allows 1 Ratis three pipeline and 1 Ratis one pipeline per node. |
| ozone.scm.ratis.pipeline.limit | Load limit of pipeline number for the entire Ozone system.
Not necessary if ozone.datanode.pipeline.limit is set. |
0 // no upper limit by default. |
| dfs.container.ratis.datanode.storage.dir | RaftLog dir | //(set local disk dir. More disks could have better Ratis IO performance. Recommend to set as many independent disk paths (mount points) as pipeline number so that each pipeline can have independent disks to write.) |
| dfs.ratis.client.request.max.retries | Ratis client max retry counts | 180// Recommend to decrease retry counts if you see slow Ratis IO. |
Sample configs: <property> <name>ozone.datanode.pipeline.limit</name> <value>5</value> <tag>OZONE, SCM, PIPELINE</tag> <description>Max number of pipelines per datanode can be engaged in.</description> </property> <property> <name>ozone.scm.ratis.pipeline.limit</name> <value>0</value> <tag>OZONE, SCM, PIPELINE</tag> <description>Upper limit for how many pipelines can be OPEN in SCM. 0 as default means there is no limit. Otherwise, the number is the limit of max amount of pipelines which are OPEN. </description> </property> <property> <name>dfs.container.ratis.datanode.storage.dir</name> <value>/data1/ratis,/data2/ratis,/data3/ratis,/data4/ratis,/data5/ratis</value> <tag>OZONE, OM, SCM, CONTAINER, STORAGE, REQUIRED</tag> </property> <property> <name>dfs.ratis.client.request.max.retries</name> <value>180</value> <tag>OZONE, RATIS, MANAGEMENT</tag> <description>Number of retries for ratis client request.</description> </property>
Editor's Choice


Nice!
Very informative article. Is there a publication linking to it. I would really like to read into more detail about this topic.