

The release of ChatGPT pushed the interest in and expectations of Large Language Model based use cases to record heights. Every company is looking to experiment, qualify and eventually release LLM based services to improve their internal operations and to level up their interactions with their users and customers.
At Cloudera, we have been working with our customers to help them benefit from this new wave of innovation. In the first article of this series, we are going to share the challenges of Enterprise adoption and propose a possible path to embrace these new technologies in a safe and controlled manner.
Powerful LLMs can cover diverse topics, from providing lifestyle advice to informing the design of transformer architectures. However, enterprises have much more specific needs. They need the answers for their enterprise context. For example, if one of your employees asks the expense limit on her lunch while attending a conference, she will get into trouble if the LLM doesn’t have access to the specific policy your company has put out. Privacy concerns loom large, as many enterprises are cautious about sharing their internal knowledge base with external providers to safeguard data integrity. This delicate balance between outsourcing and data protection remains a pivotal concern. Moreover, the opacity of LLMs amplifies safety worries, especially when the models lack transparency in terms of training data, processes, and bias mitigation.
The good news is that all enterprise requirements can be achieved with the power of open source. In the following section, we are going to walk you through our newest Applied Machine Learning Prototype (AMP), “LLM Chatbot Augmented with Enterprise Data”. This AMP demonstrates how to augment a chatbot application with an enterprise knowledge base to be context aware, doing this in a way that lets you deploy privately anywhere even in an air gapped environment. Best of all, the AMP was built with 100% open source technology.
The AMP deploys an Application in CML that produces two different answers, the first one using only the knowledge base the LLM was trained on, and a second one that’s grounded in Cloudera’s context.
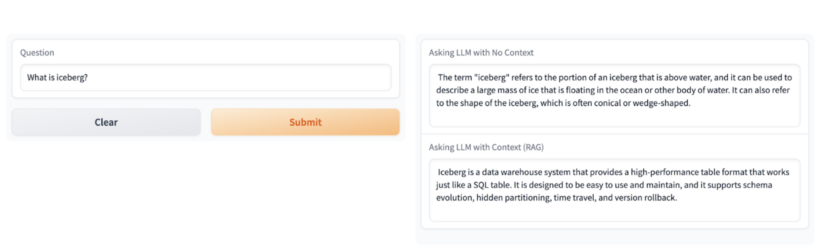
For example, when you ask “What is Iceberg?” The first answer is a factual response explaining an iceberg as a big block of ice floating in water. For most people this is a valid answer but if you are a data professional, iceberg is something completely different. For those of us in the data world, Iceberg more often than not refers to an open source high-performance table format that’s the foundation of the Open Lakehouse.
In the following section, we will cover the key details of the AMP implementation.
LLM AMP
AMPs are pre-built, end-to-end ML projects specifically designed to kickstart enterprise use cases. In Cloudera Machine Learning (CML), you can select and deploy a complete ML project from the AMP catalog with a single click.
All AMPs are open source and available on GitHub, so even if you don’t have access to Cloudera Machine Learning you can still access the project and deploy it on your laptop or other platform with some tweeks.
Once you deploy, the AMP executes a series of steps to configure and provision everythings to complete the end-to-end use case. In the next few sections we will go through the main steps in this process.
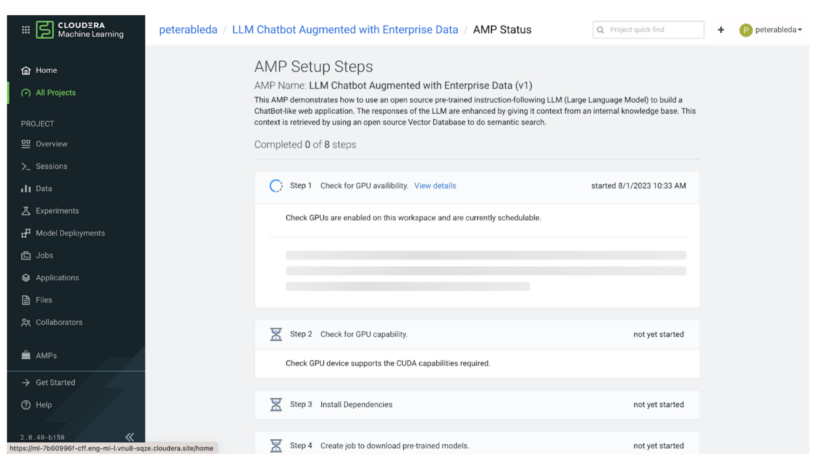
In steps 1 and 2 the AMP executes a series of checks to guarantee that the environment has the necessary compute resources to host this use case. The AMP is built with state of the art open source LLM technology and requires at least 1 NVIDIA GPU with CUDA compute capability 5.0 or higher. (i.e., V100, A100, T4 GPUs).
Once the AMP confirms that the environment has the required compute resources, it proceeds with Project Setup. In Step 3, the AMP installs the dependencies from the requirements.txt file like transformers and then in steps 4 and 5 it downloads the configured models from HuggingFace. The AMP uses a sentence-transformer model to map text to a high-dimensional vector space (embedding), enabling the execution of similarity searches and an H2O model as the question answering LLM.
Steps 6 and 7 perform the ETL portion of the prototype. During these steps, the AMP populates a Vector DB with an enterprise knowledge base as embeddings for semantic search.

This is not strictly part of the AMP but worth noting that the quality of the AMP’s Chatbot responses will heavily depend on the quality of the data that it is given for context. Thus it is essential that you organize and clean your knowledge base to ensure high quality responses from the Chatbot.
For the knowledge base the AMP uses pages from the Cloudera documentation, then it chunks and loads that data to an open source embedding model (the one that was downloaded in the previous steps) and inserts the embeddings to a Milvus Vector Database.
Step 8 completes the prototype by deploying the user facing chatbot application. The below image shows the two answers that the chatbot application produces, one with and one without enterprise context.

Once the application receives a question it first, following the red path, passes the question to the Open Source Instruction-Tuned LLM to generate an answer.
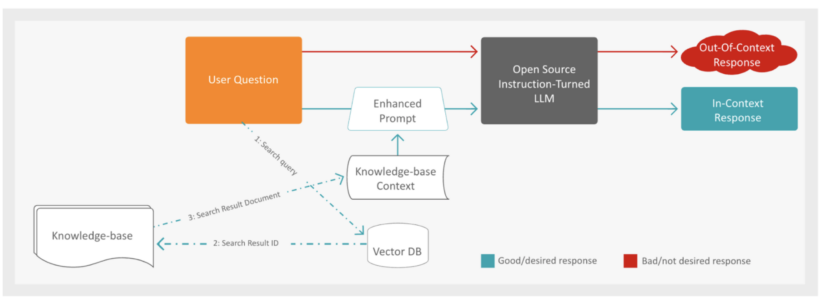
The process of RAG (Retrieval-Augmented Generation) for generating a factual response to a user question involves several steps. First, the system augments the user’s question with additional context from a knowledge base. To achieve this, the Vector Database is searched for documents that are semantically closest to the user’s question, leveraging the use of embeddings to find relevant content.
Once the closest documents are identified, the system retrieves the context by using the document IDs and embeddings obtained in the search response. With the enriched context, the next step is to submit an enhanced prompt to the LLM to generate the factual response. This prompt includes both the retrieved context and the original user question.
Finally, the generated response from the LLM is presented to the user through a web application, providing a comprehensive and accurate answer to their inquiry. This multi-step approach ensures a well-informed and contextually relevant response, enhancing the overall user experience.
After all the above steps are completed, you have a fully functioning end-to-end deployment of the prototype.
Ready to deploy the LLM AMP chatbot and enhance your user experience?
Head to Cloudera Machine Learning (CML) and access the AMP catalog. With just a single click, you can select and deploy the complete project, kickstarting your use case effortlessly. Don’t have access to CML? No worries! The AMP is open-source and available on GitHub. You can still deploy it on your laptop or other platforms with minimal tweaks. Visit the GitHub repository here.
If you want to learn more about the AI solutions that Cloudera is delivering to our customers, come check out our Enterprise AI page.
In the next article of this series, we’ll delve into the art of customizing the LLM AMP to suit your organization’s specific needs. Discover how to integrate your enterprise knowledge base seamlessly into the chatbot, delivering personalized and contextually relevant responses. Stay tuned for practical insights, step-by-step guidance, and real-world examples to empower your AI use cases.
Editor's Choice

