



Apache Impala and Apache Kudu make a great combination for real-time analytics on streaming data for time series and real-time data warehousing use cases. More than 200 Cloudera customers have implemented Apache Kudu with Apache Spark for ingestion and Apache Impala for real-time BI use cases successfully over the last decade, with thousands of nodes running Apache Kudu. These use cases have varied from telecom 4G/5G analytics to real-time oil and gas reporting and alerting, to supply chain use cases for pharmaceutical companies or core banking and stock trading analytics systems.
The multitude of use cases that Apache Kudu can serve is driven by its performance, a columnar C++ backed storage engine that enables data to be ingested and served within seconds of ingestion. Along with its speed, consistency, and atomicity, Apache Kudu also supports transactional properties for updates and deletes, enabling use cases that traditionally write once and read multiple times, something distributed file systems were unable to support. Apache Impala is a distributed C++ backed SQL engine that integrates with Kudu to serve BI results over millions of rows meeting sub-second service-level agreements.
Cloudera offers Apache Kudu to run in Real Time DataMart Clusters, and Apache Impala to run in Kubernetes in the Cloudera Data Warehouse form factor. With a scalable Impala running in CDW, customers wanted a way to connect CDW to Kudu service in DataHub clusters. In this blog we will explain how to integrate them together to achieve separation of compute (i.e. Impala) and storage (i.e. Kudu). Customers can scale up both layers independently to handle workloads as per demand. This also enables advanced scenarios where customers can connect multiple CDW Virtual Clusters to different real-time data mart clusters to connect to a Kudu cluster specific for their workloads.
Configuration Steps
Prerequisites
- Create a Kudu DataHub cluster of version 7.2.15 or later
- Ensure CDW environment is upgraded to 1.6.1-b258 or later release with run time 2023.0.13.20
- Create a Impala virtual warehouse in CDW
Step 1: Get Kudu Master Node Details
1-Login to CDP, navigate to Data Hub Clusters, and select the Kudu Real Time Data Mart cluster that you want to query from CDW.
2-Click on the cluster details and use the “Nodes” tab to capture the details of the three Kudu master nodes as shown below.
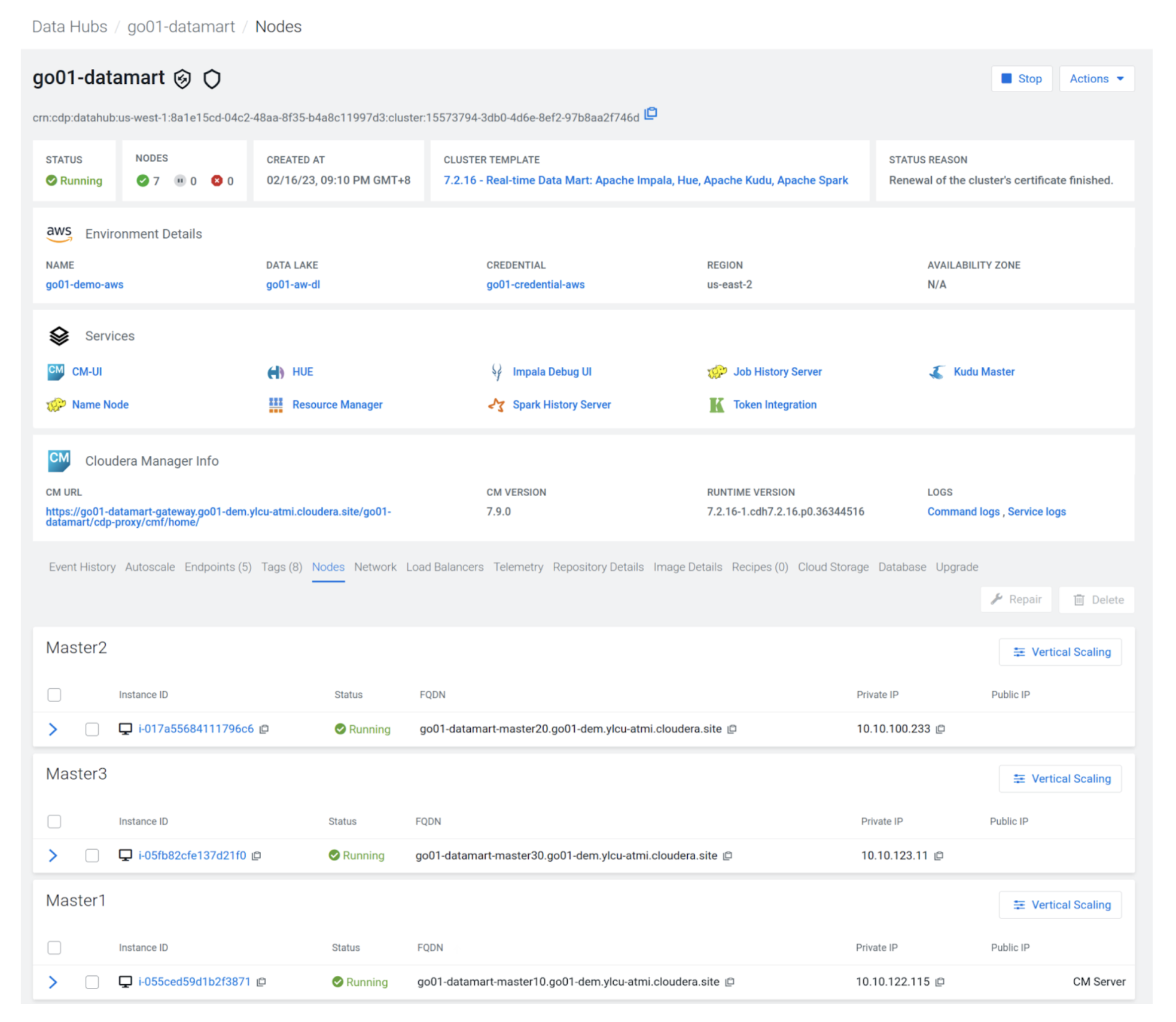
In the below example the master nodes are:
- go01-datamart-master20.go01-dem.ylcu-atmi.cloudera.site
- go01-datamart-master30.go01-dem.ylcu-atmi.cloudera.site
- Go01-datamart-master10.go01-dem.ylcu-atmi.cloudera.site
Step 2: Configure CDW Impala Virtual Warehouse
1- Navigate to CDW and select the Impala virtual warehouse that you wish to configure to work with Kudu in a real-time data mart cluster. Click “Edit” and navigate to the configuration page. Ensure that the Impala VW version is 2023.0.13-20 or higher.
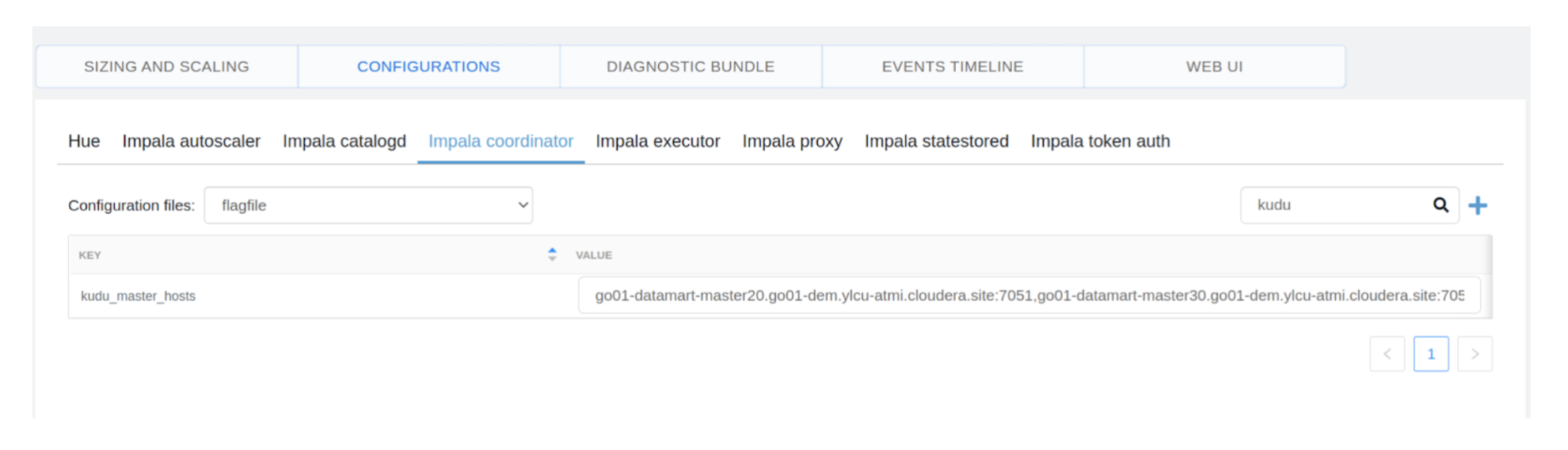
2- Select the Impala coordinator flag file configuration to edit as shown below:
3- Search for “kudu_master_hosts” configuration and edit the value to the below:
Go01-datamart-master20.go01-dem.ylcu-atmi.cloudera.site:7051 ,go01-datamart-master30.go01-dem.ylcu-atmi.cloudera.site:7051, go01-datamart-master10.go01-dem.ylcu-atmi.cloudera.site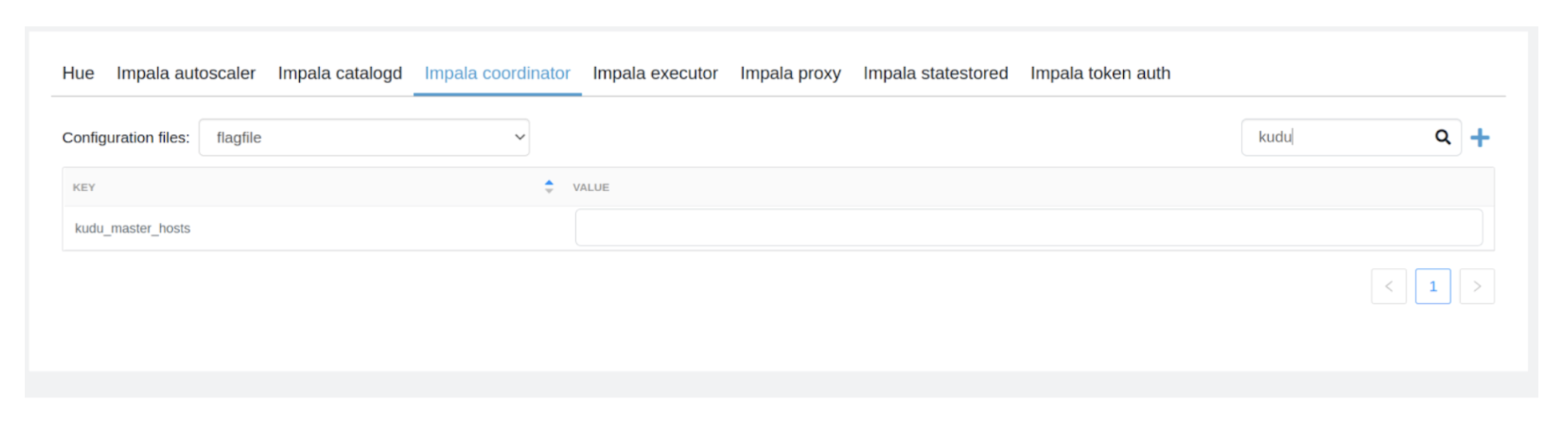
4- If the “kudu_master_hosts” configuration is not found then click the “+” icon and the configuration as below:
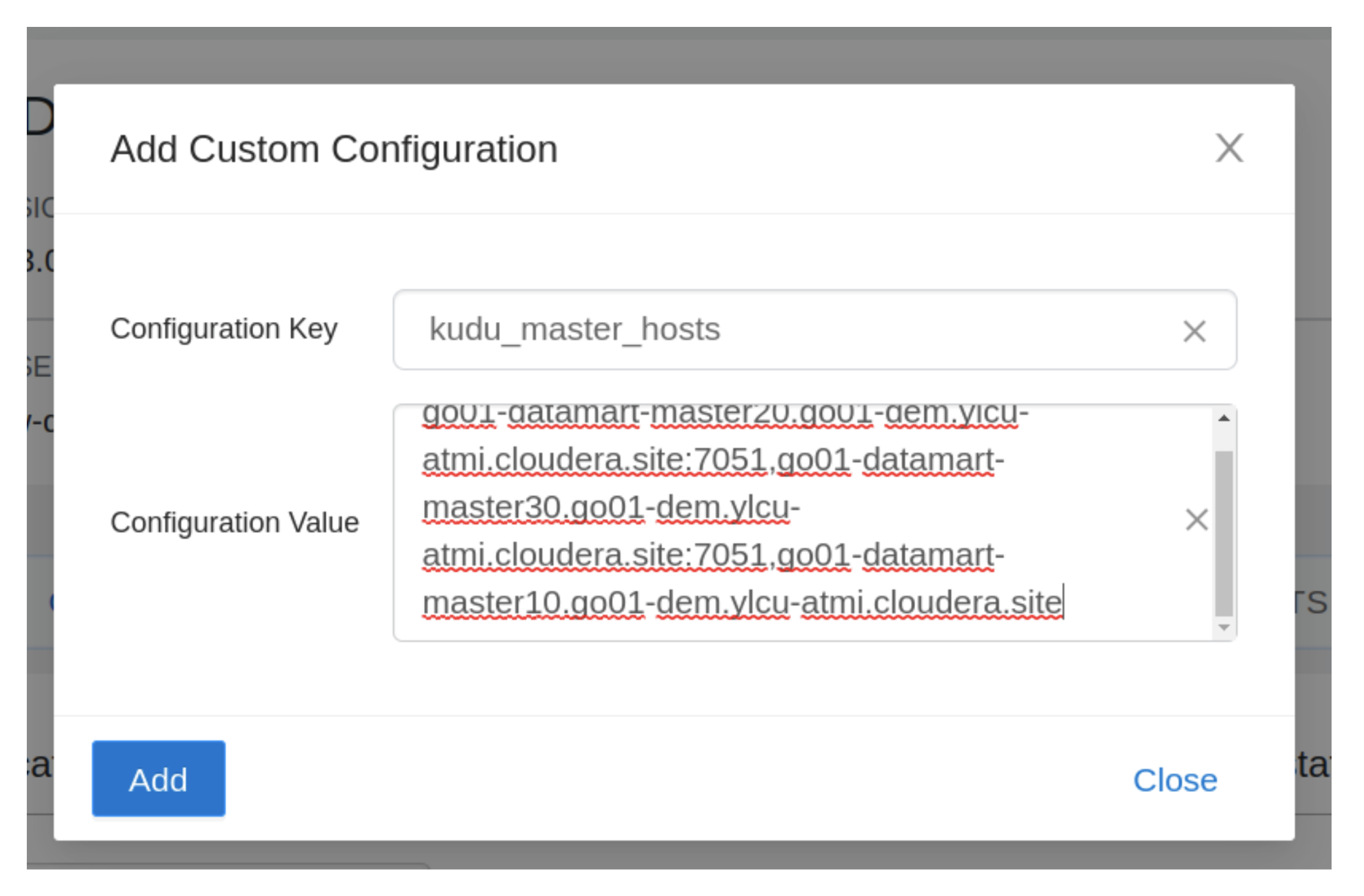
5- Click on “apply changes” and wait for the VW to restart.
Step 3: Run Queries on Kudu Tables
Once the virtual warehouse finishes updating, you can query Kudu tables from Hue, an Impala shell, or an ODBC/JDBC client as shown below:

Summary
With CDW and Kudu DataHub integration you are now able to scale up your compute resources on demand and dedicate the DataHub resources to only running Kudu. Running Kudu queries from an Impala virtual warehouse provides benefits, such as isolation from noisy neighbors, auto-scaling, and autosuspend.
You can also potentially use Cloudera Data Engineering to ingest data into Kudu DH cluster, thereby using the DH cluster just for storage. Advanced users can also use the TBLPROPERTIES to set the Kudu cluster details to query data from any Kudu DH cluster of choice.

Among other features with this integration you also are able to use latest CDW features like:
- JWT authentication in CDW Impala.
- Using a single Impala service for object store and Kudu tables that makes it easy for end users/BI tools to not have to configure more than one Impala service.
- Scale up and out Kudu in DH, only when you run out of space. Eventually you can also stop running Impala in a real-time DM template and just use CDW Impala to query Kudu in DH.
What’s Next
- For complete setup guide refer to CDW documentation on this topic. To know more about Cloudera Data Warehouse please click here.
- If you are interested in chatting about Cloudera Data Warehouse (CDW) + Kudu in CDP, please reach out to your account team.
Editor's Choice


Your blog is comprehensive and well-written, as it addresses almost every facet of the skills that will be in high demand. Integrating Cloudera Data Warehouse with Kudu clusters elevates data management, enhancing analytics and insights with seamless synergy.