

Iceberg is an emerging open-table format designed for large analytic workloads. The Apache Iceberg project continues developing an implementation of Iceberg specification in the form of Java Library. Several compute engines such as Impala, Hive, Spark, and Trino have supported querying data in Iceberg table format by adopting this Java Library provided by the Apache Iceberg project.
Different query engines such as Impala, Hive, and Spark can immediately benefit from using Apache Iceberg Java Library. A range of Iceberg table analysis such as listing table’s data file, selecting table snapshot, partition filtering, and predicate filtering can be delegated through Iceberg Java API instead, obviating the need for each query engine to implement it themself. However, Iceberg Java API calls are not always cheap.
In this blog, we will discuss performance improvement that Cloudera has contributed to the Apache Iceberg project in regards to Iceberg metadata reads, and we’ll showcase the performance benefit using Apache Impala as the query engine. However, other query engines such as Hive and Spark can also benefit from this Iceberg improvement as well.
Repeated metadata reads problem in Impala + Iceberg
Apache Impala is an open source, distributed, massively parallel SQL query engine. There are two components of Apache Impala: back end executor and front end planner. The Impala back end executor is written in C++ to provide fast query execution. On the other hand, Impala front end planner is written in Java and is in charge of analyzing SQL queries from users and planning the query execution. During query planning, Impala front end will analyze table metadata such as partition information, data files, and statistics to come up with an optimized execution plan. Since the Impala front end is written in Java, Impala can directly analyze many aspects of the Iceberg table metadata through the Java Library provided by Apache Iceberg project.
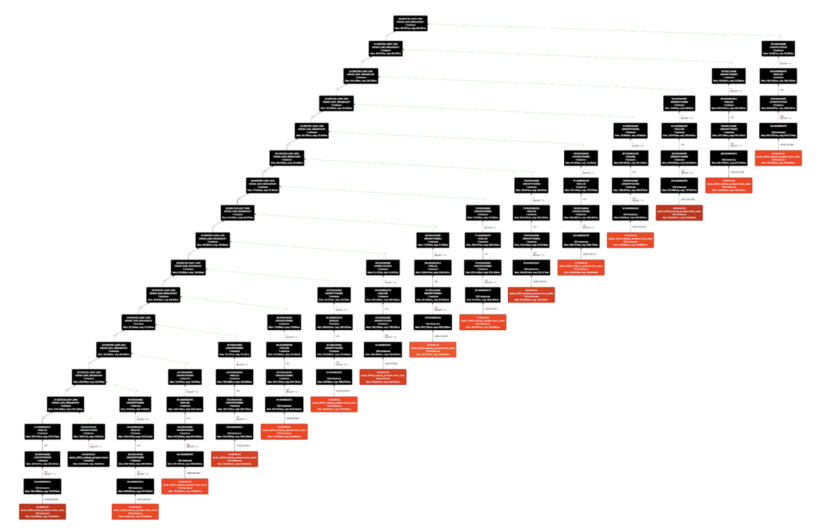
Figure 1. store_sales table scanned 15 times with varying filter predicates in TPC-DS Q9
In Hive table format, the table metadata such as partition information and statistics are stored in Hive Metastore (HMS). Impala can access Hive table metadata fast because HMS is backed by RDBMS, such as mysql or postgresql. Impala also caches table metadata in CatalogD and Coordinator’s local catalog, making table metadata analysis even faster if the targeted table metadata and files were previously accessed. This caching is important for Impala since it may analyze the same table multiple times across concurrent query planning and also within single query planning. Figure 1 shows a TPC-DS Q9 plan where one common table, store_sales, is analyzed 15 times to plan 15 separate table scan fragments.
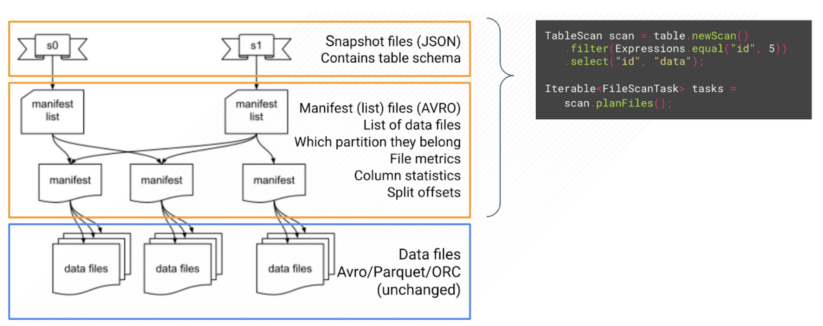
Figure 2. Iceberg table metadata reads by Iceberg Java API
In contrast, Iceberg table format stores its metadata as a set of files in the file system, next to the data files. Figure 2 illustrates the three kinds of metadata files: snapshot files, manifest list, and manifest files. The data files and metadata files in Iceberg format are immutable. New DDL/DML operation over the Iceberg table will create a new set of files instead of rewriting or replacing prior files. Every table metadata query through Iceberg Java API requires reading a subset of these metadata files. Therefore, each of them also incurs an additional storage latency and network latency overhead, even when some of them are analyzing the same table. This problem is described in IMPALA-11171.
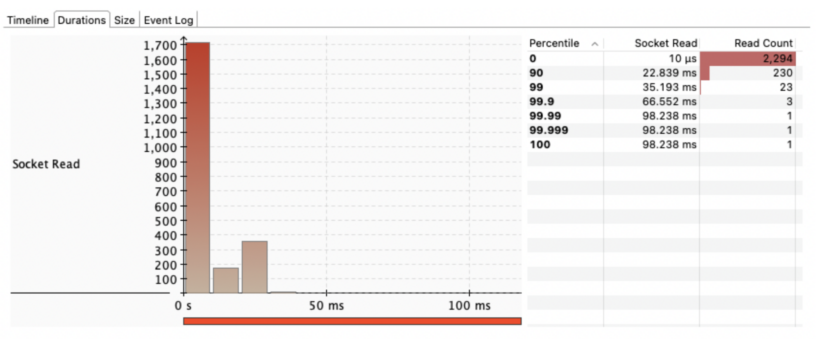
Figure 3. Multiple socket read activities during TPC-DS Q9 planning over Iceberg table on S3.
Iceberg manifest file cache design
Impala front end must be careful in using Iceberg Java API while still maintaining fast query planning performance. Reducing the multiple remote reads of Iceberg metadata files requires implementing similar caching strategies as Impala does for Hive table format, either in Impala front end side or embedded in Iceberg Java Library. Ultimately, we opt to do the latter so we can contribute something that is useful for the whole community and all of the compute engines can benefit from it. It is also important to implement such a caching mechanism as less intrusive as possible.
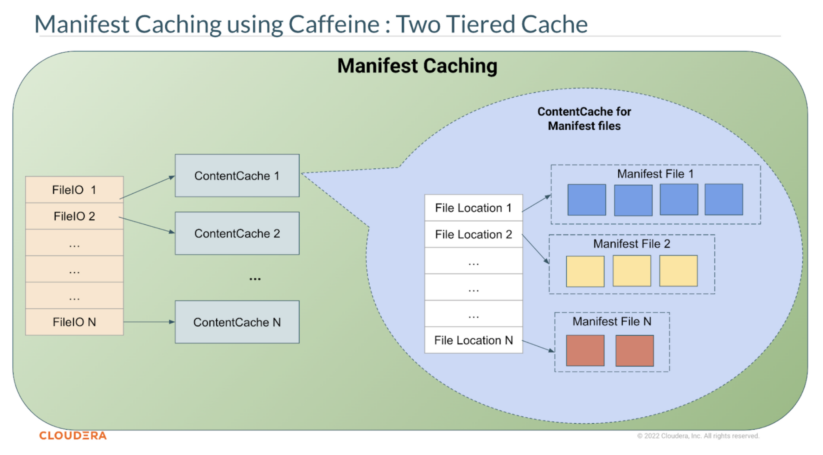
Figure 4. Iceberg manifest caching design.
We filed pull request 4518 in the Apache Iceberg project to implement this caching mechanism. The idea is to cache the binary content of manifest files (the lowest of Iceberg metadata files hierarchy) in memory, and let Iceberg Java Library read from the memory if it exists instead of reading again from the file system. This is made possible by the fact that Iceberg metadata files, including the manifest files, are immutable. If an Iceberg table evolves, new manifest files will be written instead of modifying the old manifest files. Thus, Iceberg Java Library will still read any new additional manifest files that it needs from the file system, populating manifest cache with new content and expiring the old ones in the process.
Figure 4 illustrates the two-tiered design of the Iceberg manifest cache. The first tier is the FileIO level cache, mapping a FileIO into its own ContentCache. FileIO itself is the primary interface between the core Iceberg library and underlying storage. Any file read and write operation by the Iceberg library will go through the FileIO interface. By default, this first tier cache has a maximum of eight FileIO that can simultaneously have ContentCache entries in memory. This amount can be increased through Java system properties iceberg.io.manifest.cache.fileio-max.
The second tier cache is the ContentCache object, which is a mapping of file location path to the binary file content of that file path. The binary file content is stored in memory as a ByteBuffer of 4MB chunks. Both of the tiers are implemented using the Caffeine library, a high-performance caching library that is already in use by Iceberg Java Library, with a combination of weak keys and soft values. This combination allows automatic cache entries elimination on the event of JVM memory pressure and garbage collection of the FileIO. This cache is implemented in the core Iceberg Java Library (ManifestFiles.java), making it available for immediate use by different FileIO implementations without changing their code.
Impala Coordinator and CatalogD can do a fast file listing and data file pruning over an Iceberg table using this Iceberg manifest cache. Note that Iceberg manifest caching does not eliminate the role of CatalogD and Coordinator’s local catalog. Some table metadata such as table schema, file descriptors, and block locations (for HDFS backed tables) are still cached inside CatalogD. Together, CatalogD cache and Iceberg manifest cache help achieve fast query planning in Impala.
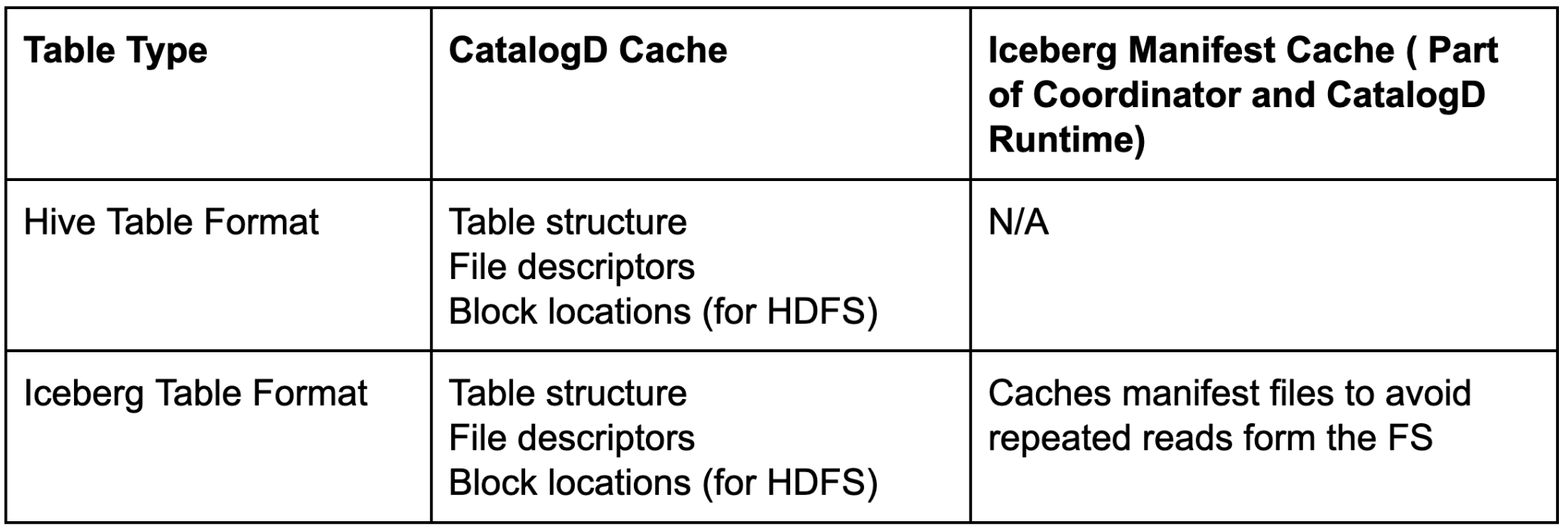
Table 1. CatalogD and Iceberg Manifest Cache role across table formats.
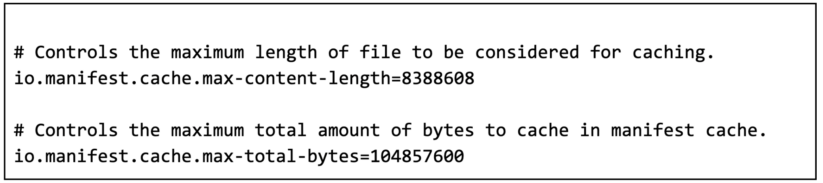
Individual per-FileIO ContentCache can be tuned through their respective Iceberg Catalog properties. The description and default values for each properties are following:

Performance improvement in Impala
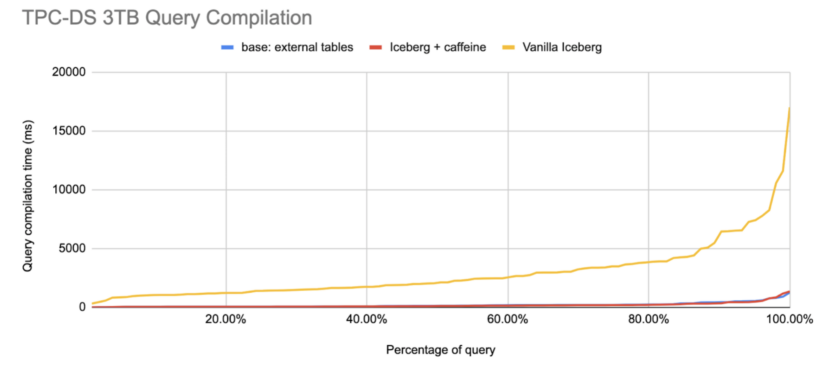
Figure 5. Inverse CDF of Impala query compilation time over TPC-DS queries 3TB scale
Impala and other query engines can leverage the manifest caching feature starting from Apache Iceberg version 1.1.0. Figure 5 shows the improvement in compilation time by Impala front end. The x-axis represents the percentage of queries in TPC-DS workload, and the y-axis represents the query compilation time in milliseconds. Compared to Iceberg without manifest caching (Vanilla Iceberg), enabling Iceberg manifest caching can improve query compilation 12 times faster (Iceberg + caffeine), almost matching the performance over the Hive external table. One caveat is that, in Impala, the io.manifest.cache.expiration-interval-ms config is increased higher to one hour in Coordinator. This is beneficial for Impala because for the default Hive catalog, Impala front end maintains a singleton of Iceberg’s HiveCatalog that is long lived. Setting a long expiration is fine since Iceberg files are immutable, as explained in the design section above. A long expiration time will also allow cache entries to live longer and be utilized for multiple query planning targeting the same tables.
Impala currently reads its default Iceberg catalog properties from core-site.xml. To enable Iceberg manifest caching with a one hour expiration interval, set the following configuration in Coordinator and CatalogD service core-site.xml:
 Summary
Summary
Apache Iceberg is an emerging open-table format designed for large analytic workloads. The Apache Iceberg project continues developing the Iceberg Java Library, which has been adopted by many query engines such as Impala, Hive, and Spark. Cloudera has contributed the Iceberg manifest caching feature to Apache Iceberg to reduce repeated manifest file reads problems. We showcase the benefit of Iceberg manifest caching by using Apache Impala as the query engine, and show that Impala is able to gain up to 12 times speedup in query compilation time on Iceberg tables with Iceberg manifest caching enabled.
To learn more:
- For more on Iceberg manifest caching configuration in In Cloudera Data Warehouse (CDW), please refer to https://docs.cloudera.com/cdw-runtime/cloud/iceberg-how-to/topics/iceberg-manifest-caching.html.
- Watch our webinar Supercharge Your Analytics with Open Data Lakehouse Powered by Apache Iceberg. It includes a live demo recording of Iceberg capabilities.
Try Cloudera Data Warehouse (CDW), Cloudera Data Engineering (CDE), and Cloudera Machine Learning (CML) by signing up for a 60 day trial, or test drive CDP. If you are interested in chatting about Apache Iceberg in CDP, let your account team know.
Editor's Choice

