




Since we announced the general availability of Apache Iceberg in Cloudera Data Platform (CDP), Cloudera customers, such as Teranet, have built open lakehouses to future-proof their data platforms for all their analytical workloads. Cloudera partners are also benefiting from Apache Iceberg in CDP. For example, Modak Nabu is helping their enterprise customers accelerate data ingestion, curation, and consumption at petabyte scale. Today, we are thrilled to share some new advancements in Cloudera’s integration of Apache Iceberg in CDP to help accelerate your multi-cloud open data lakehouse implementation.
Multi-cloud deployment with CDP public cloud
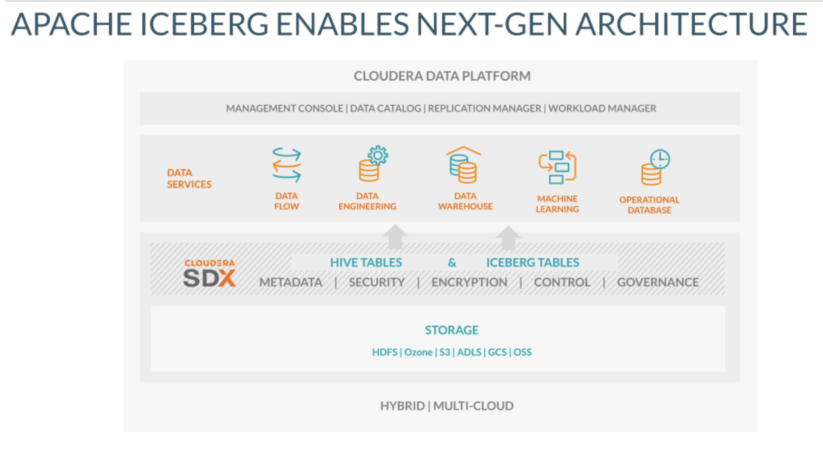
Multi-cloud capability is now available for Apache Iceberg in CDP. According to a recent Gartner survey of public cloud users, 81% of organizations are working with two or more public cloud providers. With CDP, customers can deploy storage, compute, and access, all with the freedom offered by the cloud, avoiding vendor lock-in and taking advantage of best-of-breed solutions. You can leverage Kubernetes (K8s) and containerization technologies to consistently deploy your applications across multiple clouds including AWS, Azure, and Google Cloud, with portability to write once, run anywhere, and move from cloud to cloud with ease. With a common interface in CDP that works across different cloud service providers, you can break down data silos while ensuring consistent security, governance, and traceability, all while seamlessly moving your Apache Iceberg–based workloads across deployment environments frictionlessly.
Advanced capabilities
The new capabilities of Apache Iceberg in CDP enable you to accelerate multi-cloud open lakehouse implementations.
- Enhanced multi-function analytics
In addition to key data services in CDP, such as Cloudera Data Warehousing (CDW), Cloudera Data Engineering (CDE), and Cloudera Machine Learning (CML) already in use by our customers, we integrated Cloudera Data Flow (CDF) and Cloudera Stream Processing (CSP) with the Apache Iceberg table format, so that you can seamlessly handle streaming data at scale. Compute engines in these CDP data services can access and process data sets in the Iceberg tables concurrently, with shared security and governance provided by our unique Cloudera Shared Data Experience (SDX).
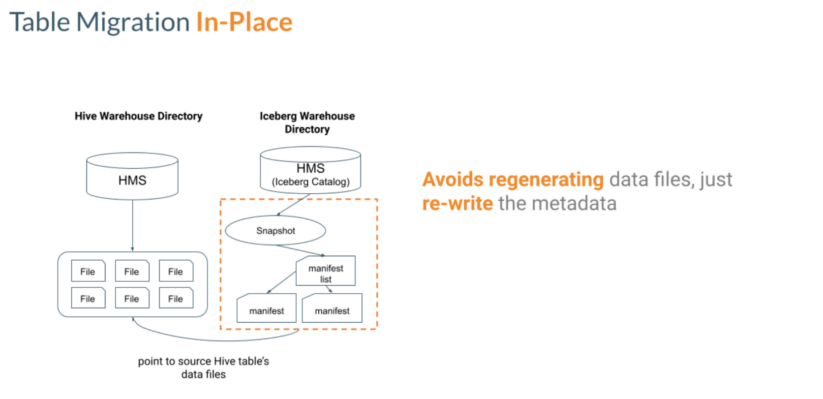
- Amazingly fast table migration
With in-place table migration, you can rapidly convert to Iceberg tables since there is no need to regenerate data files. Only metadata will be regenerated. Newly generated metadata will then point to source data files as illustrated in the diagram below.
- Data quality using table rollback
When data quality issues come to light, you can use table rollback to get back to a known high quality state. You can quickly restore data to a known good state, and take corrective actions faster and easier.
- Maintaining performance and manageability with improved table maintenance
Improve performance and overall manageability of Iceberg tables using the new table maintenance capabilities such as expiring old snapshots and removing their metadata, and compaction to combine small files for more efficient data processing.
- ORC open file format support
In addition to the Parquet open file format support, Iceberg in CDP now also supports ORC in the latest release. Support for these common industry standard open file formats further helps accelerate adoption of Iceberg and open lakehouse implementation.
- Accelerate analytics with materialized view support
In CDP, users can create materialized views on top of Iceberg tables. Materialized views are an industry standard practice for databases to accelerate analytics query execution by significant orders of magnitude.
- Performance and scalability
Cloudera developed unique features in CDP for Iceberg query performance and scalability for large data sets including I/O caching, dynamic partition pruning, vectorization, Z-ordering, parquet page indexes, and manifest caching.
General availability of ACID transactions with Iceberg tables
Since we launched our support for Apache Iceberg in CDP, newer releases have been under development at Apache. Apache Iceberg version 0.14.1 (a.k.a. Apache Iceberg v2) provides support for data modification language (DML) operations such as row-level delete and update. With CDP’s Iceberg v2 general availability, users are able to maintain transactional consistency on Iceberg tables even when accessing the same data using multiple engines simultaneously. With Iceberg v2, you can access and process data, all while maintaining read consistency and multi-engine/user concurrent writes due to serializable isolation and optimistic concurrency control. In addition to DELETE and UPDATE SQL commands developed for DML, the MERGE SQL command is also offered to take advantage of row-level DML operations to simplify ETL data pipelines.
Integrated with Cloudera Data Platform
Iceberg tables supported on CDP, automatically inherit the centralized and persistent Shared Data Experience (SDX) services—security, metadata, and auditing—from your CDP environment.
The following SDX security controls are inherited from your CDP environment:
- Authentication
CDP integrates with your corporate identity provider to maintain a single source of truth for all user identities.
- Fine grained authorization
Ensures that only users who have been granted adequate permissions are able to access the Iceberg tables and the data stored in those tables.
- Auditing
Apache Ranger provides a centralized framework for collecting access audit history and reporting data, including filtering on various parameters.
- Metadata management
Apache Atlas provides services to collect metadata when the service performs certain operations. You can use Atlas to find, organize, and manage different aspects of data about your Iceberg tables and how they relate to each other. This enables a range of data stewardship and regulatory compliance use cases.
Summary
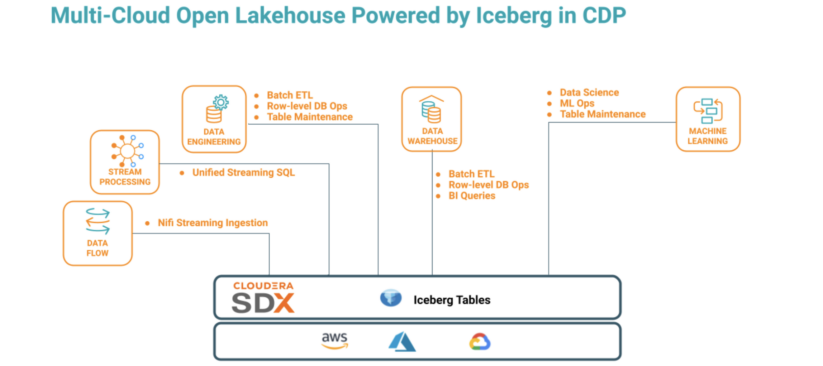
Cloudera’s integration of Apache Iceberg in CDP continues to benefit from new enhancements as we join the community in innovating on this modern table format. New capabilities such as multi-cloud deployment, ACID compliance, and enhanced multi-function analytics accelerate implementation for the multi-cloud open data lakehouse to meet ever-evolving requirements for modern data warehouse, data lake, AI/ML, data science, and more.
To learn more:
- Replay our webinar Unifying Your Data: AI and Analytics on One Lakehouse, where we discuss the benefits of Iceberg and open data lakehouse.
- Read why the future of data lakehouses is open.
- Replay our meetup Apache Iceberg: Looking Below the Waterline.
Try Cloudera DataFlow (CDF), Cloudera Data Warehouse (CDW), Cloudera Data Engineering (CDE), and Cloudera Machine Learning (CML) by signing up for a 60 day trial, or test drive CDP. If you are interested in chatting about Apache Iceberg in CDP, let your account team know or contact us directly. As always, please provide your feedback in the comments section below.
Other Contributors to this article: Manish Maheshwari, Peter Ableda, Navita Sood , Imran Rashid, Priyank Patel, Michael Kohs, Ashish Shah, David Dichmann, Joseph Niemiec
Editor's Choice

