

Apache Hadoop is a proven platform for long-term storage and archiving of structured and unstructured data. Related ecosystem tools, such as Apache Flume and Apache Sqoop, allow users to easily ingest structured and semi-structured data without requiring the creation of custom code. Unstructured data, however, is a more challenging subset of data that typically lends itself to batch-ingestion methods. Although such methods are suitable for many use cases, with the advent of technologies like Apache Spark, Apache Kafka, and Apache Impala (Incubating), Hadoop is also increasingly a real-time platform.
In particular, compliance-related use cases centered on electronic forms of communication, such as archiving, supervision, and e-discovery, are extremely important in financial services and related industries where being “out of compliance” can result in hefty fines. For example, financial institutions are under regulatory pressure to archive all forms of e-communication (email, IM, social media, proprietary communication tools, and so on) for a set period of time. Once data has grown past its retention period, it can then be permanently removed; in the meantime, such data is subject to e-discovery requests and legal holds. Even outside of compliance use cases, most large organizations that are subject to litigation have some form of archive in place for purposes of e-discovery.
Traditional solutions in this area comprise various moving parts and can be quite costly and complex to implement, maintain, and upgrade. By using the Hadoop stack to take advantage of cost-efficient distributed computing, companies can expect significant cost savings and performance benefits.
In this post, as a simple example of this use case, I’ll describe how to set up an open source, real-time ingestion pipeline from the leading source of electronic communication, Microsoft Exchange.
Setting Up Apache James
Being the most common form of electronic communication, email is almost always the most important thing to archive. In this exercise, we will use Microsoft Exchange 2013 to send email via SMTP journaling to an Apache James server v2.3.2.1 located on an edge node in the Hadoop cluster. James is an open source SMTP server; it’s relatively easy to set up and use, and it’s perfect for accepting data in the form of a journal stream.
The following steps were used to install and configure the James server:
- Install Oracle JDK 1.6 or later on the node.
- Download the Apache James server binary zip and extract it. We used version 2.3.2.1 as it is the latest and most stable release (at the time of this writing).
wget http://apache.mirrors.ionfish.org//james/server/james-binary-2.3.2.1.tar.gz tar -zxvf james-binary-2.3.2.1
- Note that the base directory is
./Apache_James/james-2.3.2.1/. - The configuration file,
config.xml, is located in./Apache_James/james-2.3.2.1/apps/james/SAR-INF/config.xml. Output the incoming mail to a local directory by setting theToRepository mailetclass in the Jamesconfig.xmlas seen below (further detailed instructions here):file:///home/flume/
- The classes in the
Matcherinterface can be used in the future to help filter out incoming email (e.g.SenderIsclass,RecipientIsclass). This will be important in allowing organizations to not archive a specific set of employees. This request tends to be common. - Start the Apache James server:
./Apache_James/james-2.3.2.1/bin/phoenix.sh start
NOTE: Don’t worry that the shell script is called
phoenix.sh. It’s NOT Apache Phoenix. - Install telnet:
sudo yum install telnet
- Send a test email to the Apache James server using telnet.
> telnet Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. 220 172.16.1.131 SMTP Server (JAMES SMTP Server 3.0-beta4) ready Sat, 6 Nov 2010 17:31:33 +0100 (CET) > ehlo test 250-172.16.1.131 Hello test (aoscommunity.com [127.0.0.1]) 250-PIPELINING 250-ENHANCEDSTATUSCODES 250 8BITMIME > mail from:<YOUR_NAME@YOUR_DOMAIN> NOTE: must include the <> 250 2.1.0 Sender <YOUR_NAME@YOUR_DOMAIN> OK > rcpt to:<YOUR_NAME@YOUR_DOMAIN> NOTE: must include the <> 250 2.1.5 Recipient <YOUR_NAME@YOUR_DOMAIN> OK > data 354 Ok Send data ending with . > subject: test > this is a test > . 250 2.6.0 Message received > quit Connection closed by foreign host.
You should see your test email land in the
/home/flumedirectory as configured in Step 4 above. - For detailed instructions on installing and configuring the James server, follow the instructions on the Apache James website, located here.
Setting Up Microsoft Exchange Journal Stream
Here we are using Exchange 2013 on a Windows 2012 server. Setting up Exchange is outside the scope of this post, but if you’re starting from scratch and need assistance, there are many good walkthroughs online, such as this one.
First, let’s set up set up an Exchange journal stream. A journal stream sends a copy of specified messages to a particular location. We’ll configure our stream to send a copy of every message to our Apache James SMTP server.
The process for setting up a journal stream has remained largely unchanged over the years. The steps are as follows:
-
- Set up a remote domain for the journal stream.
- Set up a send connector that points to the remote domain.
- Set up a mail contact that lives in the remote domain into which we’ll journal email.
- Create a journal rule to journal mail to the mail contact.
From this point on, email will be sent to the James server. Note that we’ll describe setting up journaling for a premium Exchange server; the difference between premium and standard Exchange servers is that the former allows you to journal by mail group, whereas the latter only allows journaling the full mail server. The finer-grained access control of a premium server can be desirable for organizations that have more complicated routing requirements.
Set Up a Remote Domain for the Journal Stream
Starting in Exchange 2013, remote domains are set up via the Exchange powershell, so open that up and run the following command:
New-RemoteDomain -DomainName clouderaarchive.com -Name "Cloudera Archive"
Note that the DomainName is not important; it doesn’t need to actually exist. If you ever need to list out your remote domains, use the Get-RemoteDomain command.
Set Up a Send Connector That Points to the Remote Domain
Log onto the Exchange Admin Center and Navigate to Mail Flow > Send Connector. Add a New Connector and follow the following steps.
- Give the connector a unique name. Select the “Connector Type” of “Custom”. This will allow us to route messages to a different server, i.e. Apache James.
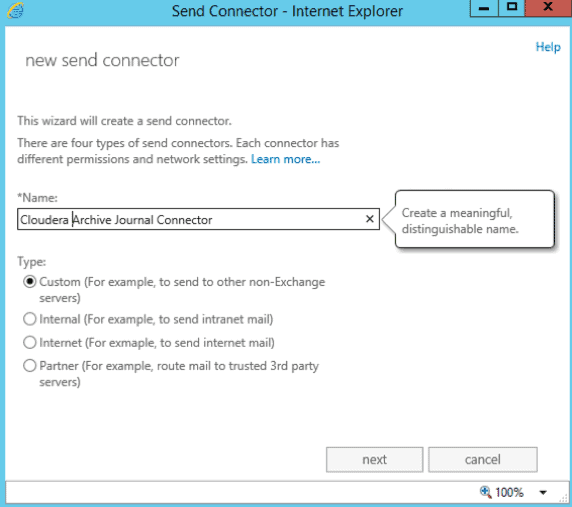
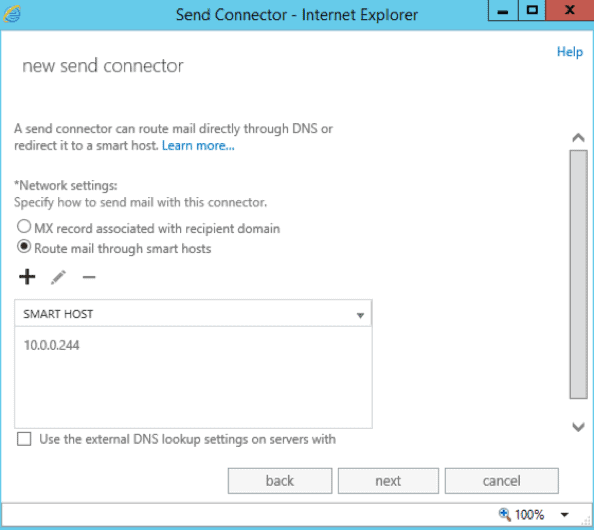
- On the next page, select the network setting to “Route mail through smart hosts”. Add a new smart host and put the IP address of the James SMTP Server.
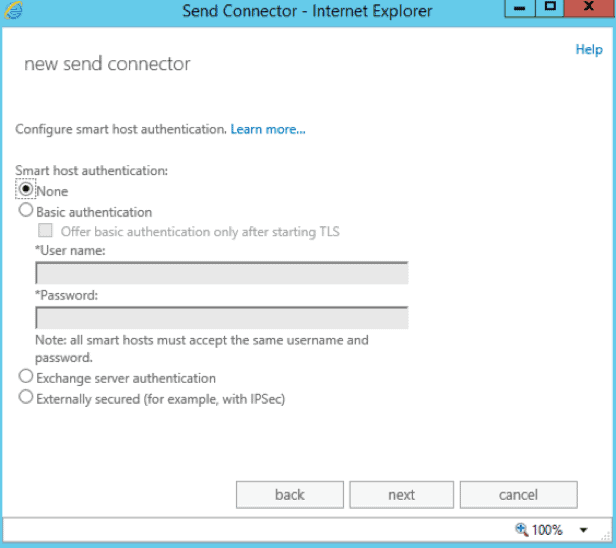
- James does not require authentication, so we can select “none” for the host authentication.
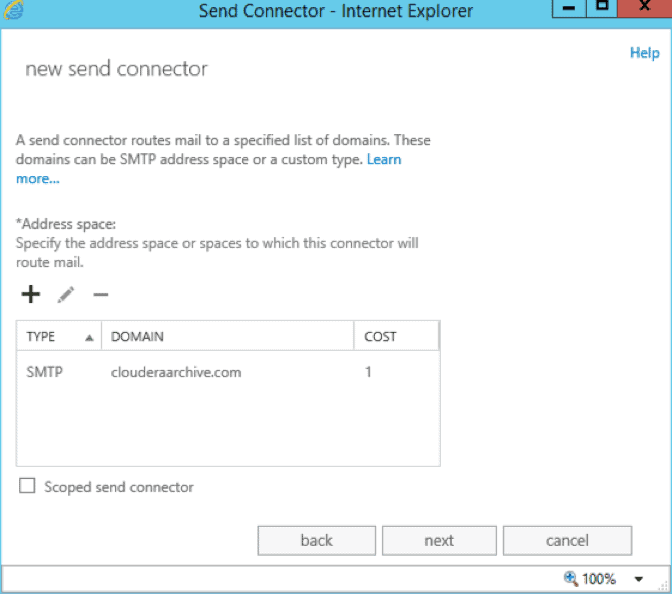
- Specify the address space of the send connector by adding a new address space. Use SMTP for the type, and input the remote domain created above as the domain. In our case, that’s
clouderaarchive.com.
- Now, we’ll select the mail servers we want to associate with this connector. Click the plus sign to add a new server and select the desired servers from the list.
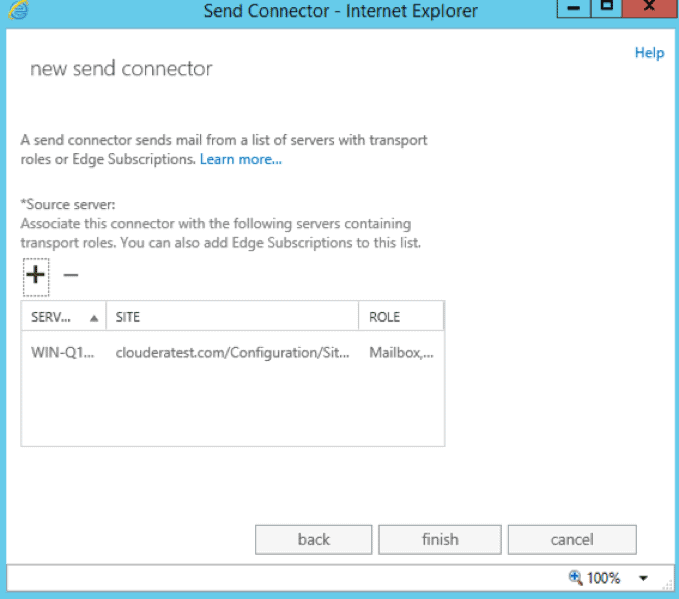
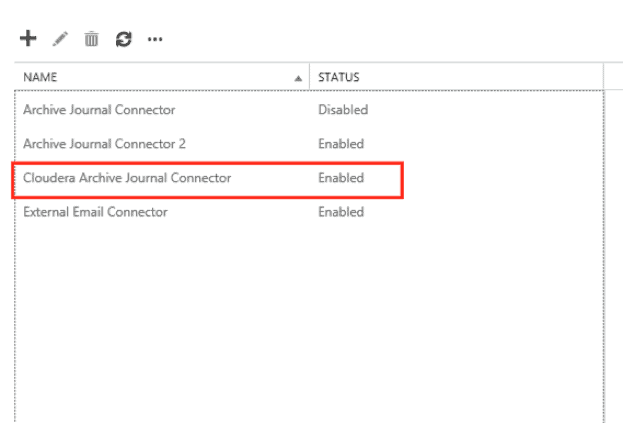
- Click “Finish” to complete the send connector. Verify that the connector appears on the list of send connectors and that it is enabled.
Set Up a Mail Contact That Lives in the Remote Domain
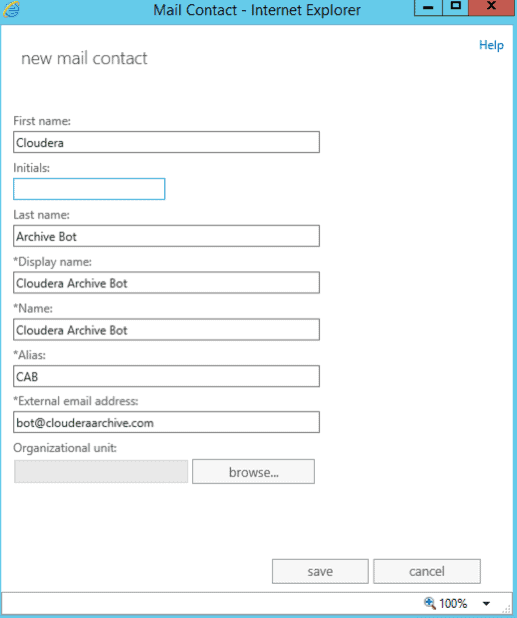
In the Exchange Admin Center, navigate to Recipients > Contacts. Add a new contact and fill out the form for a new contact. The important thing for this contact is that it needs to have an address that lives in our remote domain. Save the contact and verify that it appears on the list.
Create a Journal Rule to Journal Mail to the Mail Contact
In the Exchange Admin Center, navigate to Compliance Management > Journal Rules. Add a new journal rule and follow the steps below:
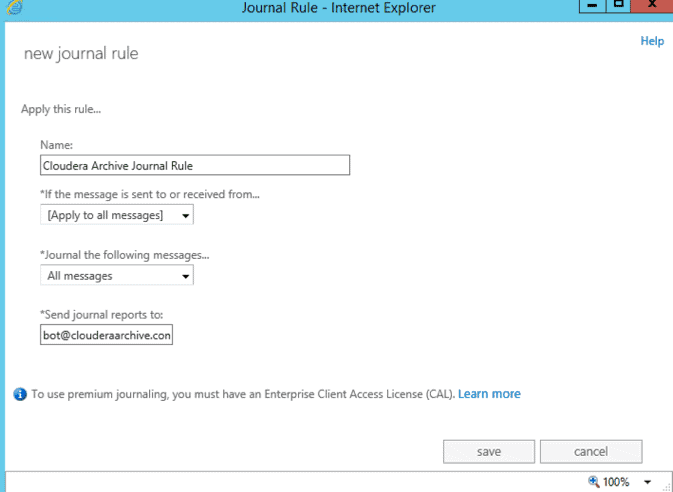
- Configure to which messages this rule applies. For premium accounts, you can opt to apply it to all messages or to messages to/from a select group or user. You can also opt to journal all messages, or internal/external only. Be sure to send the journal reports to the mail contact created above. In our case, that’s
bot@clouderaaarchive.com.
- Verify that the journal rule appears in the list and is checked so that it will be applied to future messages.
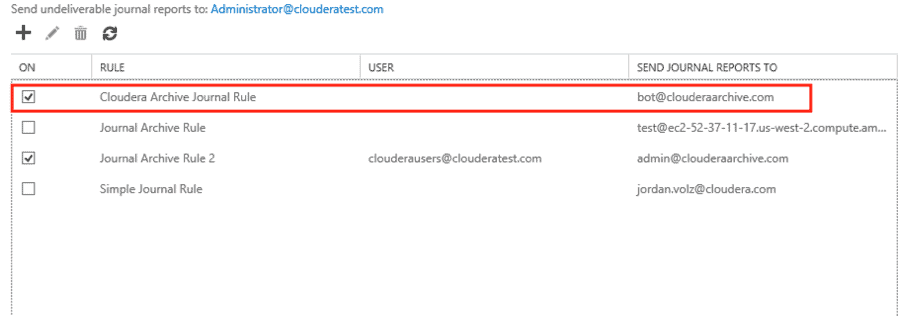
- Note that at the top of this page you can configure where undeliverable journal reports are sent. Many organizations have a dedicated mailbox that exchange admins use to track messages that can’t be journaled.
Configure Apache James to Receive Journal Stream
By default, James’ configuration file (config.xml) prevents incoming email. Add the address of the exchange server to the authorizedAddress list and restart the James Server. In our case, 10.0.0.99 is the address of the Exchange server.
127.0.0.0/8, 10.0.0.99
At this point, you can verify that messages are being sent to Apache James by logging into an Exchange mailbox and sending an email. (Be sure that the sender or recipient belongs in a group that is journaled!) The message should immediately be sent out to the recipient, and you will also see a copy land in the /home/flume directory on the James Server. Next, we’ll set up the connection into Hadoop.
Setting Up Apache Flume and Apache Kafka
For ingestion into Hadoop, we will use a Flafka setup. We set up one Flume agent that has a spool dir source and a Kafka sink. Once email has landed in the local directory from the James Server, the Flume agent picks it up and using a file channel, sends it to a Kafka sink. A blob deserializer ensures the email is not broken up into separate files, thereby ensuring compliance and allowing us to work with the entire email as one object.
Here is a sample Flume configuration:
#Flume which picks up the eml files from Apache James. Spool Dir -> File channel -> Kafka sink # Sources, channels, and sinks are defined per # agent name, in this case 'tier1'. tier1.sources = source1 tier1.channels = channel1 tier1.sinks = sink1 # For each source, channel, and sink, set #source tier1.sources.source1.type = spooldir tier1.sources.source1.channels = channel1 tier1.sources.source1.spoolDir = /home/flume/ #tier1.sources.source1.fileHeader = true tier1.sources.source1.basenameHeader = true tier1.sources.source1.deletePolicy = immediate tier1.sources.source1.ignorePattern = ^.*FileObjectStore$ tier1.sources.source1.deserializer = org.apache.flume.sink.solr.morphline.BlobDeserializer$Builder #channel tier1.channels.channel1.type = file tier1.channels.channel1.checkpointDir = /home/flume_checkpoint tier1.channels.channel1.dataDirs = /home/flume_dataDirs #sink tier1.sinks.sink1.channel = channel1 tier1.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink tier1.sinks.sink1.topic = ClouderaArchive tier1.sinks.sink1.brokerList = 10.0.0.84:9092
Apache Spark Streaming for Data Enrichment
Now we have email being generated by Exchange, journaled to James, picked up by Flume, and pushed onto a Kafka Topic. From here, there are many things that we can do with our data. For example. we can push it into Apache Solr for indexing and searching, we could pull out metadata and store it into Apache Hive/Impala for interactive analysis and reporting, or we could even perform real-time surveillance of the data using Spark Streaming to apply rule-based policies and machine learning to flag suspicious and anomalous content (such as anti-money laundering, Chinese wall violations, inappropriate customer interactions, and so on). These topics are all advanced and deserve their own space; we’ll dedicate some time to exploring these in upcoming blog posts.
Here we’ll address a different topic: As is well-known, HDFS is subject to the small-files problem. Email tends to be fairly small, generally clocking in somewhere around 100KB per average email, and many organizations put limits on the size of attachments so that we’ll never see emails in the hundreds of MBs or GBs file sizes for which Hadoop is most effective. As such, we’ll need to group emails in order to package them together.
Note that this is purely for storage efficiency and any requirements concerning being able to search through individuals emails (which is typical of archiving, e-discovery, and surveillance workflows) can be satisfied by indexing the emails in Cloudera Search. Similarly, a combination of tools like Apache Kudu/Impala would be ideal for analysis via SQL and providing a sensible method of updating the metadata associated with each email.
Below is sample Spark Streaming code that picks data out from Kafka, packages it, and saves it into HDFS. This process helps us avoid the small-files problem.
import kafka.serializer.StringDecoder
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.streaming.{StreamingContext,Seconds}
import org.apache.spark.streaming.kafka.KafkaUtils
import java.io.{OutputStream,FileOutputStream, BufferedOutputStream}
import java.net.URI
import java.security.MessageDigest
import java.text.SimpleDateFormat
import java.util.zip.{ZipOutputStream,ZipEntry}
import java.util.Calendar
//create context, conf
val ssc = new StreamingContext(sc,Seconds(60))
//default broker port is 9092
val brokers = "10.0.0.84:9092"
//set up kafka params
//use "auto.offset.reset" -> "smallest" to read from the beginning of topic
val kafkaParams = Map[String, String]("metadata.broker.list" -> brokers, "auto.offset.reset" -> "smallest")
//set topics to read from
val topics = "Cloudera Archive"
val topicsSet = topics.split(",").toSet
//create dstream
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet).repartition(sc.defaultParallelism)
//zip messages in each rdd and save as a file
//take your dstream, apply func on each RDD,
//on each RDD, save each parition to a zip file
messages.foreachRDD(rdd => rdd.foreachPartition{ partitionOfEmails =>
//get time for filename
val now = Calendar.getInstance().getTime()
val format = new SimpleDateFormat ("yyy-MM-dd-hhmmss")
val fileText=format.format(now)
val folderText=fileText.substring(0,10)
val zipText=fileText.substring(11,17)
//connection to hdfs
val conf = new Configuration()
//URI = fs.default.name, use newInstance instead of get
val hdfs = FileSystem.newInstance(new URI("hdfs://10.0.0.235:8020"),conf)
val file = new Path("hdfs://10.0.0.235:8020/user/ec2-user/"+folderText+"/"+zipText+"-"+rdd.id+"-"+partitionOfEmails.hashCode+".zip")
if (!hdfs.exists(file)){
val os = hdfs.create(file)
val bos = new BufferedOutputStream(os)
val zos = new ZipOutputStream(bos)
//for each email, add to zip file
partitionOfEmails.foreach{ email =>
val text = email._2
val digest = MessageDigest.getInstance("MD5")
val email_hash = digest.digest(text.getBytes).map("%02x".format(_)).mkString
val entry = new ZipEntry(email_hash+".eml")
zos.putNextEntry(entry)
zos.write(text.getBytes())
zos.closeEntry()
}
//close connections
zos.close
bos.close
os.close
}
hdfs.close
})
ssc.start()
The above code saves each partition in the DStream as a zip file. These files should be sufficiently large to avoid the small-files problem; the size can be customized for various email volumes by adjusting the window size of the DStream and partitioning the data into smaller numbers of partitions.
It’s not hard to see how this code could easily be extended to implement other features common to archiving systems: deduplication, metadata enrichment, reconciliation reporting, and so on. Spark is a great tool for accomplishing these tasks, and more.
Conclusion
This post described how to ingest email into Hadoop from an journal stream in real time. Conveniently, it is common practice to convert other types of electronic communication into email format for archiving purposes. Such data can then be ingested precisely as described above.
With data ingestion covered, we’ll move on to more advanced topics in future posts. One sore spot in several compliance use cases is the lack of analytics present in many existing solutions. Just as a RDBMS struggles with unstructured data, many systems built to deal with unstructured data struggle to merge that data with structured sources to provide more advanced analytic and surveillance capabilities. Hadoop is well suited for this use case, and we’ll see what can be accomplished for it next time.
Jordan Volz and Stefan Salandy are System Engineers at Cloudera.
Editor's Choice


Hi,
Thanks for sharing this information with us . It is really good. If you are facing issues while setting up mail, then visit Email Setup to get resolutions to all mail configuration issues.
Can this process be replicated to set up a Microsoft Outlook journal stream?