


Learn about the new Apache Flume and Apache Kafka integration (aka, “Flafka”) available in CDH 5.8 and its support for the new enterprise features in Kafka 0.9.
Over a year ago, we wrote about the integration of Flume and Kafka (Flafka) for data ingest into Apache Hadoop. Since then, Flafka has proven to be quite popular among CDH users, and we believe that popularity is based on the fact that in Kafka deployments, Flume is a logical choice for ingestion “glue” because it provides a simple deployment model for quickly integrating events into HDFS from Kafka.
Kafka 0.9, released in late 2015, introduced a number of important features for the enterprise (particularly focusing on security; more on that later). These features were only implemented in the latest Kafka client API implementations, one of which (the new consumer) was also first introduced in Kafka 0.9.
Because the initial Flafka implementation was based on the “old” Kafka clients—clients that will soon be deprecated—some adjustments to Flume were needed to provide support for these new features. Thus, FLUME-2821, FLUME-2822, FLUME-2823, and FLUME-2852 were contributed upstream by the authors and will be part of the upcoming Flume 1.7 release. These changes were also back-ported into CDH 5.8, which was released in July 2016.
In the remainder of this post, we’ll describe those adjustments and the resulting configuration options.
Problem Statement
The Kafka community is committed to making new Kafka releases backward-compatible with clients. (For example, an 0.8.x client can talk to an 0.9.x broker.) However, due to protocol changes in 0.9, that assurance does not extend to forward compatibility from a client perspective: Thus, an 0.9.x client cannot reliably talk to a 0.8.x broker because there is no way for the client to know the version of Kafka to which it’s talking. (Hopefully, KIP-35 will offer progress in the right direction.)
Why does this matter? There are a few reasons:
- Integrations that utilize Kafka 0.9.x clients, if they can talk to Kafka 0.8.x brokers at all (unlikely), may get cryptic error messages when doing so (for example,
java.nio.BufferUnderflowException). - Integrations will only be able to support one major version of Kafka at a time without more complex class loading being done.
- Older clients (0.8.x) will work when talking to the 0.9.x server, but that doesn’t allow these clients to take advantage of the security benefits introduced in 0.9.
This problem puts projects like Flume in a tricky position. To simultaneously support current and previous versions would require some special and sophisticated class-loader mechanics, which would be difficult to build. So, based on lessons learned in projects like Apache Hive, Apache MRUnit, and Apache Spark, the community decided to take a “cut-over” approach for Flume: In short, the latest version of Flume (1.7) will only support brokers in Kafka 0.9 and later.
Changes in Flume 1.7
As a refresher on Flafka internals, Flafka includes a Kafka source, Kafka channel, and Kafka sink.
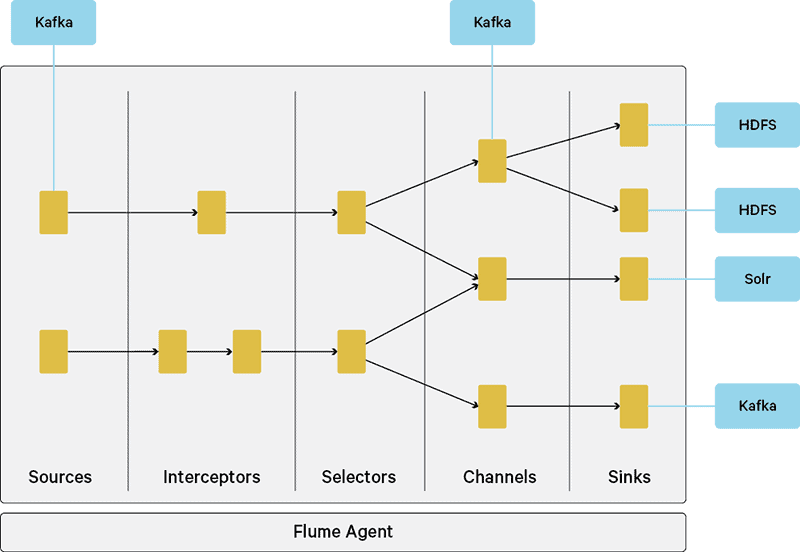
During the rewrite of the Flafka components, the agent-configuration naming scheme was also simplified. In an effort to convey importance, Flafka v1 provided Flume “mirror” properties to Kafka client properties. For example, the sink property requiredAcks was equal to the Kafka producer property request.required.acks. In the latest version of Flafka, these Flume properties are discarded in favor of matching the Kafka client properties. Helpfully, CDH 5.8 includes new logic that allows old configuration parameters to be picked up when applicable; however, users should switch to the new parameter style now. While this step is somewhat painful, in the long run, deployment is simplified.
Next, let’s explore this naming hierarchy. The configuration parameters are organized as follows:
- Configuration values related to the component itself (source/sink/channel) generically are applied at the component config level: a1.channel.k1.type =
- Configuration values related to Kafka or how the component operates are prefixed with
kafka.(analogous toCommonClientconfigs and not dissimilar to how the HDFS sink operates):a1.channels.k1.kafka.topic = and a1.channels.k1.kafka.bootstrap.servers = - Properties specific to the producer/consumer are prefixed by
kafka.producerorkafka.consumer: a1.sinks.s1.kafka.producer.acks and a1.channels.k1.kafka.consumer.auto.offset.reset - Where possible, the Kafka parameter names are used: bootstrap.servers and acks
The full documentation, with examples, has been updated and will be officially available when Flume 1.7 is released. For now, the following tables mirror the upstream Flume documentation.
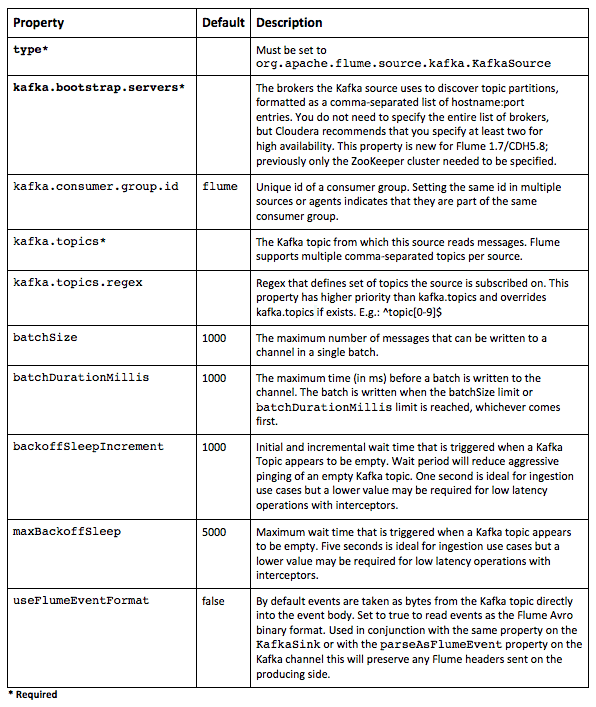
Kafka Source
Kafka Sink
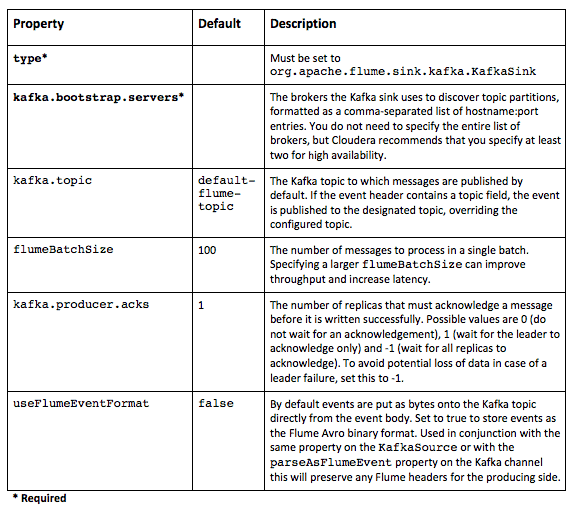
In addition, the sink now respects the key and topic Flume headers and will use the value of the key header when producing messages to Kafka.
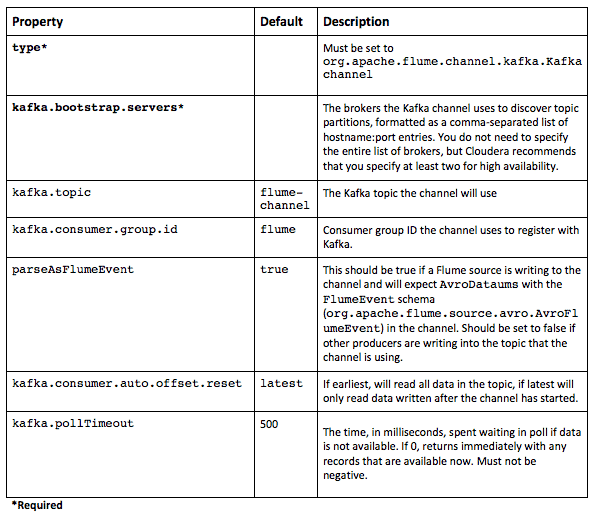
Kafka Channel
Other Enhancements
Flume 1.7 will address a number of feature requests and improvements to Flafka components. The most interesting is the ability to natively to read and write Flume Avro Events. This provides the ability to set and preserve headers in the Event itself. The Flume Avro Event schema is simple:
Map<String,String> headers byte[] body
This functionality has always been embedded in the Channel implementation. By adding the parameter useFlumeEventFormat = true, the source and sink can read and write, respectively, events using the above schema. Thus, any headers inserted by a source, or by any interceptors, can be passed from a Kafka sink to a Kafka source. This design also works for mixing and matching the Kafka channel with either the Kafka sink or Kafka source.
Examples
To follow are a couple example scenarios for implementing Kafka and Flume with security enabled, and using the new Flume release. It’s assumed that you have already followed appropriate documentation here to enable authentication and SSL for Kafka itself.
Scenario 1: Kafka Source -> Kafka Channel-> HDFS Sink
tier1.sources=kafkasource1 tier1.channels=kafkachannel tier1.sinks=hdfssink tier1.sources.kafkasource1.type=org.apache.flume.source.kafka.KafkaSource tier1.sources.kafkasource1.channels=kafkachannel tier1.sources.kafkasource1.kafka.bootstrap.servers=10.0.0.60:9092,10.0.0.61:9092,10.0.0.62:9092 tier1.sources.kafkasource1.kafka.topics=flume-aggregator-channel tier1.sources.kafkasource1.kafka.consumer.fetch.min.bytes=200000 tier1.sources.kafkasource1.kafka.consumer.enable.auto.commit=false tier1.channels.kafkachannel.type = org.apache.flume.channel.kafka.KafkaChannel tier1.channels.kafkachannel.brokerList = 10.0.0.60:9092,10.0.0.61:9092,10.0.0.62:9092 tier1.channels.kafkachannel.kafka.topic = channeltopic tier1.sinks.hdfssink.type=hdfs tier1.sinks.hdfssink.channel=kafkachannel tier1.sinks.hdfssink.hdfs.path=/user/flume/syslog/%Y/%m/%d tier1.sinks.hdfssink.hdfs.rollSize=0 tier1.sinks.hdfssink.hdfs.rollCount=0 tier1.sinks.hdfssink.hdfs.useLocalTimeStamp=true tier1.sinks.hdfssink.hdfs.fileType=DataStream tier1.sinks.hdfssink.hdfs.batchSize=10000
Scenario 2: Kafka Channel -> HDFS Sink
tier1.channels=kafkachannel tier1.sinks=hdfssink tier1.channels.kafkachannel.type = org.apache.flume.channel.kafka.KafkaChannel tier1.channels.kafkachannel.kafka.bootstrap.servers = 10.0.0.60:9092,10.0.0.61:9092,10.0.0.62:9092 tier1.channels.kafkachannel.kafka.topic = channeltopic tier1.sinks.hdfssink.type=hdfs tier1.sinks.hdfssink.channel=kafkachannel tier1.sinks.hdfssink.hdfs.path=/user/flume/syslog/%Y/%m/%d tier1.sinks.hdfssink.hdfs.rollSize=0 tier1.sinks.hdfssink.hdfs.rollCount=0 tier1.sinks.hdfssink.hdfs.useLocalTimeStamp=true tier1.sinks.hdfssink.hdfs.fileType=DataStream tier1.sinks.hdfssink.hdfs.batchSize=10000
Performance Tuning
Based on customer experiences, we know that it’s already possible to achieve very high throughput using Flume and Kafka (over 1 million messages per second end-to-end using Flume 1.6 on a three-node Kafka cluster). Even better, the new producers and consumers in Kafka 0.9 introduce a whole set of new parameters for fine-tuning performance when writing and reading from Kafka. In general terms, the key to achieving high throughput is to minimize the overhead of transactions by utilizing batches. There is a trade-off here, though: large batches often attract their own overhead (specifically memory), and they don’t utilize resources smoothly. The larger the batch, the higher the latency (especially when the system isn’t running at 100% of capacity—for example, with a peaky load profile). Batch control is slightly harder in Kafka 0.9, as there are several parameters involved, most of them are specified in bytes, and some depend on the number of partitions configured or number of partitions to which are being written at a given time.
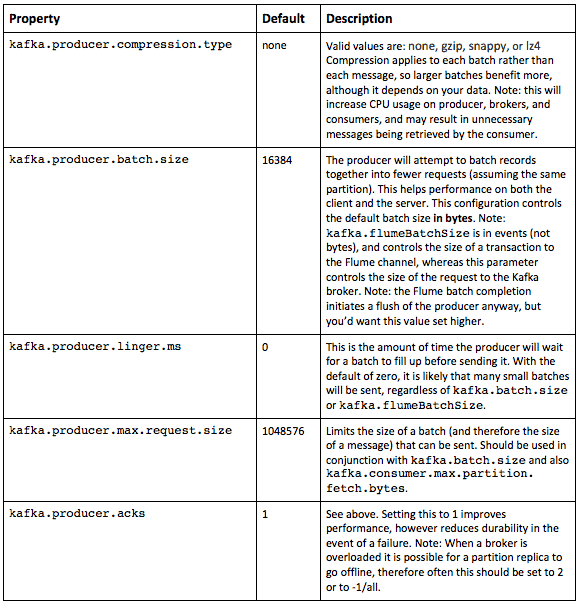
In a recent internal performance test using syslog messages, the difference between a poorly vs. well-tuned configuration yielded between 0.2x to 10x performance improvement compared to an un-tuned configuration.
Producer
One of the major changes in Flume 1.7 is that there is now no synchronous mode for the producer: essentially, all messages are sent asynchronously (that is, by a background thread that manages its own batches). In Kafka 0.8/Flume 1.6, synchronous mode was the default, although that setting could be changed.
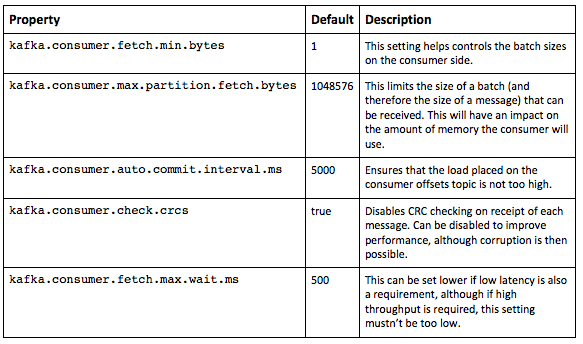
Consumer
Security
As mentioned previously, perhaps the most important of new features in Kafka 0.9 were directly related to platform security: specifically, support of Kerberos/SASL authentication, wire encryption via SSL, and authorization support. Thus, because Flafka is based on use of 0.9 Kafka clients, the Flume bits shipping in CDH 5.8 already support secure implementations of Kafka. (In a future post, we’ll cover proper configuration of secure Kafka in CDH.)
Known Issues
Because the new clients have switched to using Kafka for offset storage, manual migration of offsets from Apache ZooKeeper to Kafka is necessary in the short term. Please see the full documentation on this process here.
Conclusion
After reading the above, you should have a good understanding of the significant changes introduced in Kafka 0.9, and their impact on the upcoming Flume 1.7 release. Fortunately, if you are a CDH user, you now have access to much of that functionality via the Flume 1.7 backports in CDH 5.8.
Jeff Holoman is an Account Manager at Cloudera, and a contributor to Apache Kafka and Apache Flume.
Tristan Stevens is a Senior Solutions Architect at Cloudera, and a contributor to Apache Flume.
Grigory Rozhkov is a Software Engineer at CyberVision Inc., and a contributor to Apache Flume.
Editor's Choice

