

The new cluster templates feature in Cloudera Manager 5.7 makes creating clusters faster and easier.
Often, after an Apache Hadoop cluster has been configured correctly, its admin will want to replicate the configuration in one or more clusters—whether for promoting a dev or staging cluster to production, or setting up a new production cluster with the same configuration as an existing one.
For Cloudera customers, until recently the process for replicating cluster configurations was manual and error-prone. Starting in Cloudera Manager 5.7, the cluster templates feature make this process faster, easier, and more reliable.
Cluster templates capture the full configuration of a cluster for configuring and bootstrapping a new cluster in a single API call. Users can either export the configuration from an existing cluster as a template or create a template from scratch. In essence, an admin can export a “golden” copy of the configuration and then easily stamp out clusters with a similar configuration.
In this post, I’ll provide a few examples for getting started with this feature. Note that cluster templates are currently an API-only feature (with Java and Python bindings), with a user interface on the product roadmap.
Exporting Cluster Templates
Users can export the configuration of an existing cluster as a JSON file (full example here). Below is the Python code snippet for exporting a cluster template.
import json
from cm_api.api_client import ApiResource
from cm_api.endpoints.types import ApiClusterTemplate
from cm_api.endpoints.cms import ClouderaManager
resource = ApiResource("localhost", 7180, "admin", "admin", version=12)
cluster = resource.get_cluster("Cluster 1")
template = cluster.export()
with open('/tmp/template.json', 'w') as outfile:
json.dump(template.to_json_dict(), outfile, indent=4, sort_keys=True)
The exported JSON template has the following main sections.
cdhVersion– CDH version of the source cluster"cdhVersion" : "5.7.0", "displayName" : "Cluster 1", "cmVersion" : "5.7.0",
displayName– Source cluster display namecmVersion– Source cluster Cloudera Manager versionrepositories– Contains the parcel repositories list from source Cloudera Manager"repositories": ["http://cache-gce-central-1.gce.cloudera.com/repos/cdh5.7.0-static/parcels/5.7.0/","http://cache-gce-central-1.gce.cloudera.com/archive/cdh4/parcels/4.7.1/",..."],
-
products– CDH products installed on source Cloudera Manager"products" : [ { "version" : "2.1.0-1.2.1.0.p0.20", "product" : "KAFKA" }, { "version" : "1.6.0-1.cdh5.1.4.p0.116", "product" : "ACCUMULO" }, { "version" : "5.7.0-1.cdh5.7.0.p0.46", "product" : "CDH" } ], services– Main section containing configuration of the services installed in the source cluster (one entry for each service)"refName" : "ZOOKEEPER-1", "serviceType" : "ZOOKEEPER", "serviceConfigs" : [ { "name" : "enableSecurity", "value" : "true" } ], "roleConfigGroups" : [ { "refName" : "ZOOKEEPER-1-SERVER-BASE", "roleType" : "SERVER", "configs" : [ { "name" : "zookeeper_server_java_heapsize", "value" : "705691648" } ],refName– Service reference name used to resolve dependencies across servicesserviceType– Service type (ZOOKEEPER, HDFS, and so on)serviceConfigs– Service-level configurationname– Configuration name; each configuration has one of the following possible additional properties:value– Concrete configuration valuevariable– Provided at import time by the userref– Points to either a role or a service and should contain correct role or service reference. Role references will be discussed in detail later.
autoConfig : true|false– The user has an option to export auto-configured values. The auto-configured properties, which are generated by Cloudera Manager, are only included for reference purposes. An example is the heap size, which is set based on the availability of the resources on the host.
roleConfigGroups– A cluster template contains all the configurations for a Role Config Group. The template does not contain role-level configuration. If a user has role-level configuration, which Cloudera Manager already discourages, the user has to create a new Role Config Group with the same configuration and assign that to the role. This section also defines the configuration similar to the way it is defined in the service section.roles– Some services depend on roles. All the roles for a service type on which some other service depends need to be declared. (For example, Hue is dependent on the NAMENODE role.) So, the exported HDFS service should have a “roles” section with that rolerefandtypedeclared. During import time, the user has to specify on which host this role is specifically deployed.refName– Role reference name used to resolve dependenciesroleType– Role type, e.g NAMENODE.
hostTemplates– This section defines host templates. It’s basically a group of roles that will be set up together on a single host. In Cloudera Manager, the user can define host templates. If there are none, during export, Cloudera Manager will use the current roles assignment to create host templates."hostTemplates" : [ { "refName" : "HostTemplate-0-from-nightly-kerberized-4.gce.cloudera.com", "cardinality" : 1, "roleConfigGroupsRefNames" : [ "ACCUMULO16-1-ACCUMULO16_TRACER-BASE", "ACCUMULO16-1-ACCUMULO16_TSERVER-BASE", "ACCUMULO16-1-GATEWAY-BASE", "FLUME-1-AGENT-BASE", "HBASE-1-REGIONSERVER-BASE", "HDFS-1-DATANODE-BASE", "HIVE-1-GATEWAY-BASE", "IMPALA-1-IMPALAD-BASE", "KUDU-1-KUDU_TSERVER-BASE", "MAPREDUCE-1-TASKTRACKER-BASE", "SPARK_ON_YARN-1-GATEWAY-BASE", "SQOOP_CLIENT-1-GATEWAY-BASE", "YARN-1-NODEMANAGER-BASE" ] }, { "refName" : "HostTemplate-1-from-nightly-kerberized-[2-3].gce.cloudera.com", "cardinality" : 2, "roleConfigGroupsRefNames" : [ "ACCUMULO16-1-ACCUMULO16_TRACER-BASE", "ACCUMULO16-1-ACCUMULO16_TSERVER-BASE", "ACCUMULO16-1-GATEWAY-BASE", "FLUME-1-AGENT-BASE", "HBASE-1-REGIONSERVER-BASE", "HDFS-1-DATANODE-BASE", "HIVE-1-GATEWAY-BASE", "IMPALA-1-IMPALAD-BASE", "KAFKA-1-KAFKA_BROKER-BASE", "KUDU-1-KUDU_TSERVER-BASE", "MAPREDUCE-1-TASKTRACKER-BASE", "SPARK_ON_YARN-1-GATEWAY-BASE", "SQOOP_CLIENT-1-GATEWAY-BASE", "YARN-1-NODEMANAGER-BASE" ] }, {-
refName– Used in the instantiator sectioncardinality– The number of hosts on which this template is applied in the source clusterroleConfigGroupsRefNames– Specifies roles and the configuration of those roles
Instantiator– The main section that needs to filled by the user before importing a cluster template to create a cluster"instantiator" : { "clusterName" : "imported-cluster", "hosts" : [ { "hostName" : "host4", "hostTemplateRefName" : "HostTemplate-1-from-host2", "roleRefNames" : [ "hdfs-NAMENODE-4feb06b4a698c6b1bb7643b8d850bbe1" ] }, { "hostNameRange" : "host[5-6]", "hostTemplateRefName" : "HostTemplate-0-from-host3" } ], "variables" : [ { "name" : "hdfs-NAMENODE-BASE-dfs_name_dir_list", "value" : "/data/dfs/nn,/data2/dfs/nn" }, { "name" : "hdfs-SECONDARYNAMENODE-BASE-fs_checkpoint_dir_list", "value" : "/data/dfs/snn" }, { "name" : "hive-hive_metastore_database_host", "value" : "host1" }, { "name" : "hive-hive_metastore_database_name", "value" : "hive" }, { "name" : "hive-hive_metastore_database_password", "value" : "cmf" }, { "name" : "hive-hive_metastore_database_user", "value" : "cmf" },clusterName– Name of the cluster; has to be unique in the destination Cloudera Managerhosts– Specifies which host template should be applied on the hostshostName– Host namehostTemplateRefName– Host template reference name forhostTemplatessectionroleRefNames– Specifies if this host has any of the roles that need to be resolved. For example, Hue is dependent on NAMENODE, and if this host has the NAMENODE role instance that user wants Hue to use, then mention that role reference here.hostNameRange– The user can also map a range of hosts with a particular host template
Variables– All the configurations that are mapped with a variable. All those variables need to be declared under this section.
Importing Cluster Templates
To import a cluster template, you would use the following command. (You can try this yourself by making a copy of our sample template, modifying it as needed, and filling out the instantiator section.)
import json
from cm_api.api_client import ApiResource
from cm_api.endpoints.types import ApiClusterTemplate
from cm_api.endpoints.cms import ClouderaManager
from cm_api.endpoints.types import ApiClusterTemplateHostInfo resource = ApiResource("localhost", 7180, "admin", "admin", version=12)
with open('/tmp/template.json') as data_file:
data = json.load(data_file)
template = ApiClusterTemplate(resource).from_json_dict(data, resource)
# Fill instantiator with the information related to target cluster host mapping
template.instantiator.clusterName = 'Imported-Cluster'
hosts = []
hosts.append(ApiClusterTemplateHostInfo(resource))
hosts[0].hostName = 'host00001'
hosts[0].hostTemplateRefName = 'HostTemplate-1-from-host00001'
hosts[0].roleRefNames = ['hdfs-NAMENODE-aa5e025d506864e1aea297e46ffb16e3']
hosts.append(ApiClusterTemplateHostInfo(resource))
hosts[1].hostNameRange = 'host[00002-00004]'
hosts[1].hostTemplateRefName = 'HostTemplate-0-from-host[00002-00004]'
template.instantiator.hosts = hosts
# Provide variable values for all variables in template.instantiator.variables
for variable in template.instantiator.variables:
if variable.name == 'oozie-OOZIE_SERVER-BASE-oozie_database_password':
variable.value = 'test'
elif variable.name == 'oozie-OOZIE_SERVER-BASE-oozie_database_user':
variable.value = 'test'
cms = ClouderaManager(resource)
cms.import_cluster_template(template)
Cloudera Manager will then run the command.
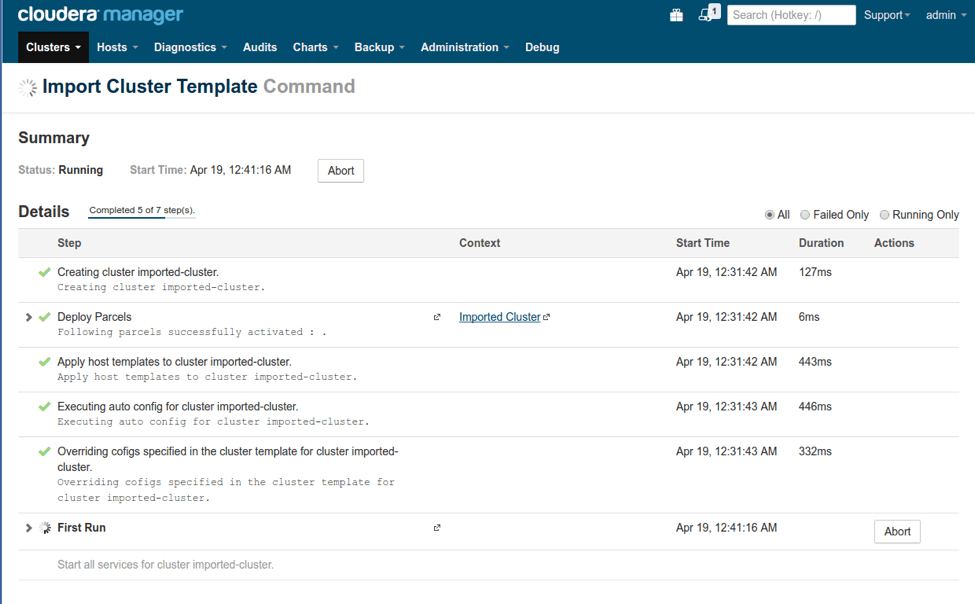
Figure 1: Import Cluster Template
The import process is resilient: If the import command fails because of some misconfiguration issue, the user can fix it in the destination Cloudera Manager and retry the command; it will re-start from where it failed. Similarly, the user can abort an inflight command, modify the configuration, and then re-try.
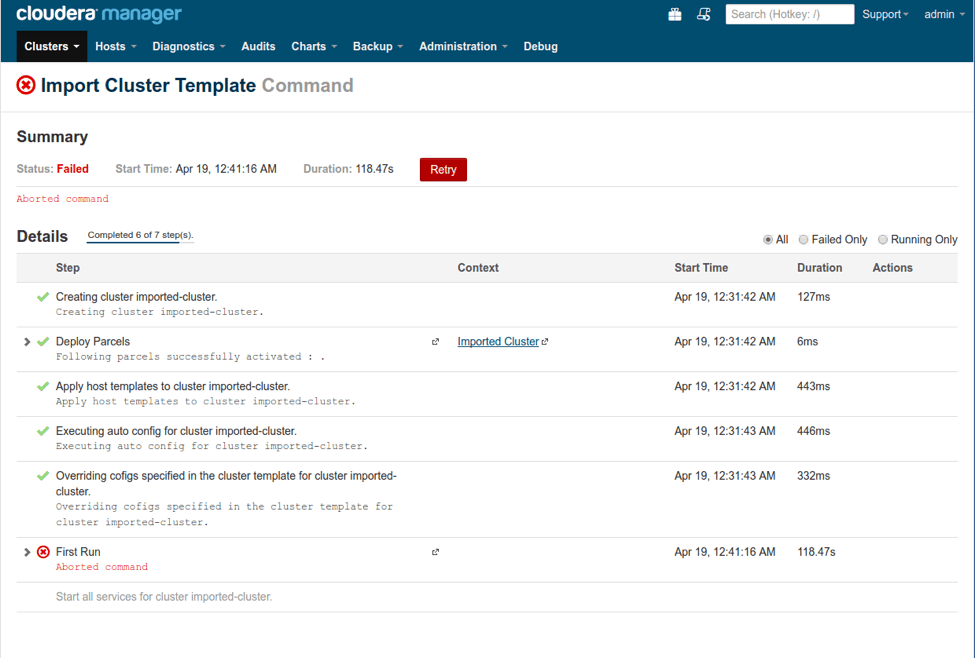
Figure 2: Import Cluster Template Retry
Conclusion
As I have demonstrated here, the new cluster templates feature in Cloudera Manager 5.7 greatly simplifies the process of creating clusters in automation, especially in an environment where clusters are routinely created.
Vivek Chaudhary is a Software Engineer at Cloudera.
Editor's Choice

