

Introduction
In this blog, I will demonstrate the value of Cloudera DataFlow (CDF), the edge-to-cloud streaming data platform available on the Cloudera Data Platform (CDP), as a Data integration and Democratization fabric. Within the context of a data mesh architecture, I will present industry settings / use cases where the particular architecture is relevant and highlight the business value that it delivers against business and technology areas. To better articulate the value proposition of that architecture, I will present the benefits that CDF delivers as an enabler of a data mesh architecture from a business case I built for a Cloudera client operating in the financial services domain.
This blog will focus more on providing a high level overview of what a data mesh architecture is and the particular CDF capabilities that can be used to enable such an architecture, rather than detailing technical implementation nuances that are beyond the scope of this article.
Introduction to the Data Mesh Architecture and its Required Capabilities
Introduction to the Data Mesh Architecture
The concept of the data mesh architecture is not entirely new; Its conceptual origins are rooted in the microservices architecture, its design principles (i.e., reusability, loose coupling, autonomy, fault tolerance, composability, and discoverability) and the problems it was trying to solve; In summary, and mirroring the microservices architecture paradigm, the Data Mesh architecture aims at bringing a level of integration among disparate and individually governed data domains without introducing any change in data ownership, thus promoting data decentralization.
The need for a decentralized data mesh architecture stems from the challenges organizations faced when implementing more centralized data management architectures – challenges that can attributed to both technology (e.g., need to integrate multiple “point solutions” used in a data ecosystem) and organization reasons (e.g., difficulty to achieve cross-organizational governance model). Those decentralization efforts appeared under different monikers through time, e.g., data marts versus data warehousing implementations (a popular architectural debate in the era of structured data) then enterprise-wide data lakes versus smaller, typically BU-Specific, “data ponds”. While a data mesh architecture introduces some trade-offs, the scope of this blog is not to evaluate its advantages or disadvantages or contrast it against other data architectures, but simply focus on how Cloudera DataFlow (CDF) enables such a decentralized architecture.
Components of a Data Mesh
The implicit assumption for implementing a Data Mesh architecture is the existence of well bounded, separately governed data domains. In the Enterprise Data Management realm, such a data domain is called an Authoritative Data Domain (ADD). According to the Enterprise Data Management Council, an Authoritative Data Domain is “A Data Domain that has been designated, verified, approved and enforced by the data management governing body”.
A data mesh can be defined as a collection of “nodes”, typically referred to as Data Products, each of which can be uniquely identified using four key descriptive properties:
- Application Logic: Application logic refers to the type of data processing, and can be anything from analytical or operational systems to data pipelines that ingest data inputs, apply transformations based on some business logic and produce data outputs.
- Data and Metadata: Data inputs and data outputs produced based on the application logic. Also included, business and technical metadata, related to both data inputs / data outputs, that enable data discovery and achieving cross-organizational consensus on the definitions of data assets.
- Infrastructure Environment: The infrastructure (including private cloud, public cloud or a combination of both) that hosts application logic and data.
- Data Governance Model: The organizational construct that defines and implements the standards, controls and best practices of the data management program applicable to the Data Product in alignment with any relevant legal and regulatory frameworks. The Data Governance body designates a Data Product as the Authoritative Data Source (ADS) and its Data Publisher as the Authoritative Provisioning Point (APP).
Key Design Principles of a Data Mesh
In order to fulfill its vision and objectives, the data mesh is underpinned by the following design principles:
- Self-Serve Data Discovery: Data consumers (including internal business users, subscribing applications or even external data sharing partners) should be able to easily access data made available by data producers (typically publishing applications that operate as Authoritative Data Sources) via a self-serve mechanism (such as centralized UI portal) that reduces data access barriers.
- Comprehensive Data Security: Access to data assets should be governed by a robust security mechanism that ensures authentication for data participants based on enterprise-wide standards (data participants being data producers and consumers) and applies fine-grained data access permissions based on the data types (e.g., PII data) of each data product, and the access rights for each different group of data consumers.
- Data Lineage: Data constituents (including Data Consumers, Producers and Data Stewards) should be able to track lineage of data as it flows from data producers to data consumers but also, when applicable, as data flows between different data processing stages within the boundaries of a given data product. The latter case of data lineage applies in, e.g., data engineering pipelines where data inputs are transformed into data outputs following a series of transformations typically called Direct Acyclic Graphs (DAGs).
- Data Auditing: In addition to data lineage, Data Stewards and Information Security analysts should be able to track all interactions of Data Consumers with data assets / data products.
- Data Cataloging: A Data Catalog that includes enterprise-wide, acceptable definitions for the data elements that comprise the Data Products exposed through the Self-Serve Data portal. Those definitions include information around the business and technical context by means of exposing metadata information to data consumers and data producers that helps bring an understanding of data being made available for use.
- A (loose) coupling mechanism: A capability that enables data consumers to consume data in a reusable way (i.e., without developing point to point integrations), once they have subscribed to a particular ADS (and after being authorized to do so). Following the ESB paradigm, Data Products are abstractly decoupled from each other, and connect together through the coupling mechanism as logical endpoints that are exposed Data Products.
The aforementioned capabilities only cover the technology aspect of a data mesh architecture, and do not include the operational and governance capabilities required to establish such a decentralized data architecture.
How CDF enables successful Data Mesh Architectures
A quick introduction to the Cloudera DataFlow Platform
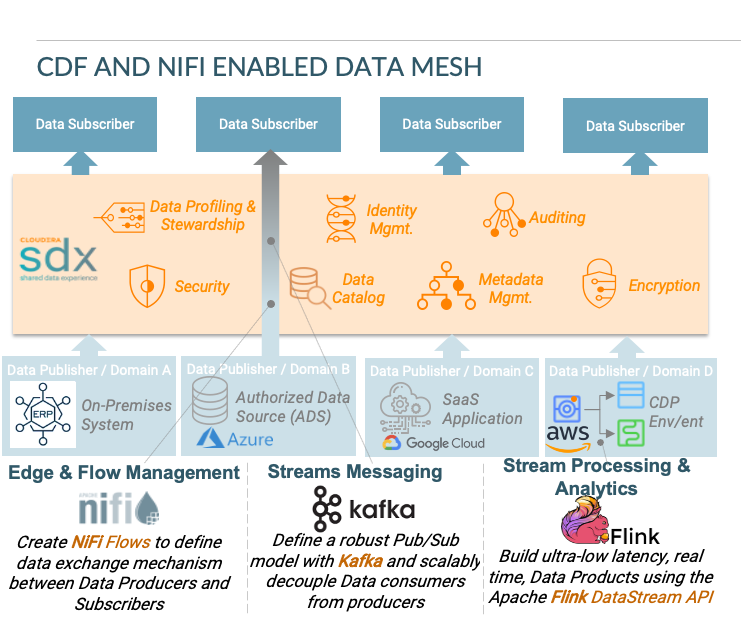
CDF is a real-time streaming data platform that collects, curates, analyzes and acts on data-in-motion across the edge, data center and cloud. CDF offers key capabilities such as Edge and Flow Management, Streams Messaging, and Stream Processing & Analytics, by leveraging open source projects such as Apache NiFi, Apache Kafka, and Apache Flink, to build edge-to-cloud streaming applications easily. Powered by CDP, the streaming components of CDF can be deployed seamlessly across the edge, on-premises as well as on any type of public, private or hybrid cloud environments.
Apache NiFi, in particular, is a data movement and ingestion tool that can be used to collect, transform and move voluminous and high speed data, regardless of its type, size, or origin. Some distinct advantages of Apache NiFi that make it a great candidate for Data Mesh implementations (in conjunction with the broader data security, governance and observability capabilities of the Cloudera Data Platform) include: centralized management, end-to-end traceability with event-level data provenance throughout the data lifecycle and interactive command and control, providing real time operational visibility. Other characteristics of NiFi that enables implementing a Data Mesh architecture in different contexts and varying scopes are schema independence (schema is optional but not necessary) and the ability to operate on any type of data by separating metadata from the payload.
CDF Capabilities Aligned with Key Design Principles for Data Mesh Implementations
CDF has many capabilities that align with the key design principles we outlined in the previous section:
Data Security: The Shared Data Experience (SDX), which is the data abstraction layer of the Cloudera Data Platform, delivers a unified mechanism for data security, governance and observability. Part of SDX is Apache Ranger, which offers a fine-grained, programmatic mechanism to define permissions for different data constituents / entities (internal or external users) on different Data Mesh resources.
Data Lineage: Both Apache NiFi and Apache Atlas (included with SDX) offer robust data provenance and data lineage capabilities, both inside and outside the boundaries of Data Products comprising the Data Mesh. When it comes to data movement outside the boundaries of Data Products (i.e., between publishers and subscribers), both Apache NiFi and Apache Atlas offer real-time data lineage as data flows between different data constituents allowing for data compliance and optimization. In addition, Apache Atlas offers real time data lineage within the boundaries of data products, when those Data Products have been composed using CDP experiences, or 3rd party solutions (such as EMR) that integrate with SDX.
Data Auditing: In addition to Data Lineage, that can be used to ensure data compliance, both NiFi and SDX offer additional data auditing capabilities, such as logging event-level details pertaining to all interactions of data constituents with data elements included in the data mesh.
Data Cataloging: SDX offers a sophisticated data cataloging capability that enables capturing both business and technical metadata of Data Products. It also comes with capabilities such as automated data classification, search using natural language etc. As is the case with other capabilities, Data Catalog can cover both intrinsic and extraneous data of Data Products.
Data Exchange Mechanism: As mentioned previously, NiFi offers a very robust and flexible data flow management capability that is based on Data Flow Programming, enabling some combination of data routing, transformation, or mediation between systems. As a result, NiFi enables data mesh implementations between different types of Data Products with heterogeneous data inputs / outputs (those Data Products could include operational or analytical systems, databases with structured or unstructured data, applications that produce event-streams, or even applications on edge devices) The foundational data movement mechanism is called a Flow Processor that defines how data retrieval, manipulation and routing are performed. Users can leverage existing Flow Processors or build their own to implement the required flow management logic for connecting data subscribers with data consumers.
Data Streaming Capability: Another component of CDF, Apache Kafka, enables developing auditable, re-playable data streams that define how the outputs of Data Products are being streamed as events to Data Consumers. That data streaming capability also enables the development of composite streaming architectures that address different functional characteristics in terms of streaming frequency (streams can be real-time or batch) or streaming pattern between Producers and Consumers (one-to-one or one-to-many). A common Data Mesh approach is to expose Data Product outputs as data events that are made available to Data Consumers via Kafka Topics (A Kafka topic is a way to categorize and store data outputs of a Data Producer that can be made available for consumption by Data Consumers).
The Value Proposition of CDF in Data Mesh Implementations
Typical client challenges CDF has delivered value against
CDF capabilities have been used in Data Mesh implementations in industries such as financial services and consumer discretionary. The typical challenges that organizations face before implementing a CDF-enabled Data Mesh are the following:
- Time To-Value: Without a loose coupling mechanism, providing access to a Data Product between a Data Subscriber and a Data Producer using a legacy approach is a cumbersome process that includes developing custom integrations between systems. In the case of a financial services institution I worked with to establish a Data Mesh business case, developing a custom integration (or ‘Data Feed’), involved activities such as development of Business Requirement Documents (BRDs), a lengthy approval cycle, scripting effort to develop Data Feeds, end-to-end testing of Data Feeds, etc.
- Metadata Management: In legacy implementations, changes to Data Products (e.g., updated / new tables) and the resulting changes to Data Feeds require additional development effort and manual reporting to enterprise data catalogs.
- Data Discovery: Typically, legacy implementations offer limited, if any, data discovery capabilities, and, most of the time, Data Feed subscribers have to trace that information back by reviewing BRDs. That’s one of the biggest indirect business costs of point-to-point data exchange mechanisms that introduces a lot of delays in business productivity by having data subscribers to spend a lot of time to understand origins of data and data relationships.
- Data Accessibility: While custom-based integrations deliver the required integration mechanism to connect Data Products, they typically don’t allow for individual users to access a Data Product, simply because the cost to create a point-to-point feed is too high to justify such an integration.
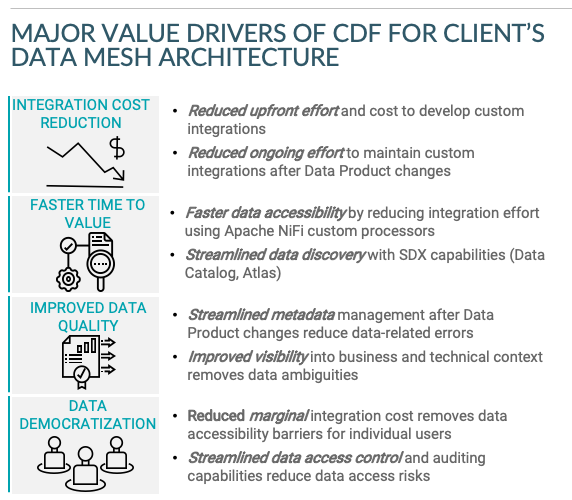
A Client Example
Recently, I built a business case for a major financial services institution to quantify the value of a Data Mesh Architecture with CDF using Apache NiFi as the data federation mechanism. The value drivers associated with that implementation were the following:
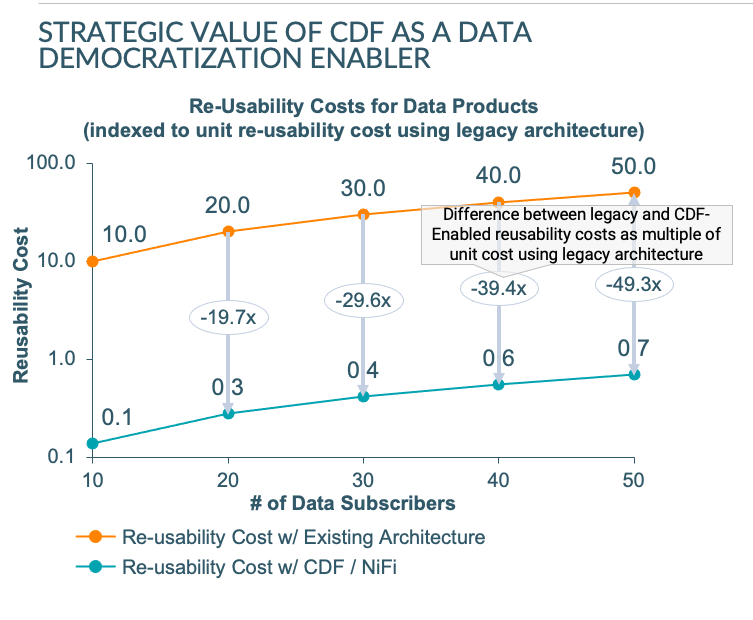
For example, compared to the existing architecture, the CDF-enabled Data Mesh reduced re-usability unit costs between Data Providers and Data Subscribers / Consumers by almost 99%. As a result, it made it possible to provision data assets to individual users / data consumers, something that would have otherwise been impossible given the unit cost economics for developing custom integrations between data providers and data subscribers.
Summary
In the sections above, I outlined the required capabilities of a Data Mesh architecture and I highlighted how the CDF platform can serve as the technology foundation for implementing such an architecture. The unique differentiation of CDF stems from the integrated security and governance capabilities and the versatility of the platform:
- The integrated security and governance capabilities available through the Shared Data Experience (SDX) have enabled successful Data Mesh implementations in regulated industries such as Financial Services.
- The versatility of the CDF platform and broader integration with CDP enable complex use cases that extend beyond the Data Mesh. For example, CDF has been used to implement enterprise-grade applications such as ingestion and processing of IoT data for customer analytics, real-time cybersecurity analytics, etc.
To learn more about the CDF platform, please visit https://www.cloudera.com/products/cdf.html
Editor's Choice

