



Cloudera recently released a fully featured Open Data Lakehouse, powered by Apache Iceberg in the private cloud, in addition to what’s already been available for the Open Data Lakehouse in the public cloud since last year. This release signified Cloudera’s vision of Iceberg everywhere. Customers can deploy Open Data Lakehouse wherever the data resides—any public cloud, private cloud, or hybrid cloud, and port workloads seamlessly across deployments.
With Cloudera Open Data Lakehouse in the private cloud, you can benefit from following key features:
- Multi-engine interoperability and compatibility with Apache Iceberg, including NiFi, Flink and SQL Stream Builder (SSB), Spark, and Impala.
- Time Travel: Reproduce a query as of a given time or snapshot ID, which can be used for historical audits, validating ML models, and rollback of erroneous operations, as an example.
- Table Rollback: Allow users to quickly correct problems by resetting tables to a good state.
- Rich set of SQL (query, DDL, DML) commands: Create or manipulate database objects, run queries, load and modify data, perform time travel operations, and convert Hive external tables to Iceberg tables using SQL commands.
- In-place table (schema, partition) evolution: Effortlessly evolve Iceberg table schema and partition layouts without rewriting table data or migrating to a new table, for example.
- SDX Integration: Provides common security and governance policies, as well as data lineage and auditing.
- Iceberg Replication: Provides disaster recovery and table backups.
- Easy portability of workloads to public cloud and back without any code refactoring.
In this multi-part blog post, we’re going to show you how to use the latest Cloudera Iceberg innovation to build an Open Data Lakehouse on a private cloud.
For this first part of the blog series we will focus on ingesting streaming data into the open data lakehouse and Iceberg tables making it available for further processing that we will demonstrate in the following blogs.
Solution Overview
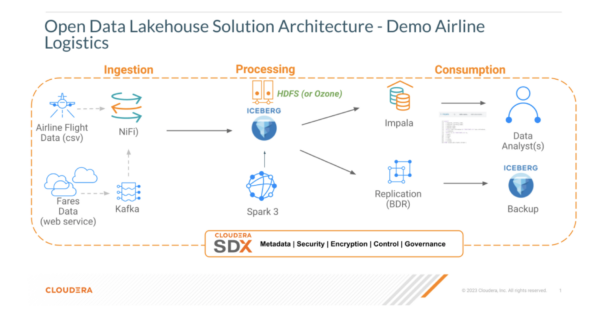
Pre-requisites
The following components in Cloudera Open Data Lakehouse on Private Cloud should be installed and configured and airline data sets:
- Cloudera Data Platform Private Cloud Base 7.1.9
- Cloudera Flow Management 2.1.6
- https://github.com/jingalls1217/airlines-source-data.git (make sure to unzip the flights.csv.gzip file in the flights directory)
In this example, we are going to use NiFi as part of CFM 2.1.6 to stream ingest data sets to Iceberg. Please note, you can also leverage Flink and SQL Stream Builder in CSA 1.11 as well for streaming ingestion. We use NiFi to ingest an airport route data set (JSON) and send that data to Kafka and Iceberg. We then use Hue/Impala to take a look at the tables we created.
Please reference user documentation for installation and configuration of Cloudera Data Platform Private Cloud Base 7.1.9 and Cloudera Flow Management 2.1.6.
Follow the steps below for using NiFi to stream ingest data into Iceberg tables:
1- Create the routes Iceberg table for NiFi ingestion in Hue/Impala execute the following DDL:

2- Download a pre-built flow definition file found here:
https://github.com/jingalls1217/airlines/blob/main/Data%20Flow/NiFiDemo.json
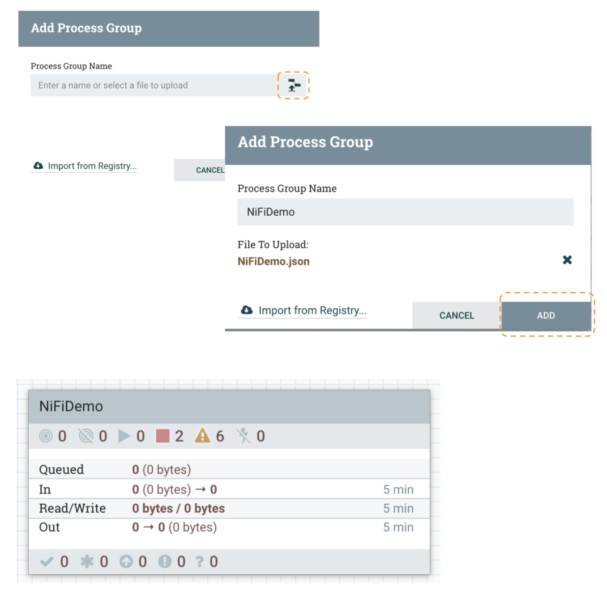
3-Create a new process group in NiFi and upload the flow definition file downloaded in step 2. First click the Browse button, select the NiFiDemo.json file and click the Add button.
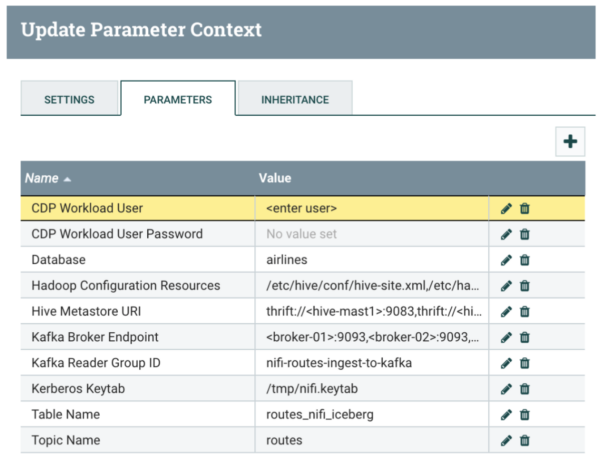
4- Update parameters as shown in table below:

5- Click into the NiFiDemo process group:
-
- Right click on the NiFi canvas, go to Configuration and enable the Controller Services.
- Open each Process Group and right click on the canvas, go to Configuration and Enable any additional Controller Services not yet enabled.
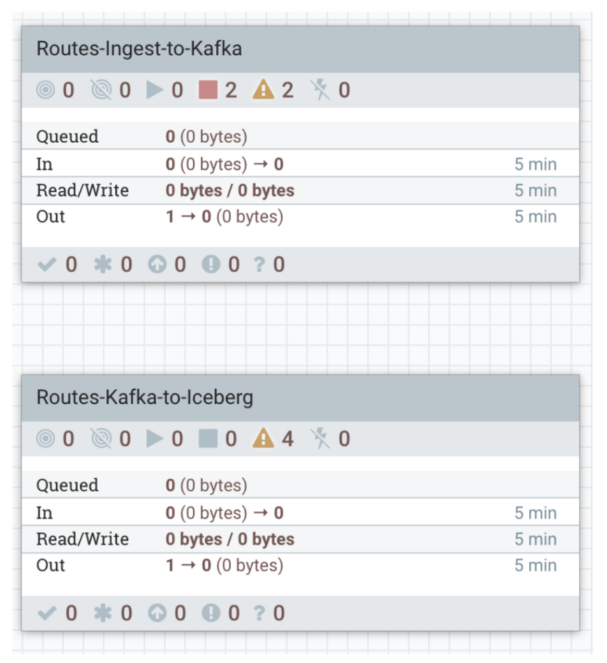
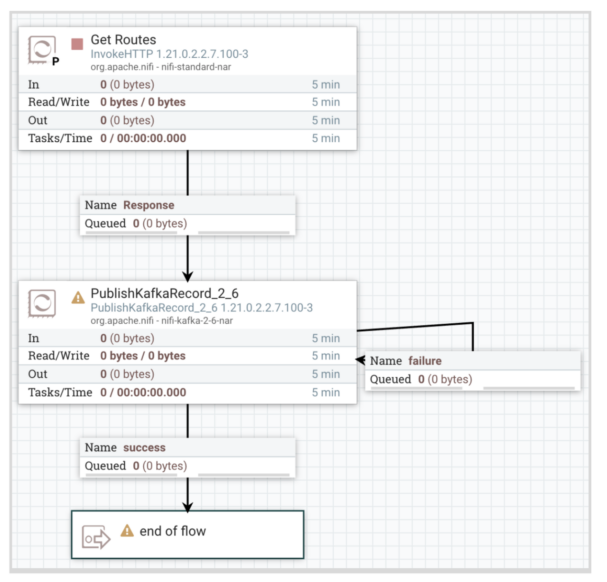
6- Start the Routes ingest to Kafka flow and monitor success/failure queues:
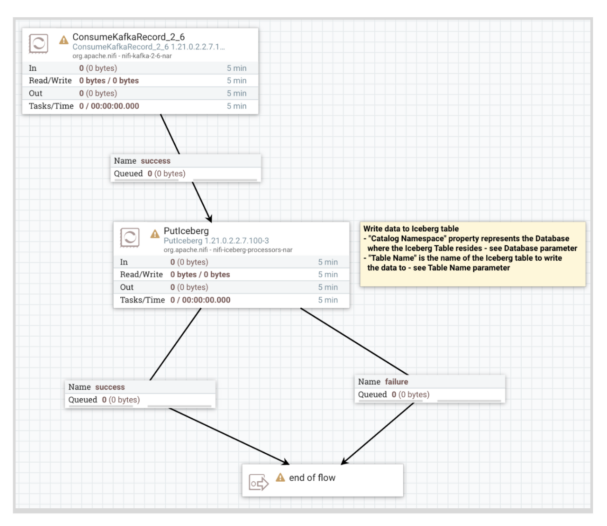
7- Start the Routes Kafka to Iceberg flow and monitor success/failure queues:
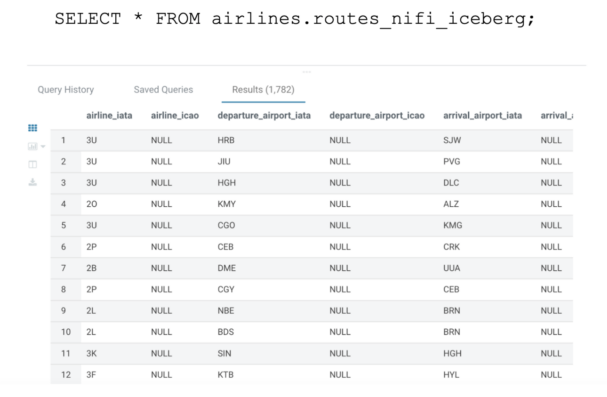
8- Inspect the Routes Iceberg table in Hue/Impala to see the data that has been loaded:
SELECT * FROM airlines.routes_nifi_iceberg;
Conclusion
In this first blog, we showed how to use Cloudera Flow Management (NiFi) to stream ingest data directly to the Iceberg table without any coding. Stay tuned for part two, Data Processing with Apache Spark.
To build an Open Data Lakehouse on your private cloud, download Cloudera Data Platform Private Cloud Base 7.1.9 and follow our Getting Started blog series.
And since we offer the exact same experience in the public and private cloud you can also join one of our Two hour hands-on-lab workshops to experience the open data lakehouse in the public cloud or sign up for a free trial. If you are interested in chatting about Cloudera Open Data Lakehouse, contact your account team. As always, we welcome your feedback in the comments section below.
Editor's Choice

