

Introduction
One of the most effective ways to improve performance and minimize cost in database systems today is by avoiding unnecessary work, such as data reads from the storage layer (e.g., disks, remote storage), transfers over the network, or even data materialization during query execution. Since its early days, Apache Hive improves distributed query execution by pushing down column filter predicates to storage handlers like HBase or columnar data format readers such as Apache ORC. Evaluating those predicates outside the execution engine yields less data for query evaluation (data pruning), and results in reduced query runtime and IO.
Problem
To enable data pruning, modern columnar formats such as ORC and Parquet maintain indexes, bloom filters, and statistics to determine if a group of data needs to be read at all before returning to the execution engine. Even though these statistics can significantly reduce IO, a query might still end up decoding many additional rows that are not needed for its evaluation. This is partly due to the way rows are internally managed by the columnar formats in groups (of thousands or rows) to increase compression efficiency and reduce the cost of indexing and statistics maintenance.
In fact, after a series of experiments on CDP public cloud using Hive we noticed that even for low selectivity queries such as TPC-DS query 43 (Q43), selecting around 7% of total rows, we end up spending almost 30% of CPU time decoding rows that will be eventually dropped!
Lazy decoding
The above observation inspired lazy decoding feature, or probecode, described in this post. Probedecode leverages existing query predicates while scanning large tables to only read columns that are mandatory for their evaluation before decoding any of the remaining columns thus minimizing the materialized rows flowing through the operator pipeline.
CDP Runtime 7.2.9 and CDP Public Cloud added support for lazy decoding that was recently introduced on Apache Hive along with the associated row-level filtering feature in ORC.
Using probedecode, Hive can avoid materializing data not needed for the evaluation of the query, saving CPU cycles, reducing memory allocations, and even eliminating filter operators from the pipeline. To achieve this, Hive leverages existing predicates and join conditions that are now pushed down to the TableScan operators. When the feature is enabled, a TableScan operator reads-early only a subset of the columns where the predicates are applied on before materializing any of the remaining columns. After the predicates are applied, it tracks the rows that do actually match the and decodes only the selected rows (if any) from the remaining columns.
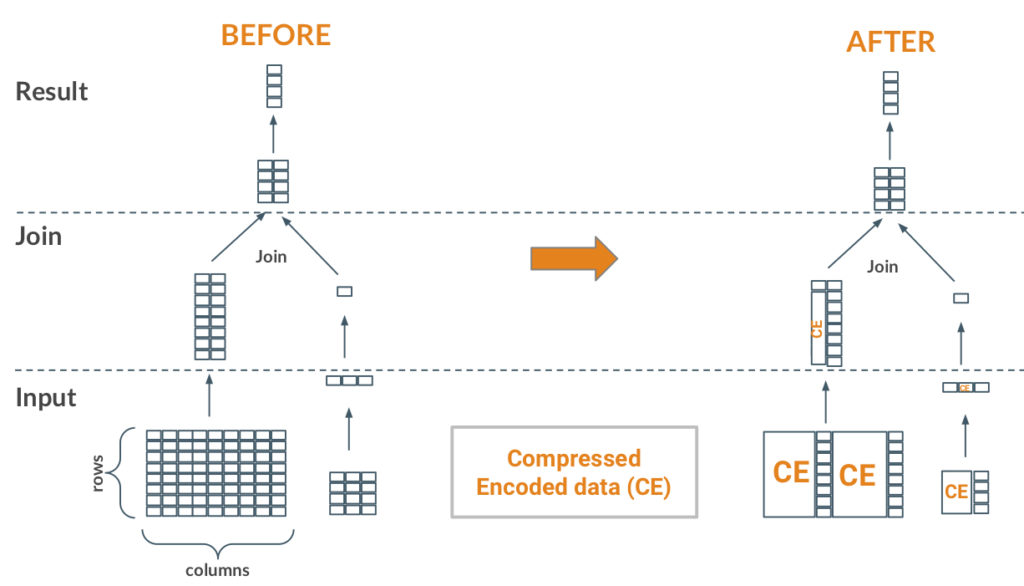
MapJoins can directly benefit from the probedecode feature. In a join between a small table (right side) and a big table (left side) we typically read the entire small table and broadcast the generated hash table to the tasks scanning the bigger table. In such a scenario, the tasks on the big table side can opportunistically use the broadcasted table keys on the left (streaming) side to decode only the matching keys (rows) from the remaining (non-key) columns. In the Figure above, one can observe that from the two projected columns, the key column is decoded early to find just one row matching the broadcasted keys and thus decoding a single row from the second column instead of decoding it completely (before part of the Figure).
Hive users can check how probedecode optimization applies for their MapJoin queries using their standard query explain plans. For instance, in the explain plan below, one can find the new probeDecodeDetails field of the TableScan operator. In this particular query the operator will decode early ss_item_sk column, then perform a lookup on the MAPJOIN_48 hash table (broadcasted) and finally decode only the matching rows from the ss_ext_sales_price column similar to the example above (note that ss_sold_date_sk is a partition column).
Map 1 <- Map 4 (BROADCAST_EDGE), Map 5 (BROADCAST_EDGE) Reducer 2 <- Map 1 (SIMPLE_EDGE) Reducer 3 <- Reducer 2 (SIMPLE_EDGE) Vertices: Map 1 Map Operator Tree: TableScan alias: store_sales probeDecodeDetails: cacheKey:MAPJOIN_48, bigKeyColName:ss_item_sk Statistics: Num rows: 82510879939 Basic stats: COMPLETE Column stats:COMPLETE TableScan Vectorization: native: true Select Operator expressions: ss_item_sk (type: bigint), ss_ext_sales_price (type: decimal(7,2)), ss_sold_date_sk (type: bigint) outputColumnNames: _col0, _col1, _col2 Select Vectorization: className: VectorSelectOperator native: true projectedOutputColumnNums: [1, 14, 22] Statistics: Num rows: 82510879939 Basic stats: COMPLETE Column stats:COMPLETE Map Join Operator condition map: Inner Join 0 to 1 keys: 0 _col2 (type: bigint) 1 _col0 (type: bigint) Map Join Vectorization: bigTableKeyColumns: 22:bigint className: VectorMapJoinInnerBigOnlyLongOperator input vertices: 1 Map 4
Performance
Even though queries running with probedecode feature enabled always have less rows emitted from their scan operators, the benefit is more pronounced on highly selective queries with a large number of projected columns, other than the ones used on predicates (more columns lead to more CPU savings).
In a series of benchmarks we observed runtime improvements ranging from 5% to 50% while below we also show some numbers when running TPC-DS benchmark. The benchmark was performed with a scale factor of 10, data stored in ORC format, and Hive running on CDP Public Cloud with 4 nodes.
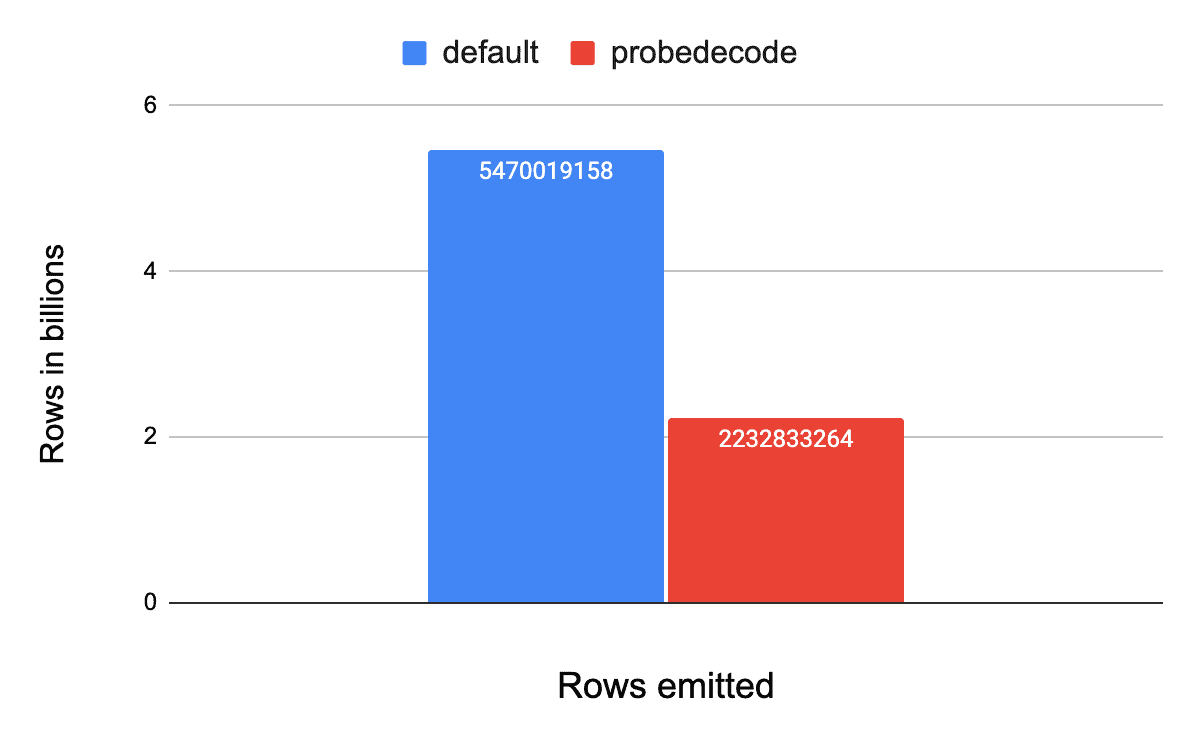
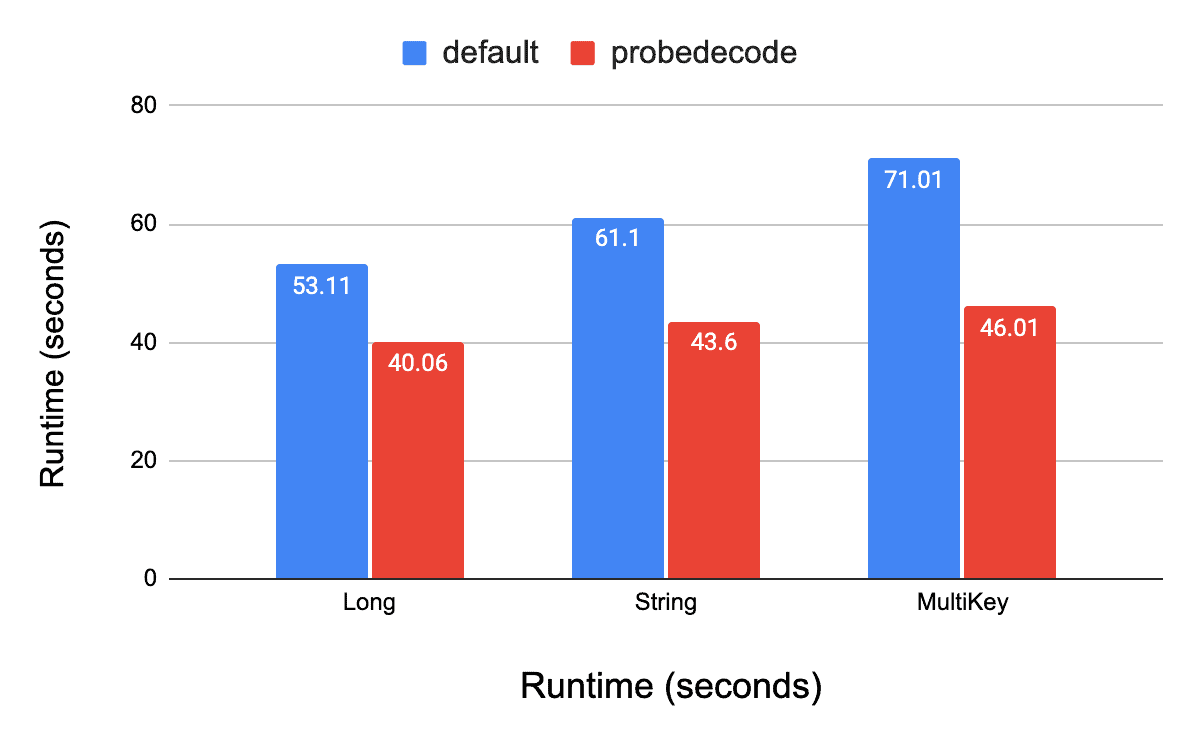
As shown in the Figures below, on TPC-DS Q43, probedecode reduces the number of emitted rows by 40% while improving the runtime by up to 35%. It is also notable that depending on the type of the join key the improvement may differ as some data types are more costly to deserialize and perform lookups on than others (see multikey). For Q43, using different join keys types, the improvement varies from 24% on Long join key, to 28% on String join key and is up to 35% on more complex join key like a Timestamp for this particular query — more results coming up in a follow-up blog post!
Feature availability
Users running MapJoin queries on ORC tables will have the feature enabled by default from CDP 7.2.9 onwards and on CDP Public Cloud. We highly recommend a user upgrade to get this feature and many other performance enhancements in the release! For more details about the optimization feel free to check the Hive and ORC tickets listed below and watch our ApacheCon talk!
Support for lazy materialization on static predicates is also on its way with another blogpost and more results so stay tuned!
References
- Accelerating distributed joins in Apache Hive: Runtime filtering enhancements
- Probedecode support for MapJoin with row-level filtering
- Allow row-level filtering on ORC
Editor's Choice

