

Intro
One of the biggest challenges in training a deep neural network lies in the quality and quantity of data collected for training. In previous blogs we highlighted how data is collected from our miniature self-driving car, and how it is transported from the source to HDFS using Cloudera DataFlow (CDF) and Cloudera Edge Manager (CEM). When a sufficient amount of data is collected, a model can be trained that “clones” the driving behavior of a person. The model is loosely based on the NVIDIA self-driving car model architecture that implements a behavioral cloning. In this blog, we will review how behavioral cloning is built, and how it is deployed to our car. We will also highlight how Cloudera’s tools enable us to use our data and models to their full potential.
Cloudera Data Science Workbench
Cloudera Data Science Workbench (CDSW) is a secure enterprise data science platform that enables data scientists to accelerate their workflow—from data exploration to model deployment—by allowing them to use already existing skills and tools such as Python, R, and Scala to run computations on Hadoop clusters. In our project, CDSW is used to retrieve data from the Hadoop Distributed File System (HDFS), train the behavioral cloning neural network model using Keras, and save the model back to HDFS. With a number of existing libraries and direct access to our data in HDFS, CDSW is a great choice for training our model.
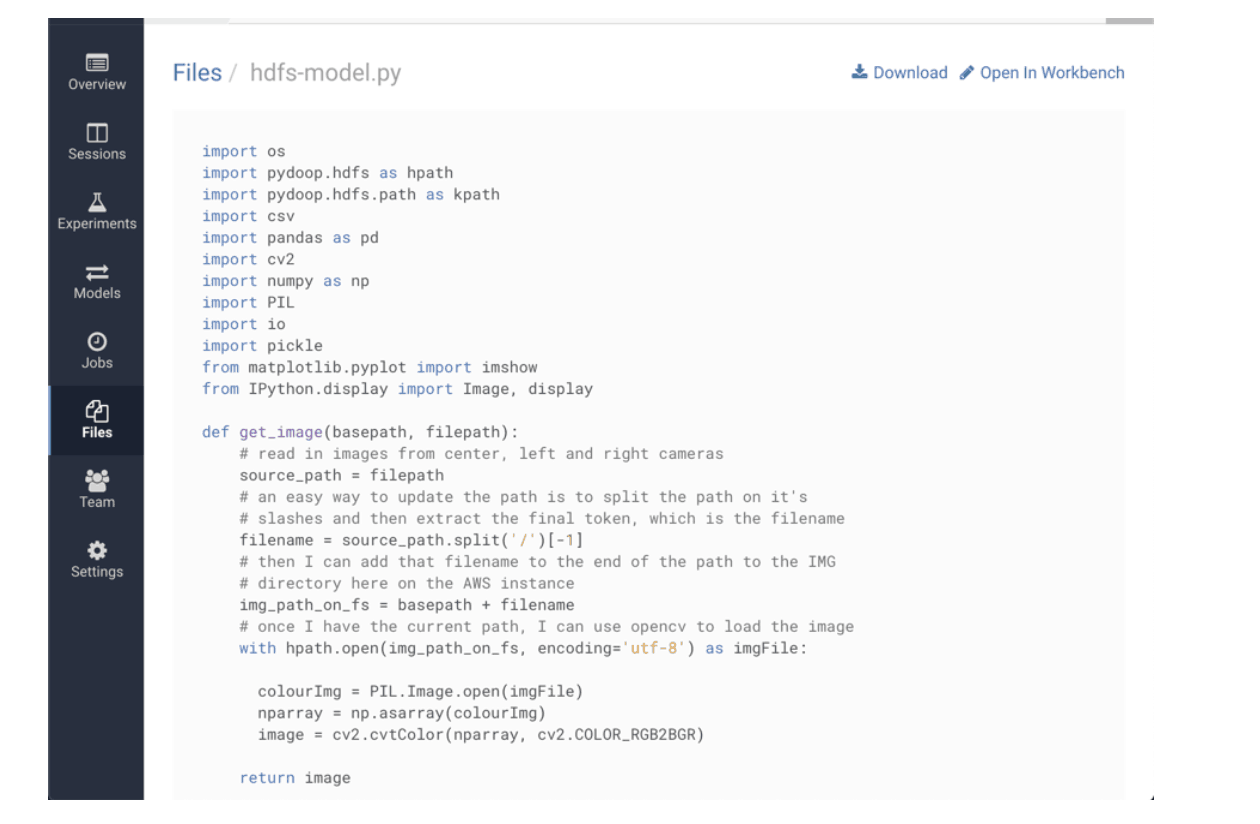
CDSW code on workbench
Data Augmentation for Model Training
Because the racetrack is small and the collected data is sparse, data preprocessing was useful for augmenting it. Data augmentation in the context of ML applications is the process of altering the original data in such a way that we “create” new data by slightly altering the available data. In this project, we used augmentation to increase the data by a factor of two through performing a series of transformations, including mirroring the images and inverting the steering angles. Thus, when the data was collected for the car driving in the clockwise direction, we could infer the steering angles for driving in the counterclockwise direction. The steering angles for the left and right camera images were adjusted by an offset of plus and minus 0.2 radians, so the vehicle would be able to steer back to center when it got too close to the left or right side of the track. Data preprocessing significantly improved the model’s accuracy.
Strategies for Collecting Better Data
Having a lot of data doesn’t always ensure that the quality of the data collected will be good for training a model. To collect training data, we drove the car on our track for three full laps in the counterclockwise direction, three more laps in the opposite direction, and a final lap that focused on smooth turning at each corner of the track. After applying these driving strategies, the model improved significantly: the car went from not being able to complete a single lap around the track to driving unassisted for several laps.
Behavioral Cloning Neural Network Architecture
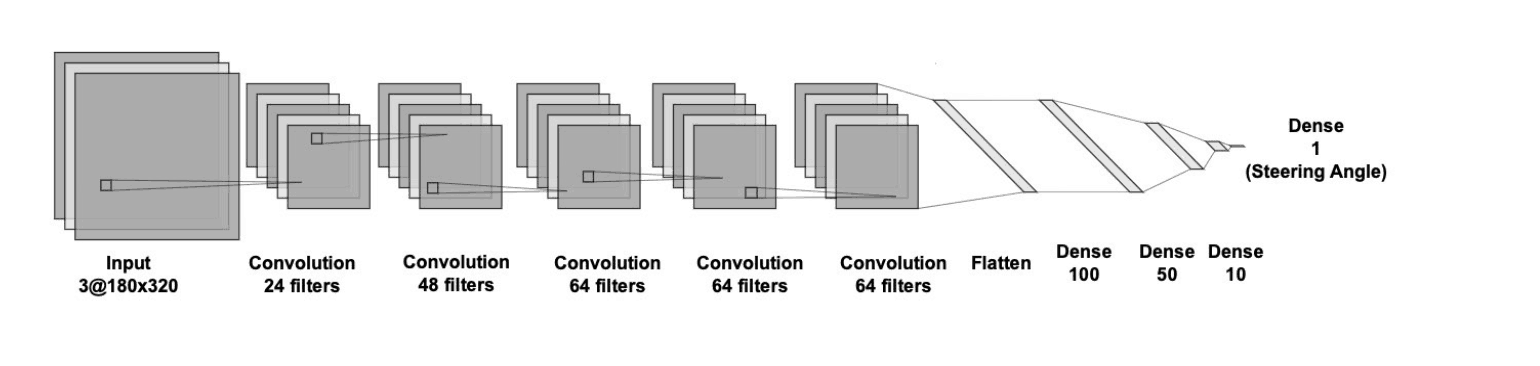
Convolutional Neural Network (CNN) architecture
The neural network architecture consisted of one normalization layer, one cropping layer, five convolution layers, and four fully connected layers. The input to the model was three images: left, center, and right camera images.The normalization layer adjusts the size of the image appropriately to train the model. The cropping layer was used to remove unnecessary features from the image, such as trees and the car’s hood, to improve the model’s accuracy during training. The five convolution layers consisted of filters that are used to extract image features, such as recognizing the black road and white lane boundaries. The filter number for each convolution layer, according to NVIDIA’s publication, was determined through trial and error. The fully connected layers were used to decrease the number of outputs at each layer, culminating in one output. The output layer returned a single real number that represented the predicted steering angle for the car.
The deep learning framework used to implement the behavioral cloning model is Keras, with TensorFlow as its backend. The first layer consists of a lambda layer for taking in the image shape. The second layer is a Cropping2D layer for removing the pixels at the top and bottom of the image to improve the model’s accuracy during training. The next five layers are Conv2D layers for handling the image processing to do feature extraction on the images. The last four layers are Dense fully connected layers to decrease the number of outputs at each layer to eventually have one output for the steering prediction. A sequential neural network model is trained using fit with images and steering labels over 20% validation split and 7 epochs, since that produced low mean squared error for training and validation.
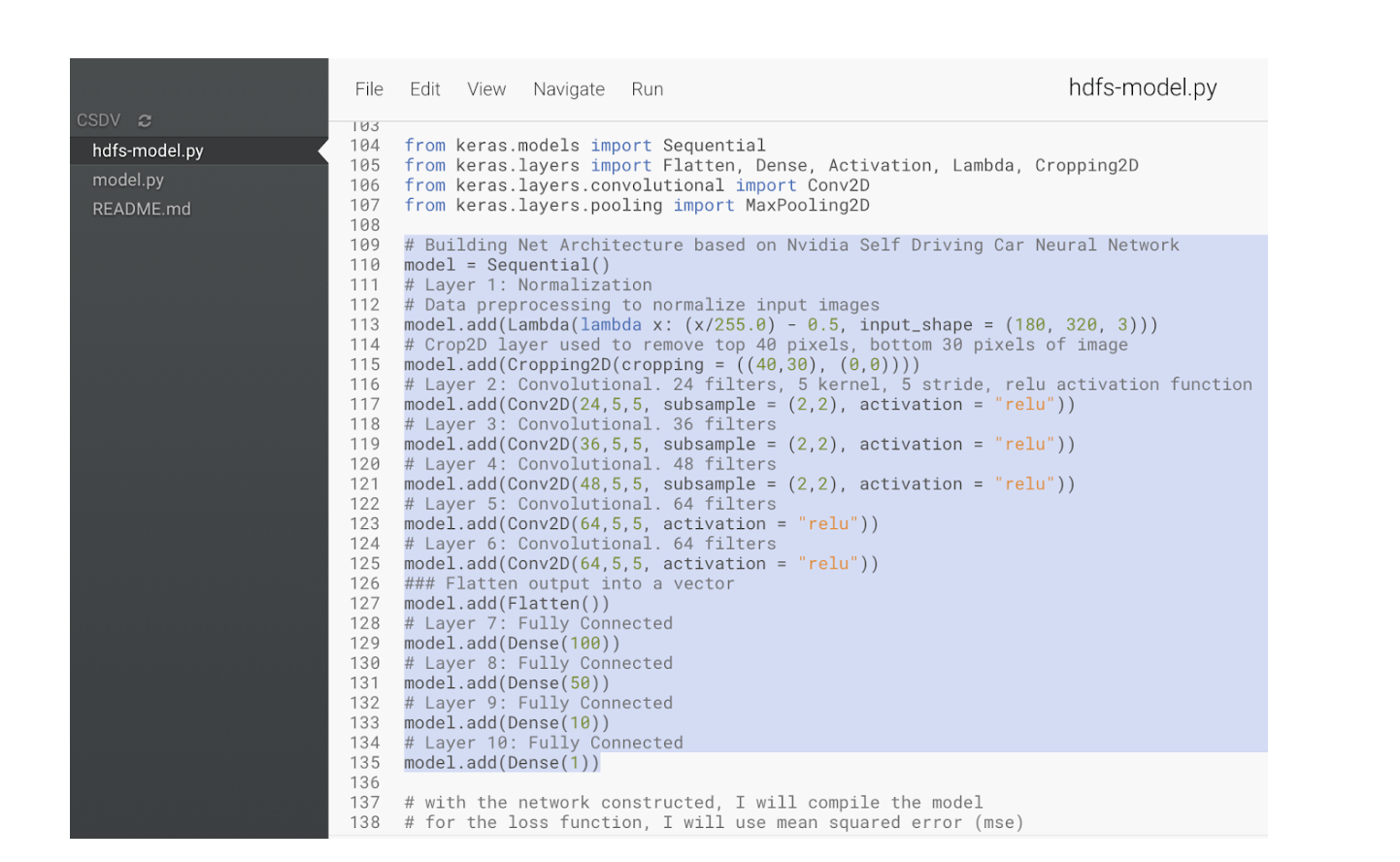
Model architecture code
Deploying a CNN Model with CEM to the Edge
Once you have conquered the challenge of collecting data on the edge and have trained an ML model using the data collected on the edge, the next logical step is to deploy your new asset back to the edge. CEM helps you with deploying models in a fast and reliable manner. Once we’ve trained and tested our model, we can deploy it back onto the Jetson TX2 and use it to make predictions to enable the car to drive autonomously.
We can add a GetHDFS processor to our simple flow in order to pick up our model and use an output port pointed back to CEM and our MiNiFi agent.
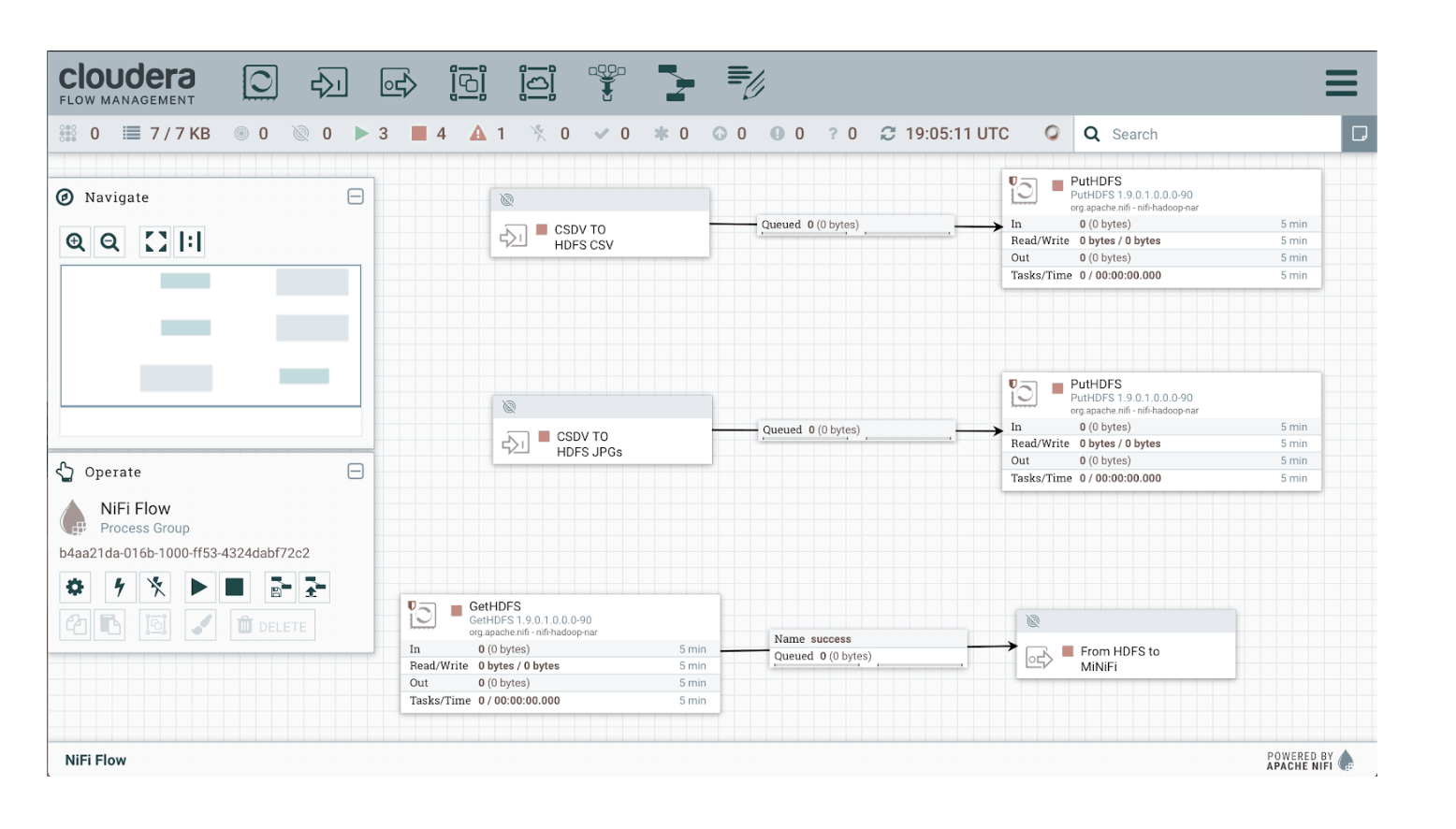
Once the data in NiFi is queued for the output port, it is pulled by MiNiFi flow using a remote process group. This remote process group is configured with the URL of NiFi and the identification of the output port. Lastly, MiNiFi will store the model.h5 on the local disk using PutFile processor. The final step is to enable the car to drive autonomously by using an ExecuteProcess processor to launch the ROS process that loads the model.h5 to perform predictions of the steering angles based on the streamed camera images. And once the ROS auto_mode.launch process is running, the developer can activate autonomous mode by pressing the Y button on the game controller (and deactivate it by pressing the B button). Immediately after activating this mode, the car drives at a constant speed of 5 mph and steers right or left, based on the steering angle prediction from the model.
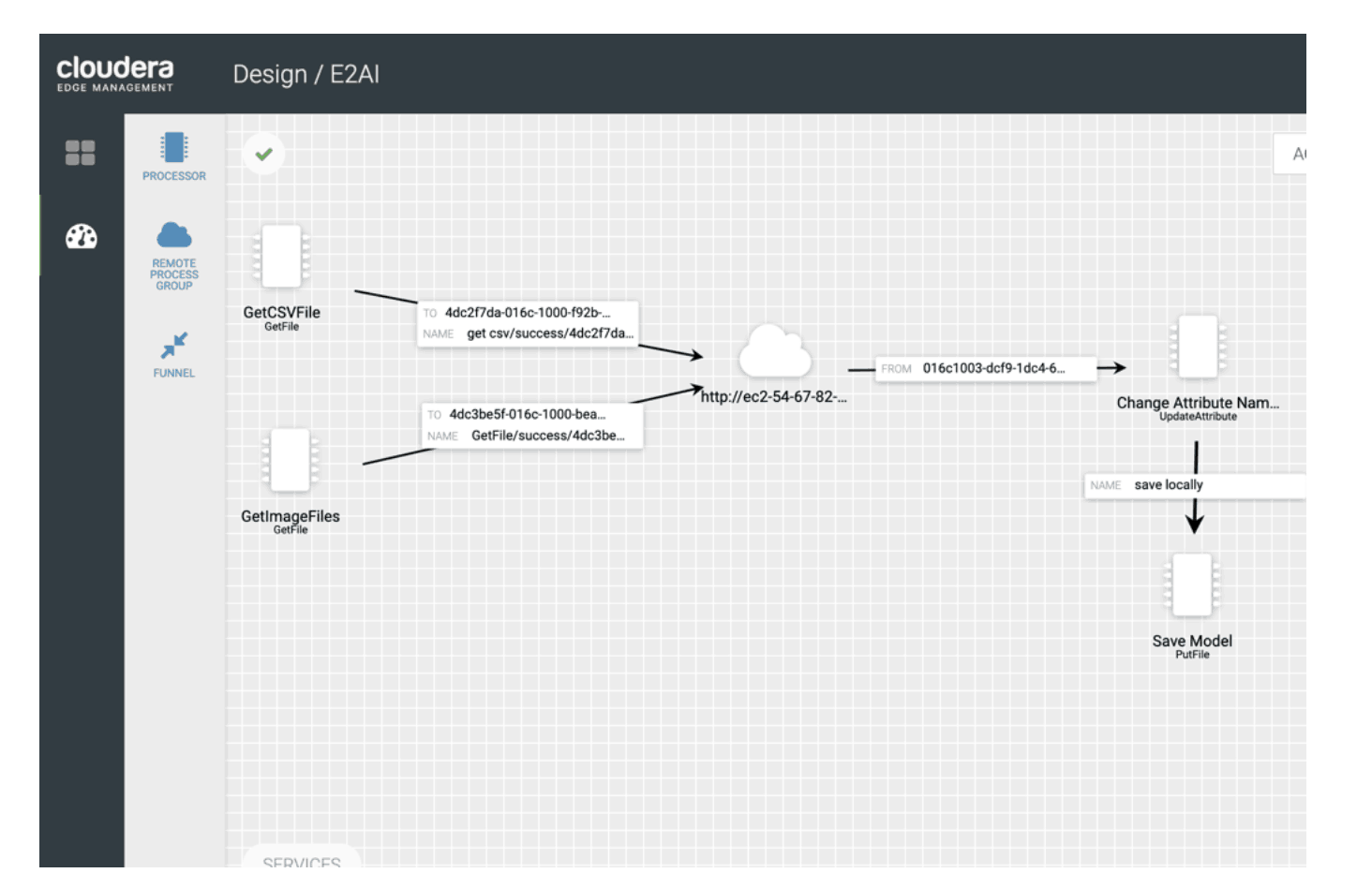
Final working flow EFM UI
Conclusion
We began our edge to AI journey by first collecting data from the edge, then moving it to a data lake using Cloudera DataFlow and CEM, then training a model in CDSW, and finally by deploying it to the car for autonomous mode driving. With minor modifications, this architecture can be extended to collect data from a fleet of cars, to train models using all the data, and to easily deploy it back to all the cars. To replicate the edge to AI cycle showcased in this blog series, follow the Edge2AI autonomous car tutorial.
Editor's Choice

