

Fast moving data and real time analysis present us with some amazing opportunities. Don’t blink—or you’ll miss it! Every organization has some data that happens in real time, whether it is understanding what our users are doing on our websites or watching our systems and equipment as they perform mission critical tasks for us. This real-time data, when captured and analyzed in a timely manner, may deliver tremendous business value. For example:
- In manufacturing, fast-moving data provides the only way to detect—or even predict and prevent—defects in real time before they propagate across an entire production cycle. This will reduce defect rates, increasing product yield. We can also increase effectiveness of preventative maintenance—or move to predictive maintenance—of equipment, reducing the cost of downtime without wasting any value from healthy equipment.
- In telecommunications, fast-moving data is essential when we’re looking to optimize the network, improving quality, user satisfaction, and overall efficiency. With this, we can reduce customer churn and overall network operational costs.
- In financial services, fast-moving data is critical for real-time risk and threat assessments. We can move to predictive fraud and breach prevention, greatly increasing the protection of customer data and financial assets. Without real-time analytics we won’t catch the threats until after they’ve caused significant damage. We can also benefit from real-time stock ticker analytics, and other highly monetizable data assets.
By capitalizing on the business value of fast-moving and real-time analytics, we can do some game changing things. We can reduce costs, eliminate unnecessary work, improve customer satisfaction and experience, and reduce churn. We can get to faster root-cause analysis and become proactive instead of reactive to changes in markets, business operations, and customer behavior. We can get the jump on competition, reduce surprises that cause disruption, have better organizational operational health, and reduce unnecessary waste and cost everywhere.
The need for real-time decision support and automation is clear.
However, there are some key capabilities that will make real-time analytics a practical and applied reality. What we need is:
- An openness to support a wide range in streaming ingest sources, including NiFi, Spark Streaming, Flink, as well as APIs for languages like C++, Java, and Python.
- The ability to support not just “insert” type data changes, but Insert+update patterns as well, to accommodate both new data, and changing data.
- Flexibility for different use cases. Different data streams will have different characteristics, and having a platform flexible enough to adapt, with things like flexible partitioning for example, will be essential in adapting to different source volume characteristics.
On top of these core critical capabilities, we also need the following:
- Petabyte and larger scalability—particularly valuable in predictive analytics use cases where high granularity and deep histories are essential to training AI models to greater precision.
- Flexible use of compute resources on analytics—which is even more important as we start performing multiple different types of analytics, some critical to daily operations and some more exploratory and experimental in nature, and we don’t want to have resource demands collide.
- Ability to handle complex analytic queries—especially when we’re using real-time analytics to augment existing business dashboards and reports with large, complex, long-running business intelligence queries typical for those use cases, and not having the real-time dimension slow these down in any way.
And all of this should ideally be delivered in an easy to deploy and administer data platform available to work in any cloud.
A unique architecture to optimize for real-time data warehousing and business analytics:
Cloudera Data Platform (CDP) offers Apache Kudu as part of our Data Hub cloud service, providing a consistent, dependable way to support the ingestion of data streams into our analytics environment, in real time, and at any scale. CDP also offers the Cloudera Data Warehouse (CDW) as a containerized service with the flexibility to scale up and down as needed, and multiple CDW instances can be configured against the same data to provide different configurations and scaling options to optimize for workload performance and cost. This also achieves workload isolation, so we can run mission critical workloads independent from experimental and exploratory ones and nobody steps on anyone’s toes by accident.
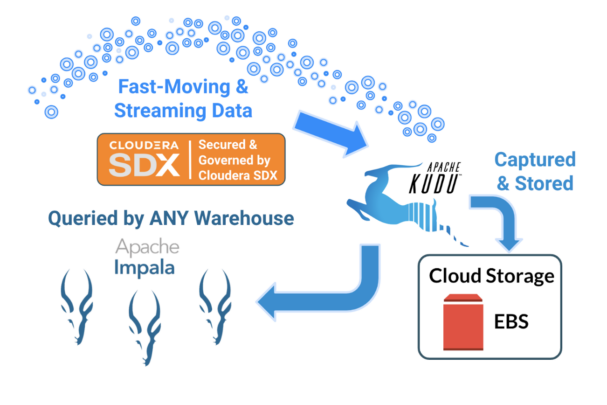
Fig. 1: Kudu & Impala for Real-Time Data Warehousing
Key features of Apache Kudu include:
Support for Apache NiFi, Spark Streaming, and Flink pre-integrated and out of the box. Kudu also has native support for C++, Java, and Python APIs for capturing data streams from applications and components based on those languages. With such a wide range of ingest types, Kudu can get anything you need from any real-time data source.
- Full support for insert and Insert+update syntax for very flexible data stream handling. Being able to capture not just new data, but also changed data, greatly facilitates Change Data Capture (CDC) use cases as well as any other use case involving data that may change over time, and not always be additive.
- Ability to use multiple different flexible partitioning schemes to accommodate any real-time data, regardless of each stream’s particular characteristics. Making sure data is able to land in real time and be accessed just as fast requires a “best fit” partitioning scheme. Kudu has this covered.
Key features of Cloudera Data Warehouse include:
- Powerful Apache Impala query engine capable of handling massive scale data sets and complex, long running enterprise data warehouse (EDW) queries, to support traditional dashboards and reports, augmented by real-time data.
- Containerized service to run both multiple compute clusters against the same data, and to configure each cluster with its own unique characteristics (instance types, initial and growth sizing parameters, and workload aware auto scaling capabilities).
- Full lifecycle support including Cloudera Data Engineering (CDE) for data preparation, Cloudera Data Flow (CDF) for streaming data management, and Cloudera Machine Learning (CML) for easy inclusion of data science and machine learning in the analytics. This is especially necessary when combining real-time data with prepared data, and adding predictive concepts into our augmented dashboards and reports.
CDW integrates Kudu in Data Hub services with containerized Impala to offer easy to deploy and administer, flexible real-time analytics. With this unique architecture, we support stable and consistent ingestion of huge volumes of fast moving data, tougher with flexible, workload-isolated data warehousing services. We get optimized price/performance on complex workloads over massive scale data.
Ready to stop blinking and never miss a beat?
Let’s take a close look at how to get started with CDP, Kudu, CDW, and Impala and develop a game changing real-time analytics platform.
Check out our recent blog on integrating Apache Kudu on Cloudera Data Hub and Apache Impala on Cloudera Data Warehouse to learn how to implement this in your Cloudera Data Platform environment.
Editor's Choice

