

Do you need faster time to value? Does your organization’s success depend on immediate delivery of new reports, applications, or projects? When you go to Central IT for support, are you blocked by insanely long wait times for the resources needed to meet your business goals? If so – you are likely one of the growing group of Line of Business (LoB) professionals forced into creating your own solution – creating your own Shadow IT.
While cloud-native, point-solution data warehouse services may serve your immediate business needs, there are dangers to the corporation as a whole when you do your own IT this way. You already know that a distributed environment is much tougher for your company to manage, secure, and govern. And you also already know siloed data is costly, as that means it will be much tougher to derive novel insights from all of your data by joining data sets. Of course you don’t want to re-create the risks and costs of data silos your organization has spent the last decade trying to eliminate. You also do not want to risk your company-wide cloud consumption costs snowballing out of control. But – you need those mission critical analytics services, and you need them now!
Is there a better option than the obvious ones? Must you be:
- Waiting in line in the Central IT queue and risk getting behind in your business and losing out to competition as a result?
- Building a Shadow IT organization with separate, disconnected data repositories that only serve your line of business’ needs and introduce compliance and security risk for your company, lose your organization’s focus and participation in core business, and see your company ending up paying much more in the end?
- Going to point solutions in the cloud and thereby undo the good your organization has been building for the last several years eliminating data silos to manage security and compliance, expedite value and manage costs with reduction in redundancy?
Yes there is a better choice!
Cloudera Data Warehouse (CDW) is here to save the day! CDW is an integrated data warehouse service within Cloudera Data Platform (CDP). CDP is Cloudera’s new hybrid cloud, multi-function data platform. With CDW, as an integrated service of CDP, your line of business gets immediate resources needed for faster application launches and expedited data access, all while protecting the company’s multi-year investment in centralized data management, security, and governance.
How? By separating the compute, the metadata, and data storage, CDW dynamically adapts to changing workloads and resource requirements, speeding up deployment while effectively managing costs – while preserving a shared access and governance model. This architecture allows IT to safely open up the ability for LoB power users to dynamically spin-up and spin-down resources, meeting the demands of their ad-hoc workload, thereby increasing LoB self-service and agility.
The ability to give LoB users quick access to self-service data warehousing, while ensuring compliance, is the main reason top Financial Services organizations like DBS Bank and others have selected CDW over point solutions. In one institution we recently spoke with, they told us it took them over 30 weeks to procure and deploy a new data warehouse, while with CDW they got everything up and running in just a few seconds (after, of course, a few days obtaining the data migration and policy clearances involved).
Another reason these and other large organizations have chosen CDW as their data warehouse strategy forward is because the clusters are not static – they can auto-scale with variations in query concurrency, so that line of business users like you never have to experience a delay in response. You don’t have to worry about major sizing efforts upfront. At the same time, IT keeps the controls on cost through configuring max auto-scale sizes for compute resources, alongside the auto-suspend and auto-shrink capabilities to downsize once your work is done and the related resources are idle. With CDW you only pay when resources are being used. When not, it auto-shrinks and auto suspends.
Architecture overview
Of high value to existing customers, Cloudera’s Data Warehouse service has a unique, separated architecture.
- Separate storage
Cloudera’s Data Warehouse service allows raw data to be stored in the cloud storage of your choice (S3, ADLSg2). It will be stored in your own namespace, and not force you to move data into someone else’s proprietary file formats or hosted storage. This reduces the risk for your organization long term, in case you want to allow other workloads over the same data or to switch services. Additionally, staying with an open file format is the key to not incurring high costs when making additions or changes in data storage or services down the road.
One of the executives at a large healthcare company in North America that handles clinical trials highlighted this flexibility around storage environment as a core reason for choosing Cloudera for their self-service Data Warehousing strategy. In their case, they had access to 3rd party data stored in Azure, but which was legally restricted to stay in Azure. This brought on a challenge, as most of their clinical trial data and previous research was only done on-prem. With Cloudera, they were able to run workloads where needed and with flexibility to run for as long as a project needed, but then not causing additional costs. Thanks to Cloudera’s hybrid platform, their organizations could partner quickly and easily without major surgery in their existing infrastructure or massive, costly full data-sets migration.
This executive specifically pointed out their relief around that they were also enabled to use open file formats, as opposed to some vendors’ solutions, which force you to store data in their storage space and using their proprietary formats, which would have limited what other tools they could use over their data down the road. So follow the advice of this experienced leader and make sure to look out for the fine print of such solutions, as those are locking you in, especially if you need to do other things with your data or move data to other environments in a flexible way, for instance, to save costs. Storing data in a proprietary, single-workload solution also recreates dangerous data silos all over again, as it locks out other types of workloads over the same shared data. Proprietary file formats mean no one else is invited in!
- Central control of security and governance
The Data Lake service in Cloudera’s Data Platform provides a central place to understand, manage, secure, and govern data assets across the enterprise. This is key for your central IT to stay compliant and not to undo the hard work of eliminating data silos in your organization over the last few years.
When your IT admin registers an environment in CDP, a Data Lake is automatically deployed. The Data Lake provides a persistent security and governance layer for the environment’s workload resources – independent of whether they are long-term or transient. The Data Lake is persisted to your Cloud storage of choice, so even if the Data Lake is shut down, your history, audit trails, lineage and security access models remain.
The Data Lake also manages metadata persistence, so that you can preserve a single truth of shared data across various kinds of workloads (be it Data Warehouses, Machine Learning, or massive ETL pipelines) and independently spin up and down compute resources as needed. A shared Data Lake across workloads is what allows your LoB to also rapidly share data insights and results beyond just your own organization, as both data scientists and BI analysts will touch the same data, but not compete for the same resources.
CDP’s Data Lake is what enables your organization to stay compliant and in sync, protect the company’s investment for unified security and lesser data-silo risk across LoBs.
- Separate compute
This is where the instant and dynamic resource allocation for whatever workload you wish to execute will independently operate over your data in isolation – guided and protected by the Data Lake service. So just in a few seconds you get the resources for compute that you need, while data stays protected and open across your organization. Compare this to the 30 weeks in the financial services organization situation mentioned above. CDW implements a true win-win architecture, for all stakeholders’ and all data involved.
- Hybrid
Cloudera’s data platform is supported in multiple cloud environments and on premise, to allow optimal flexibility in running workloads where it makes the most sense. This allows you to optimize for SLA or cost, and to adapt to changing business conditions down the road without disastrous disruption. So if you run in AWS, and later need to run in Azure (maybe due to a change in regulatory restrictions or pricing), you can easily move to an environment that provides the best options at that point in time.

When you log in, you land on the Cloudera Data Platform home page, where you see the services enabled and available to you, all set up to execute in your organization’s cloud environment. If you want to learn more about CDP and the various services in more depth, please watch this keynote presented by Arun Murthy.
{kind=link}
Through the separation of storage, metadata, and compute CDP enables the clear separation of data, resources, and application ownership. The central data management team owns the Data Lake, IT owns the environments, and LoBs owns the compute environments (and business applications) which utilize the Data Lake. This is the secret sauce that allows your organization to self-serve, while IT can assure SLAs, cost-efficiency, compliance and faster service enablement.
One IT-step away from a life outside the shadows
The first step to use CDW (or any other service in CDP) is to ask IT to set it up to access your cloud environment. To expedite this process, you can prepare a checklist for the IT team which will help them to identify the tasks and shorten the time required to receive their support.

Connecting CDP to your cloud environment is a quick three-step process and usually takes around 10-30 minutes, if the checklist has been met.
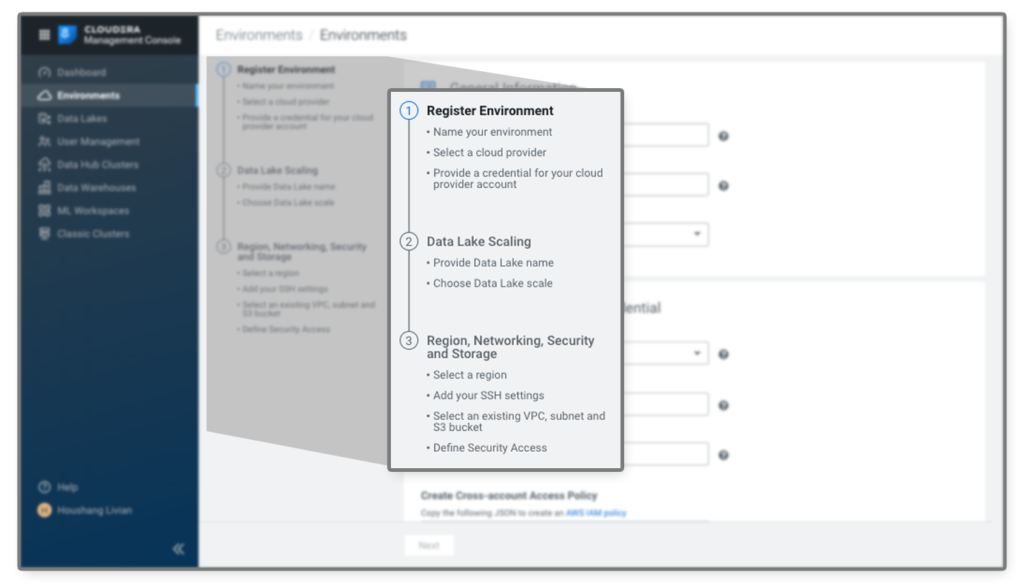
Once your environment is created and connected, ad-hoc and long running services can easily be spun up in your own Virtual Private Cloud (VPC) or VPN. This means that you do not need to rely on someone else’s environment and security, nor do you miss out on important runtime patterns and usage insights that can help optimize cost across environments down the road. This is how quickly your business users can be data warehouse self-service enabled, and yet stay aligned with CIO and CFO requirements.
Get your data in place
The data of interest for your ad-hoc data warehouse services needs to be available in your Cloud storage in your environment (and hence in the Data Lake). If the data is already there, you can move on to launching data warehouse services. If it is not there, you can utilize the Cloudera Replication Manager, in a few steps, to make sure the required data, metadata, and security are made available where you need them.
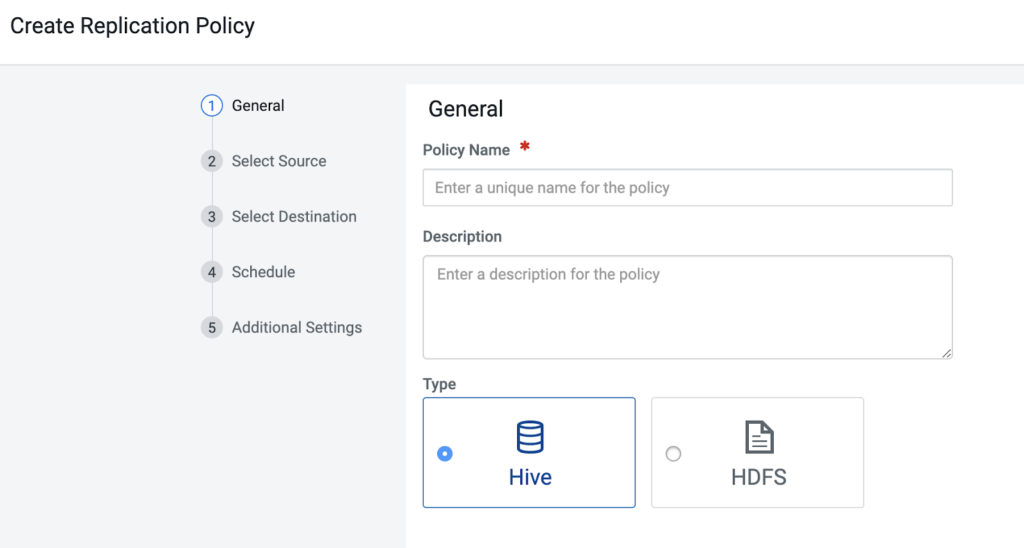
Replication Manager has a five-step migration policy creation tool that makes it easy to get data where it needs to be.
With the help of your IT department, you now have your environment connected to the Cloudera launch services and your data in place – with preserved access model, lineage, and audit controls. You and your peers are now enabled to get what you need, faster, ad-hoc, when you need it – without the burden, cost, or risk of shadow IT.
Start self-service ad-hoc data warehousing
The CDW service is a tool for creating independent virtual data warehouses that enable teams of business analysts to query shared data without competing for resources. This service enables ad-hoc data warehouse spin up, auto-scale, and auto-suspend to make ad-hoc analytics more cost-efficient and easily accessible to all.
It is designed to dramatically reduce the labor and technical ability required to develop new business applications and BI/Analyst reports on the platform. CDW abstracts away the technical details of the tools and infrastructure used to build a business application (e.g. simplify the choice of which SQL engine to use, eliminate the choice of which instance type to use, how many instances to run, what cluster configuration settings to use, when to perform an upgrade, etc.). CDW helps automate the application infrastructure and data foundation setup (including also data set, schema, security, tuning) so you can more quickly focus on your business requirements.
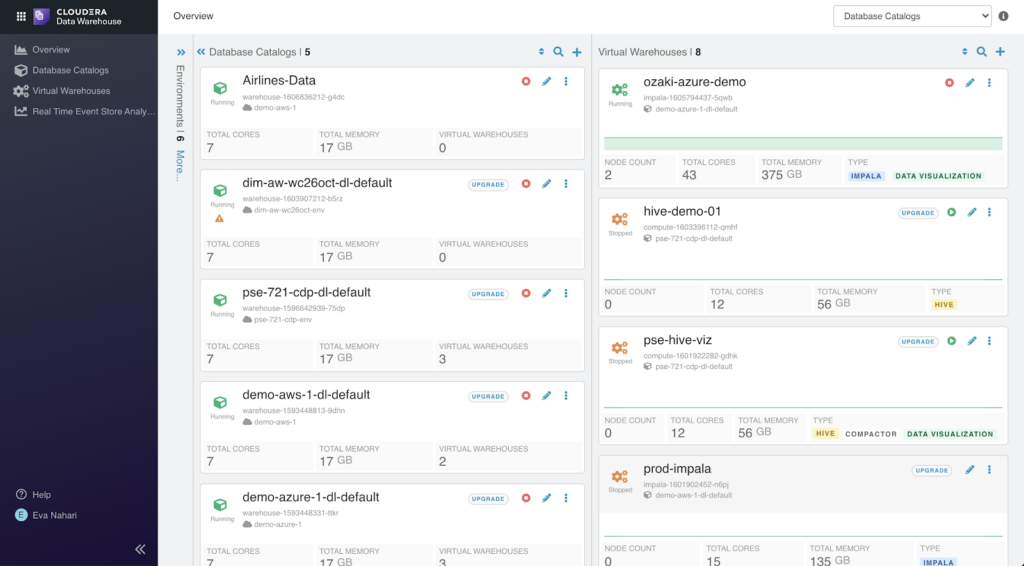
Overview of the data collections in the Data Lake, i.e. Database Catalogs, and the available data warehouse isolated compute resources, i.e. Virtual Warehouses.
Getting an ad-hoc data warehouse up and running is easy, in just a few steps you and your peers can self-serve:
1. Create or select a database catalog for the definition of databases, tables, and columns for your data model required for queries.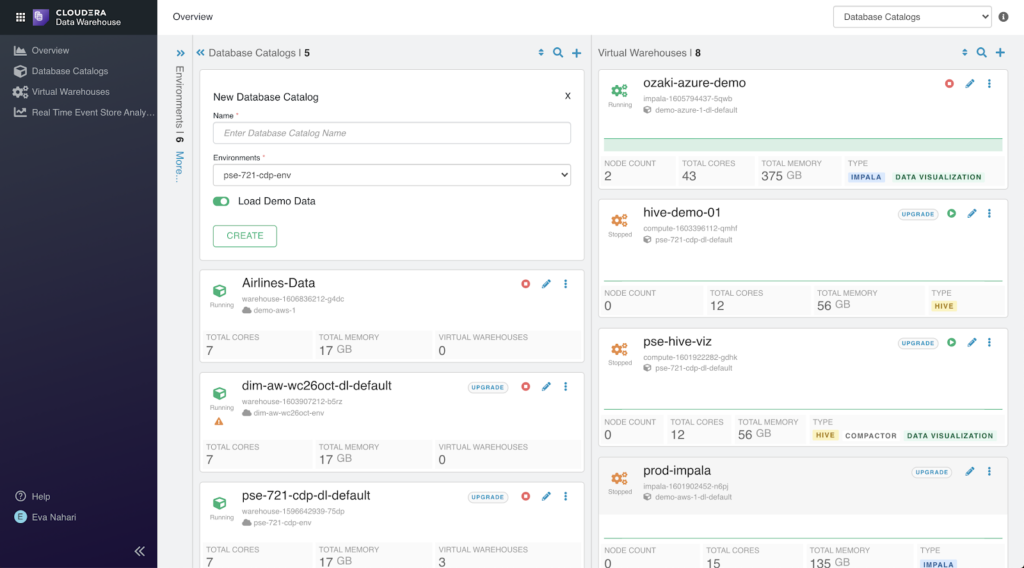
2. Create a new Virtual Warehouse with the Database Catalog you selected above.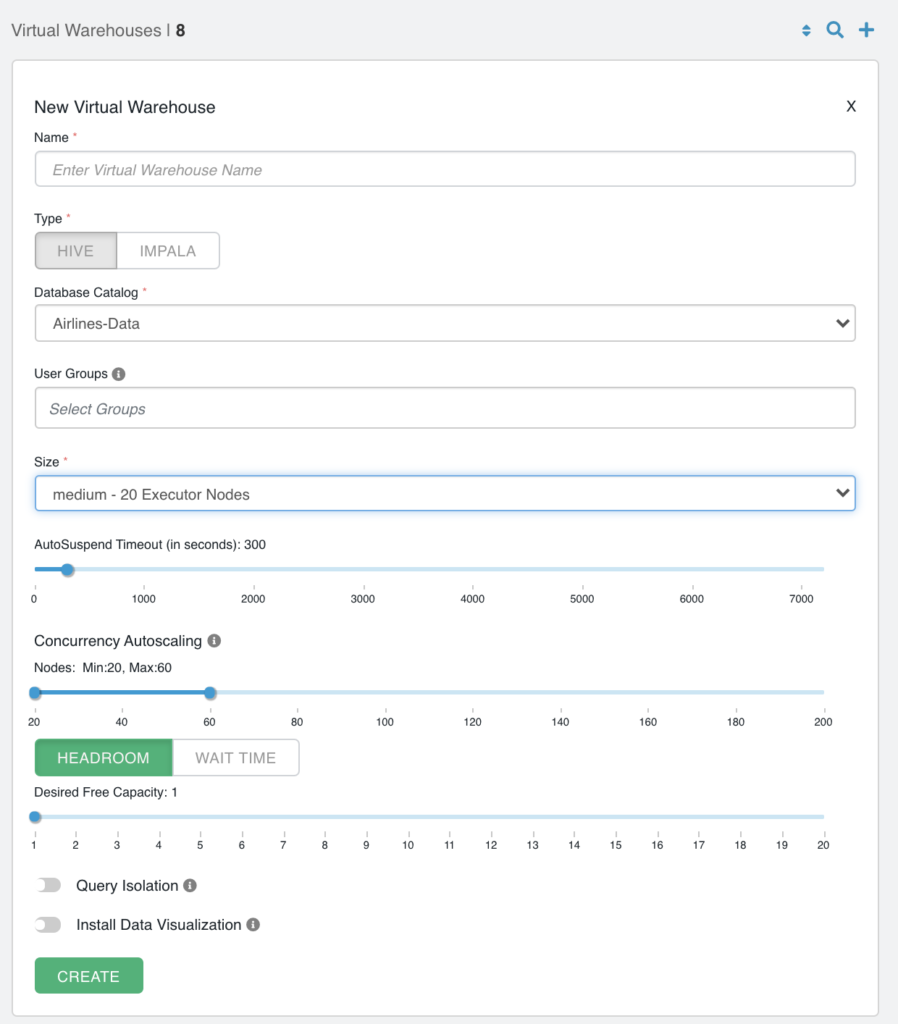
Choose a “t-shirt” size that you estimate to be a good starting point for your Virtual Warehouse. The pre-sized compute should simplify a lot of sizing steps previously needed and save time. Out of the box optimizations are applied for optimal performance given the Cloud instance types being used. No need for further tuning!
3. The only configuration available is optional and has to do with your preferences around scaling the DW Service (e.g. auto-suspend time, auto-scale triggers, etc).
4. What remains is to connect your end user tool to the Virtual Warehouse. From a drop-down menu you can conveniently access the popular SQL Editor HUE or you can kick-start your business decision making by starting building visual applications in Cloudera Data Visualization. You can also choose to copy the JDBC URL or download the jar and use it in your favorite 3rd party tool (e.g. Tableau, Qlik, Power BI, etc).
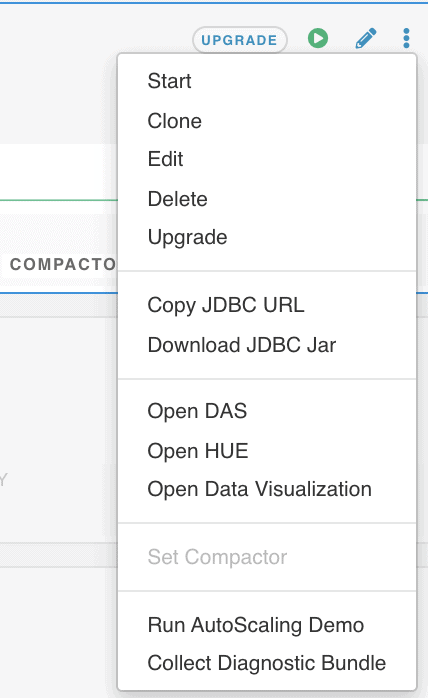
Voila! Your data warehouse is ready. In just a few seconds. With no worry about data loss, security concerns, or being locked into proprietary point solutions or file formats. And with the flexibility to run other workloads over the same data (remember there is the Machine Learning (ML) service too!). The other services utilize the same security models and governance that is set up in the shared Data Lake. You can easily switch over and start your Data Science journey over the same data, if you’d like, or invite the Data Science team to experiment based on your new insights.
Cost-optimization and ease-of-use
Now let’s review some additional aspects of how CDW makes life easier for business users and SQL developers, and how some of these innovations help speed up time to results while also saving your organization money.
Dynamic creation and suspension of Virtual Warehouses and isolation of compute and storage resources enable you to quickly and seamlessly reconfigure your Virtual Warehouse without disrupting the work of your end users.
- Auto-suspend allows you to configure how many seconds of inactivity a virtual warehouse can experience before being automatically suspended. As inactive warehouses do not need to be up, this is a great way to reduce cloud infrastructure costs. Noteworthy: if an end user starts being active again, the virtual warehouse automatically activates again.
- The Nodes option allows you to specify a minimum and a maximum size that this particular DW Service can auto-scale up to. There should be a max, to prevent runaway costs. Note that the service will scale from the t-shirt size (default minimum) to the max size in increments of the t-shirt size selected. This is the best way to scale a warehouse for higher query concurrency.
- Noteworthy is also the auto-shrink capability, which helps save your LoB costs. If the query load starts to decrease, the Virtual Warehouse starts decommissioning compute as it frees up. CDW optimizes query placement in a way that as soon as possible resources will be freed up, as query load goes down. Meaning, during peak load you use extra capacity, as you need to, but immediately after, the resources are auto-decommissioned, and you hence only incur the cost when load is high.
- You have the option to choose an SLA or cost-optimizing trigger for auto-scale: headroom or wait time. Auto-scale events trigger a new t-shirt sized compute resource to be added to your compute pool behind the scenes (i.e. seamless to end-users, BI applications, etc), and without restarts. Headroom triggers this when the desired free capacity limit set is hit. Wait time triggers this when users start experiencing a wait time for their query to start executing equal to the limit set. In other words, do you want proactive or reactive auto-scale to happen – SLA-optimized or cost-optimized?
- As another advantage due to the separated storage and compute architecture of CDW, you can explore and discover data without incurring any compute cost. The metadata (definitions for databases, tables, views, etc) are stored in Database Catalogs separately from the compute cluster. This means that end-user tools such as third-party BI applications, dashboards, or Cloudera query editors (DAS and HUE), can browse tables and query history outside the Virtual Warehouse, and hence you don’t see any “uptime” or any costs incurred for this activity. As a side note, these activities are often estimated to be between two to forty-eight hours for new reports. Remember to look into this aspect of cost if you are still contemplating other options.
Accelerated data discovery & collaboration
You probably know where your frequently used data is, but when you have a new project at hand or a new question that requires data sets that you are not familiar with, you need to quickly find the right data to work with to serve your business. According to a recent study by IDC, Data Workers waste 30% of their time trying to find and ensuring they can trust their data. Helping data workers find their data faster, trust it more, and finish their analytics tasks quicker and with more ease.
Result sets are sometimes disregarded after its first business purpose, or hidden in one single user’s sandbox view. This is another risk with silos, as you can’t freely share answers across organizational borders, you will instead have to re-ask the question again – causing duplicate efforts and associated costs. Tools need to accelerate sharing and collaboration between data workers, data analysts, data scientists, and data citizens.
- HUE is a popular out of the box UI for SQL Developers on Cloudera’s Data Warehouse that further expedites Data Workers common tasks, data discovery, and cross-organizational collaboration. For example,
- The pop-up sample functionality, to give a quick insight into what table content looks like
- The auto-completer that helps speed up query design by auto-completing both commands and table names and columns, as the developer types into the tool
- The popularity hints, enabled through integration between HUE and Atlas. By populating a star-rating for each table, based on usage stats, users see what tables are commonly used and therefore has a higher likelihood of being the right one to use.
- DAS also has valuable SQL-optimizing capabilities that expedites the path to a faster running query. For instance, in DAS you can compare queries to quickly figure out if an optimization has any impact or not, or understand what has changed since previous times when you ran the same query.
- The metadata is not the only end-user related data that persists separately in Cloudera’s Data Warehouse. A user’s query history and saved queries are persisted at the Database Catalog level. Even if HUE or DAS is shut down, and even if the Virtual Warehouse is suspended, the next time the user logs in, the queries and the history are available so they can start where they left off.
Faster Queries
CDW comes with two caching optimizations that greatly speed up time to results: a data cache and a results cache. The first time a user runs a query, the Virtual Warehouse will call on the Database Catalog service and get information about where the data and tables are located in your Cloud Storage (e.g. S3 bucket). The Virtual Warehouse will then fetch the files from the Cloud Storage to the local disk, in the data cache, and execute the query. The results are then written locally to the results cache. A 3rd party tool (e.g. Tableau, Qlik, Logi, etc), or in our example DAS, can then read and display the results to the end user.
Let’s say the first time a query executes, and the query takes 14 seconds.
select month, count(*), avg(airtime), avg(actualelapsedtime), avg(distance) from airlines.flights where rand() > 0 group by month;
When the same query runs again, over the same data, optimization is applied to just fetch what is already in the results cache. No additional compute work is required. This, in our example, would take 4 seconds. If instead a different query is executed, but over the same data, another optimization applies that utilizes data already in the data cache, and thereby prevents the same data transfer from cloud storage from happening multiple times.
select month, count(*), sum(airtime), avg(actualelapsedtime), sum(distance) from airlines.flights where rand() > 0 group by month;
In our example, if you changed your query to include SUM instead of AVG, over the same columns, it would utilize the data cache and deliver a speedy return of 5 seconds.
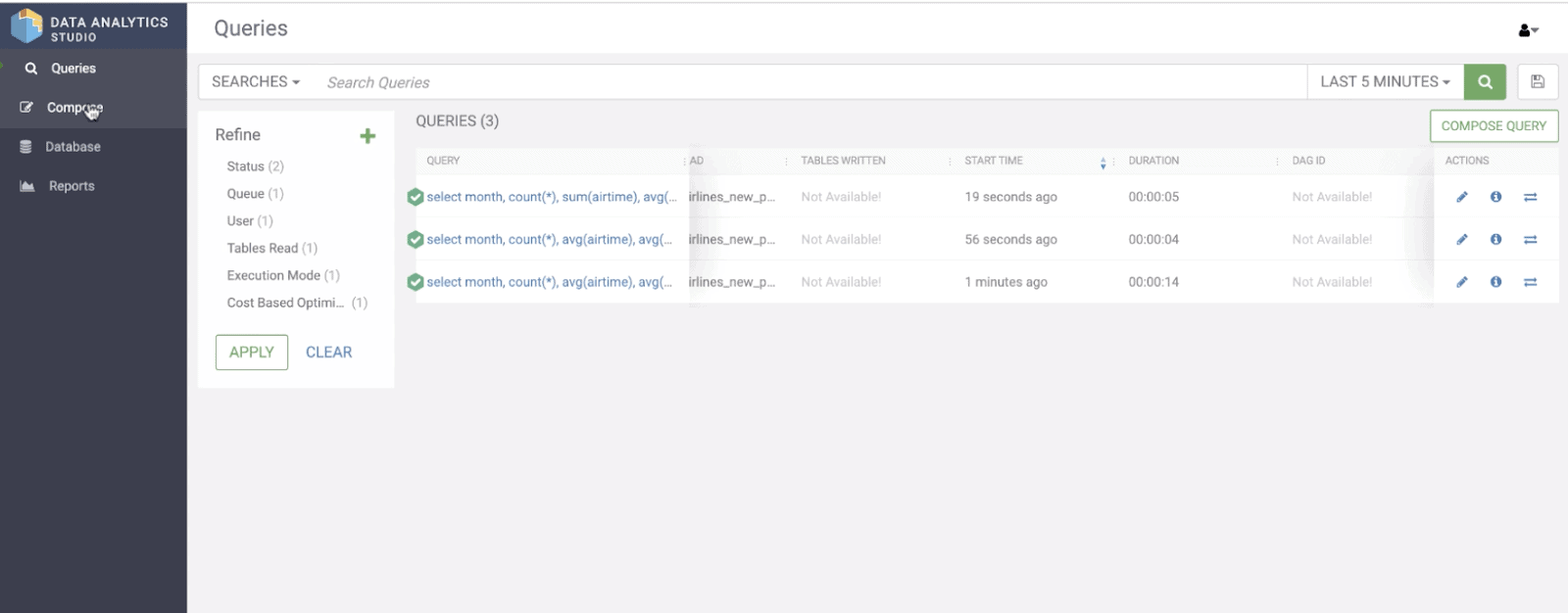
Duration times for first run and re-run of the original query, and run of modified query
The built-in caching in CDW allows for faster time to result, and also means less compute time spent – a win for the end user seeking speedy responses, as well as from an overall cost perspective. Currently, the data cache applies to both the Data Warehouse and Data Mart flavors of CDW (i.e. Hive and Impala), but result caching is only currently supported for the Data Warehouse flavor (i.e. Hive) at this moment.
Towards self-serve productivity out of the IT shadows
Cloudera Data Platform with its integrated services, such as CDW, provides your organization with a seamlessly integrated ecosystem of multiple analytics engines enabled to run across shared data under a shared security and governance model. This unified data platform with a modern data warehouse service will enable your business users to run ad-hoc queries, run reports, and build and view dashboards with fewer interruptions, faster time to results, at a lower and controllable cost. You do not need to wait for IT. Their processes are no longer a hindrance to efficient and agile business intelligence. And yesterday’s escalations from your CIO or CFO about compliance breach or runaway costs will not be filling up your inbox anymore.
To learn more about Cloudera Data Warehouse please visit the Cloudera Data Warehouse Product Page, or for more technical information, explore the Cloudera Data Warehouse product documentation. You may also visit the data warehouse section on Discover CDP.
Editor's Choice

