

Why worry about costs with cloud-native data warehousing?
Have you been burned by the unexpected costs of a cloud data warehouse? If so, you know about the failed economics of some cloud-native solutions on the market today. If not, before adopting a cloud data warehouse, consider the true costs of a cloud-native data warehouse.
Data warehouses have been broadly adopted to provide timely reports and valuable insights. However, traditional deployments are notoriously cumbersome and cost-prohibitive at large scales. They require skilled central IT teams to tackle technical complexities and long lead times in planning, procuring, and provisioning. Some data warehousing solutions such as appliances and engineered systems have attempted to overcome these problems, but with limited success.
Recently, cloud-native data warehouses changed the data warehousing and business intelligence landscape. Appealing directly to end-users in the Lines of Business (LOBs), these solutions can dramatically shorten time to value, lower administrative burdens, and promise continuous agility in response to changing business demands. Expected cost benefits, however, often do not materialize. Instead, you face runaway operational costs. Continuous resource consumption in the cloud (billable on-demand by a running clock) makes no sense today because a better option is available: resource consumption that starts when you need it and stops when you don’t. Cloud-native warehouses that fail economically usually don’t do a good job optimizing cloud resources as part of their core functionality. The providers, having never contributed to the core functionality, often don’t have extensive engineering knowledge of the functionality. These providers simply market the core functionality and inadvertently add costs. These costs impede the adoption of cloud-native data warehouses.
What is Cloudera Data Warehouse (CDW)?
Drawing on more than a decade of experience in building and deploying massive scale data platforms on economical budgets, Cloudera has designed and delivered a cost-cutting cloud-native solution – Cloudera Data Warehouse (CDW), part of the new Cloudera Data Platform (CDP). CDW was designed to aggressively keep cloud costs under control. Watch this video to get an overview of CDW.
CDW includes two highly scalable and performant Apache open-source engines – Impala and Hive LLAP – that have proven themselves in hundreds of enterprises for business-critical data warehousing. CDW user interfaces and simplified administration capabilities help simplify adoption. Many tasks that often require expensive technical help are now self-service because it leverages the elastic cloud-native capabilities of CDP.
What factors affect costs in cloud-native data warehousing?
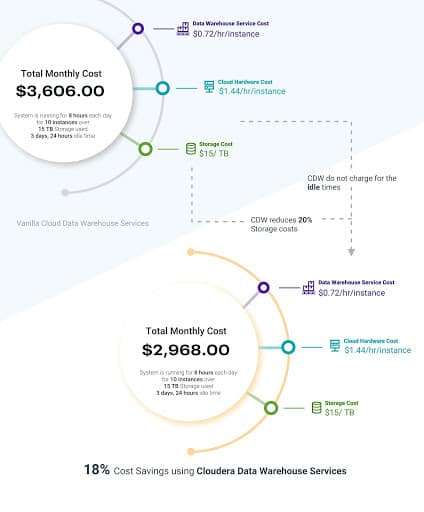
Generally, if five LOB users use the data warehouse on a public cloud for eight hours a day for one month, you pay for the use of the service and the associated cloud hardware resources (compute and storage) for this period. So, for example, assume your data warehouse service costs $0.72 / hour per compute instance, the associated cloud hardware costs $1.44 / hour per compute instance and storage costs $15 / TB per month. If the five LOB users use ten instance units and 10 TB of data, you will be billed as follows:
- $1152 for data warehousing software = $(($0.72 / hour x (8 hours x 5 days x 4 weeks) x 10 instances)
- $2304 for the cloud hardware instances = $(($1.44 / hour x (8 hours x 5 days x 4 weeks) x 10 instances)
- $150 for storage use = $15 / TB / month x 10 TB
The bill totals $3606 on a monthly basis for just a small number of users of a moderately sized data warehouse service. Multiply this by the typical number of users (often in the hundreds) of a production-grade data warehouse. Clearly, the data warehouse service has a direct and major impact on the total costs. Therefore, optimizing the performance of the cloud-native data warehouse saves time and money. Lowering resource consumption by using elastic compute and compact storage formats also saves money.
CDW tackles the threat of cost overruns head-on with many built-in, cost-conscious features that constantly look for time and resource optimizations. In the above example, CDW could have cut costs by 18% for the duration that the system was idle. For example,
- If the system was intermittently idle during the month for a total of 24 hours (3 working days), CDW would have cut the compute costs by about $518 (($0.72 x 24 x 10 )+ ($1.44 X 24 x 10)).
- Similarly, CDW’s use of efficient file formats would have compressed the data dramatically by as much as 80%, thereby cutting the storage costs to about 20% of the $150 = $120 in the example above.
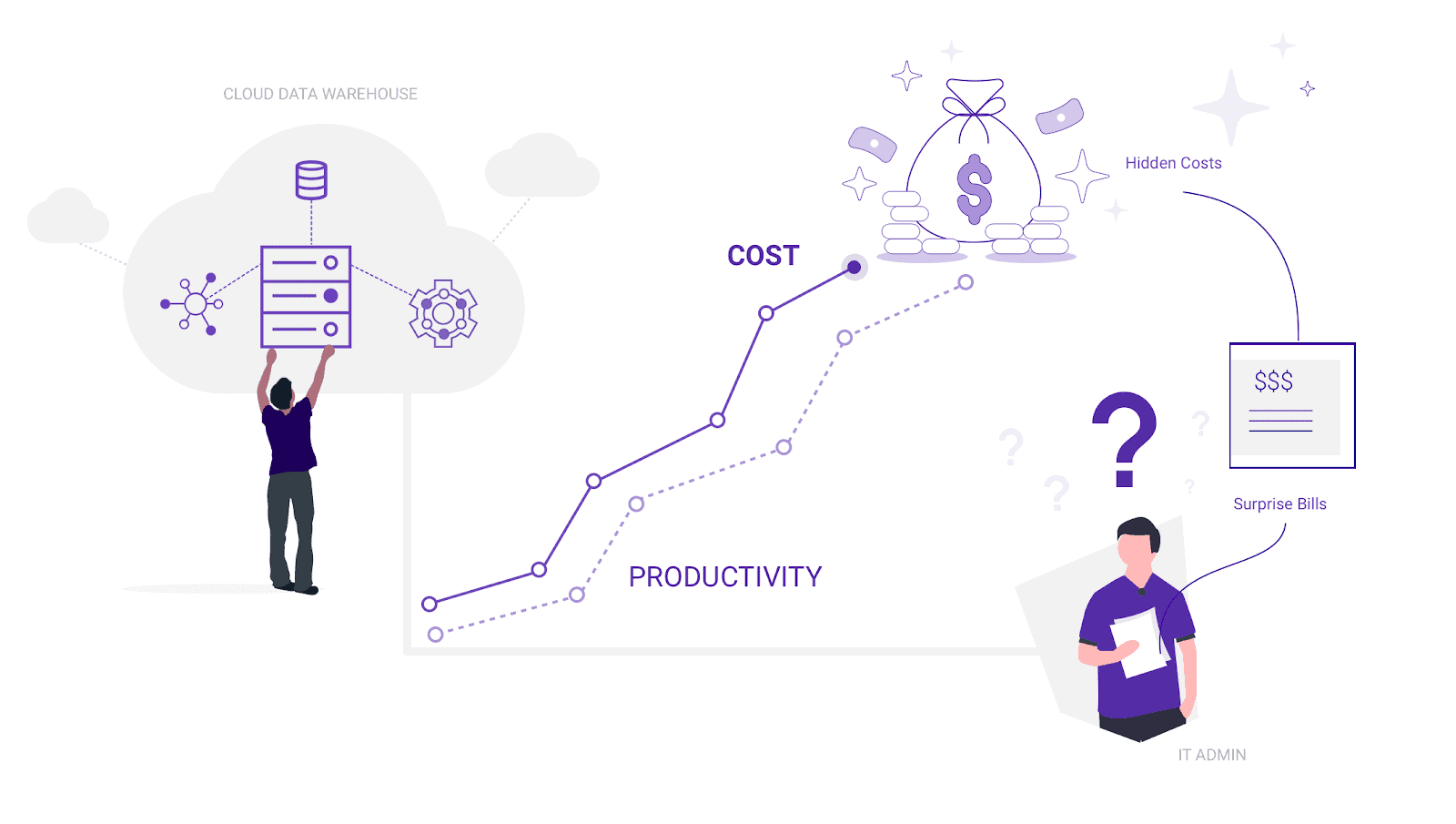
Today, enterprises want data warehouses that support on-demand consumption. Users get billed for every unit of time or storage resource that they consume as part of a service. Costs can easily spin out of control.
Which technical capabilities make CDW cost-efficient?
CDW is built on top of CDP and has many cutting edge features to provide an excellent data warehousing user experience. For an overview of CDW’s architecture, see DW Built for the cloud. The following capabilities are key to CDW’s cost efficiencies.
Simplified provisioning features save time, service costs, and compute costs when you initially spin up a CDW cluster. Days or weeks of provisioning a traditional data warehouse by a highly paid administrator is reduced to seconds. A template automates the initial set up. Beyond the initial setup, no human intervention is needed to start (or suspend) the cluster when users log on (or off) the cluster. A containerized framework orchestrated by Kubernetes constantly monitors user workloads and enables the fast, agile, and automated provisioning.
CDW architecture is elastic and simplifies capacity planning. CDW cluster capacity changes to meet user demands on the fly. You don’t need a highly skilled administrator to add nodes to the cluster and replicate data to increase capacity. This capability, powered by the Kubernetes based containerized framework, is called auto-scaling and auto-shrinking. In other words, the compute resources come alive only when needed and as needed. The resources contract when demand slows, and stop when demand dies. As compute resources expand with demand, cost overruns are capped by a resource ceiling and by dynamically scaling back as demand wanes.
CDW minimizes contention. In a multi-tenant environment, many users access the same data sources. A bad query that scans billions of rows, for example, can impact performance for all users. Often you may have several of these rogue scans. Sophisticated tools such as CDW’s workload manager quickly identifies contention from rogue scans and recommends mitigations. Often CDW suggests isolating rogue or (VIP) workloads into separate compute instances called Virtual Warehouses that share the same data. CDW can move workloads to their dedicated Virtual Warehouses and reduce contention. Optimizing resource use through isolation is more cost-efficient than the traditional approach of sharing resources in multi-tenant data warehouses.
CDW optimizes storage. CDW’s engines such as Impala and Hive low-latency analytical processing (LLAP) directly operate on extremely compact open file formats, such as Parquet and ORC. These file formats not only help avoid data duplication into proprietary storage formats but also provide highly efficient storage formats. Multiple analytical engines (data warehousing, machine learning, data engineering, and so on) can operate on the same data in these file formats. The very high degree of compression built into these file formats reduces storage space and time to access storage.
CDW is built for high performance. CDW has two very high performance massively parallel processing (MPP) query engines – Impala and HIVE LLAP. These engines have a proven history of powering mission-critical data warehouses in many demanding situations. In a bare-metal environment, these engines relied on data being
physically located as close as possible to the compute engine. Data locality improved the performance of data warehouse processing but made resource scaling difficult and expensive because the resources were statically allocated. With the separation of compute and storage, CDW engines leverage newer techniques such as compute-only scaling and efficient caching of shared data. These techniques range from distributing concurrent query for overall throughput to metadata caching, data caching, and results caching. These techniques directly reduce costs.
Security is centralized. The Shared Data Experience (SDX) provides consistent security, governance, and control for widely dispersed data. Centralized governance greatly facilitates compliance with data regulations such as GDPR, HIPAA, PII, and so on that often are big expenses. For example, one of our financial services customers spends $31M a year on compliance. Compliance costs are relatively low when you use CDW because you set up security and governance just once. You have a centralized data catalog and schema registry. The time IT spends on maintaining the data is greatly reduced. When data moves, CDW intelligently takes the security and governance with it. CDW has been designed for a good user experience, as well as for cost and overall system efficiencies. CDW saves time and resources for end-user workloads but does not compromise metadata availability.
Security is always on. Although the always-on SDX means long resource usage, it does not mean inordinate costs. SDX uses lightweight compute resources (with much lower unit costs) compared to the data warehouse service compute resources.
How does CDW actually deliver on the promises of cost savings?
Two Cloudera customers slashed cloud-native data warehousing costs by adopting CDW. The names of these customers have been changed to protect their identity.
Data Inc realizes cost savings through efficient compute cycles in CDW
A LOB in Data Inc, one of the largest data providers based in the US, serves the data and analytical needs of customers in the financial services industry. Data Inc spends more than $300K / year on a cloud-based data warehousing software that supports large scale ETL (data curation) jobs that prepare data for their customers. They also spend an additional $2.5 million / year in cloud infrastructure costs (compute + storage). Data Inc has become quite adept in cutting costs while not compromising on quality of service. For example, it aggressively uses spot instances from its cloud provider for its service, but it protects itself from sudden termination of these instances by developing in-house tools that provide backup resources on-demand.
Despite the level of sophistication in building cost-efficient tools, Data Inc is still heavily dependent on the underlying data warehousing service to provide consumption efficiencies. Its existing data warehousing service is a 40-node system and is quite static. Compute nodes can only be provisioned manually and the storage is based on the traditional file system. Data Inc was very keen to modernize this data warehouse service and based on its cloud vendor’s recommendation, they tried out the cloud provider’s house offering. Sadly, the house offering fell short in multiple ways – no workload management, no dedicated security/metadata management unless the entire cluster is ‘always on’, poor cluster management control plane, and no dynamic provisioning and scaling (provision / de-provision on-demand per workload needs). In the end, due to significant limitations in the cloud provider’s house offering, mainly the inferior data warehouse architecture and feature set, Data Inc could not consider this service as a financially viable solution.
Meanwhile, CDW emerged as an attractive alternative. Using CDW, Data Inc is now able to tackle the runaway cost challenges by taking advantage of CDW’s key cost-conscious features. CDW harnesses the power of cloud hardware instances only when needed. Data Inc no longer needs an expensive administrator to manually provision and scale the shared cluster. They no longer have to deal with rogue queries that tend to use more than 50% of the cluster resource and dramatically drive up the resource costs. CDW’s virtual warehouses start/suspend/resume/scale is fully automated to ensure optimal resource utilization and reduction in costs during idle times. Virtual warehouses can also be sized and dedicated to the rogue queries to enable optimal resource usage and cost efficiencies. Also, separating security and metadata services into separate (lightweight and cheaper) cloud instances ensures non-stop metadata availability without the uptime of the entire cluster.
Data Inc estimates these features from CDW can cut its costs by at least 66%, bringing down their annual expense to well below $1M (far less than the $2.8 M that they are currently spending). Data Inc also sees tremendous growth potential for this service as they sign up more clients and are comfortable that their cost structure will remain under control.
Finally, Data Inc is happy with their choice of CDW over the cloud provider’s house offering. The monthly costs of CDW compared to the cost of the cloud provider’s house offering is significantly lower. The pricing of the house offering includes costs of data scanning and storage, looking up data catalogs, and storing and retrieving metadata.
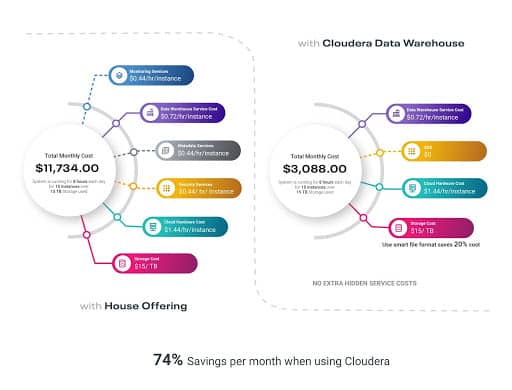
Data Inc performed a cost analysis of their cloud provider’s house offering using the cloud provider’s own pricing calculator. Using the same criteria as the example early in this article ( 10 instances for an 8 hours / day x 5 days x 4 weeks and 10 TB of stored data) , costs were as follows:
- $8,100 / month for the data warehousing (ETL) services
- $2,300 / month for the cloud hardware costs
- $150 / month for the cloud storage
- $5,394 / month for storage access costs (scan, read, write)
- $700 / month for security and metadata service
- $90 / month for monitoring services
This totals $11,734 for the cloud provider’s house offering vs $2,968 from CDW!
Asia Telecom leverages CDW’s efficient caching to save storage and run time costs
In a different scenario, another customer in the Asia Pacific region, Asia Telecom, operates one of the largest mobile, land-line, and broadband networks in the region. Asia Telecom’s data volumes are enormous – upwards of several hundred Terabytes of input data per day – as it deals with analysis of business and operations data from backend systems and network equipment. Asia Telecom trades off data availability for lower storage costs by using cheaper cloud storage that is about one-fifth of the costs of regular cloud object-store like S3. While data unavailability can range from a few minutes to hours due to slow access from low cost storage, it is still acceptable for some workloads. Asia Telecom is looking to CDW on CDP since its separation of storage and compute architecture lends itself well to accessing various cloud storage tiers from any of the provisioned compute resources (virtual warehouses). Asia Telecom has started their CDW journey by leveraging regular S3 object-store but is working closely with Cloudera to leverage lower-cost cloud storage as well in the next phase of their journey with CDW.
Moreover, Asia Telecom is excited to leverage CDW’s caching technologies as one of the ways to speed up access from slower storage tiers. Asia Telecom is happy to see that the caching technology is very cost-effective too because it can leverage the fast SSDs already available as local-store in the compute instances used by the virtual warehouses. The caching capabilities will allow them to balance their SLA demands even with lower-cost cloud storage. Asia Telecom has already started realizing the benefits of faster query execution (resulting in lower compute costs) due to these caching techniques with the regular S3 object store
- Metadata caching is enabling quick access to actual data sets from cloud storage due to fast lookups
- Data caching is allowing fast retrieval of frequently accessed data sets from memory
- Results caching is helping them provide quick answers to repetitive queries without using expensive compute resources
- Materialized views is allowing them to provide quick answers to frequently calculated measures
In the past, Asia Telecom has often struggled in meeting expected SLAs from its data warehouse service due to widespread use and unpredictable demands. The workload management capabilities built into CDP has helped Asia Telecom monitor the VIP workloads closely and get deep insights and recommendations on improving SLAs of these workloads. The primary solution has been to separate the VIP workloads into their own dedicated virtual warehouses to avoid resource contention and improve SLAs. The workload manager recommendations alone has helped Asia Telecom recoup a whopping 15% of the data warehouse operation’s resource costs.
What makes CDW unique and cost attractive?
In conclusion, CDW leverages key technologies such as containers, Kubernetes, cloud storage, caching, and powerful multi-threaded, massively parallel SQL engines to provide high performance and elastic data warehousing service in a cost-conscious manner. The following summary covers key CDW differentiators:
Elastic on-demand – Besides the separation of compute and storage you expect from a cloud data warehouse service, CDW also provides automated provisioning/scaling/shrinking of its compute resources (as virtual warehouses). This enables high levels of elasticity that dramatically improves resource utilization and lowers costs. Contrast this with data warehousing services provided as house offerings from some of the leading cloud providers these offerings are simply unable to break down the static resource allocation problem. They struggle to provide the needed elasticity that CDW provides, and consequently cannot lower the cloud costs of running a business-critical data warehousing service.
Always-on but economical security and metadata – CDW’s capability to separate metadata and security services into a lightweight, lower-cost resources, is the key to continuous metadata and security without continuously running the entire data warehouse compute infrastructure. This is in sharp contrast to the solutions from leading cloud providers who make always-on security and metadata dependent on entire clusters being always-on! The cost differential due to the two distinct approaches is very obvious at this point. Even when security services are offered as a separate service, they charge significantly extra for it.
Powerful database engines – CDW uses two of the leading open-source data warehousing SQL engines (Impala and HIVE LLAP) that take in the latest innovations from Cloudera and other contributing organizations. These innovations in query processing and caching techniques make CDW extremely cost-efficient compared to the house offerings from the cloud providers. The SQL engines from cloud providers are based on older technologies. These SQL engines do not undergo rapid innovations, so they tend to lag behind.
Workload management – Finally, CDW uses an extremely powerful and sophisticated workload management service that dramatically improves the overall visibility and health of the various workloads. This is in stark contrast to missing functionalities in the house offerings from cloud providers. At best, the cloud providers offer some monitoring service at the hardware level – again at an extra cost.
In conclusion, CDW is on a path to help customers realize the true benefits of the cloud in a cost-conscious manner. Our journey has just begun with a promise of continuous industry-leading innovations that will drive down costs and improve efficiencies, thereby offering a delightful total cost of ownership experience.
What you can explore next:
You can visit the Cloudera Data Warehouse product content on Cloudera’s website and explore use cases, features and capabilities of CDW. For a deeper dive, please check out the Cloudera Data Warehouse product documentation and the CDP Core Concepts documentation. For demos and more about the platform, you can visit here and learn more about CDP.
Editor's Choice

