

Introduction
dbt allows data teams to produce trusted data sets for reporting, ML modeling, and operational workflows using SQL, with a simple workflow that follows software engineering best practices like modularity, portability, and continuous integration/continuous development (CI/CD). We’re excited to announce the general availability of the open source adapters for dbt for all the engines in CDP—Apache Hive, Apache Impala, and Apache Spark, with added support for Apache Livy and Cloudera Data Engineering. Using these adapters, Cloudera customers can use dbt to collaborate, test, deploy, and document their data transformation and analytic pipelines on CDP Public Cloud, CDP One, and CDP Private Cloud.
Cloudera’s mission, values, and culture have long centered around using open source engines on open data and table formats to enable customers to build flexible and open data lakes. Recently, we became the first and only open data lakehouse with support for multiple engines on the same data with the general availability of Apache Iceberg in Cloudera Data Platform (CDP).
To make it easy to start using dbt on the Cloudera Data Platform (CDP), we’ve packaged our open source adapters and dbt Core in a fully tested and certified downloadable package. We’ve also made it simple to integrate dbt seamlessly with CDP’s governance, security, and SDX capabilities. With this announcement, we welcome our customer data teams to streamline data transformation pipelines in their open data lakehouse using any engine on top of data in any format in any form factor and deliver high quality data that their business can trust.
The Open Data Lakehouse
In an organization with multiple teams and business units, there are a variety of data stacks with tools and query engines based on the preferences and requirements of different users. When different use cases require different query engines to be used on the same data, complicated data replication mechanisms need to be set up and maintained in order for data to be consistently available to different teams.
A key aspect of an open lakehouse is giving data teams the freedom to use multiple engines over the same data, eliminating the need for data replication for different use cases. However, different teams and business units have different processes for building and managing their data transformations and analytics pipelines. This variety can result in a lack of standardization, leading to data duplication and inconsistency. That’s why there’s a growing need for a central, transparent, version-controlled repository with a consistent Software Development Lifecycle (SDLC) experience for data transformation pipelines across data teams, business functions, and engines. Streamlining the SDLC has been shown to speed up the delivery of data projects and increase transparency and auditability, leading to a more trusted, data-driven organization.
Cloudera builds dbt adaptors for all engines in the open data lakehouse
dbt offers this consistent SDLC experience for data transformation pipelines and, in doing so, has become widely adopted in companies large and small. Anyone who knows SQL can now build production-grade pipelines with ease.
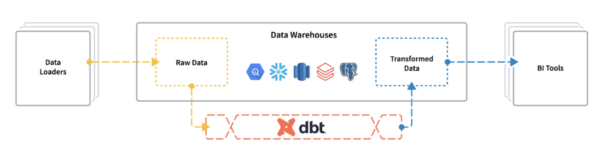
Figure 1. dbt used in transformation pipelines on data warehouses (Image source: https://github.com/dbt-labs/dbt-core)
To date, dbt was only available on proprietary cloud data warehouses, with very little interoperability between different engines. For example, transformations performed in one engine are not visible across other engines because there was no common storage or metadata store.
Cloudera has built dbt adapters for all of the engines in the open data lakehouse. Companies can now use dbt-core to consolidate all of their transformation pipelines across different engines into a single version-controlled repository with a consistent SDLC across teams. Cloudera also makes it easy to deploy dbt as a packaged application running within CDP using Cloudera Machine Learning and Cloudera Data Science Workbench. This capability allows customers to have a consistent experience irrespective of using CDP on premises or in the cloud. In addition, given that dbt is just submitting queries to the underlying engines in CDP, customers get the full governance capabilities provided by SDX, like automatic lineage capture, auditing, and impact analysis.
The combination of Cloudera’s open data lakehouse and dbt supercharges the ability of data teams to collaboratively build, test, document, and deploy data transformation pipelines using any engine and in any form factor. The packaged offering within CDP and integration with SDX provides the critical security and governance guarantees that Cloudera customers rely on.
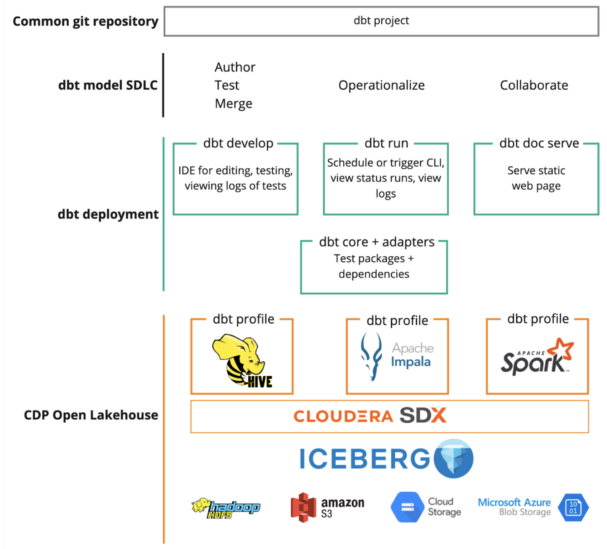
Figure 2. dbt end-to-end SDLC on CDP Open Lakehouse
How to get started with dbt within CDP
The dbt integration with CDP is brought to you by Cloudera’s Innovation Accelerator, a cross-functional team that identifies new industry trends and creates new products and partnerships that dramatically improve the lives of our Cloudera customer’s data practitioners.
To find out more, here are a selection of links for how to get started.
- Repository of the latest Python packages and docker images with dbt and all the Cloudera supported adapters
- Handbooks to run dbt as a packaged application in CDP
- Getting started guides for the open source adapters supported by Cloudera
To learn more, contact us at innovation-feedback@cloudera.com.
Editor's Choice

