

CDP Public Cloud is now available on Google Cloud. The addition of support for Google Cloud enables Cloudera to deliver on its promise to offer its enterprise data platform at a global scale. CDP Public Cloud is already available on Amazon Web Services and Microsoft Azure. With the addition of Google Cloud, we deliver on our vision of providing a hybrid and multi-cloud architecture to support our customer’s analytics needs regardless of deployment platform.

Customers who have chosen Google Cloud as their cloud platform can now use CDP Public Cloud to create secure governed data lakes in their own cloud accounts and deliver security, compliance and metadata management across multiple compute clusters. One of our customers, Commerzbank, has used the CDP Public Cloud trial to prove that they can combine both Google Cloud and CDP to accelerate their migration to Google Cloud without compromising data security or governance.
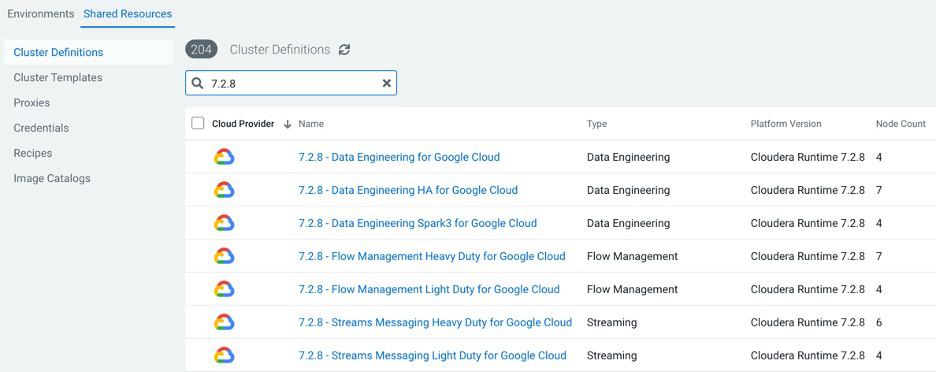
In this first Google Cloud release, CDP Public Cloud provides built-in Data Hub definitions (see screenshot for more details) for:
- Data Ingestion (Apache NiFi, Apache Kafka)
- Data Preparation (Apache Spark and Apache Hive)
Over the coming months, we will add additional services and cluster definitions – which are already available on our AWS and Azure versions – that will allow customers to:
- Analyze static (Apache Impala) and streaming (Apache Flink) data
- Deploy a platform for creating custom applications (Apache Solr, Apache HBase and Apache Phoenix)
- Access new platform capabilities – such as the SQL Stream Builder
In addition to the built-in cluster definitions, customers can create their own custom cluster definitions that combine any of the supported services. The combination of these capabilities will allow customers to easily migrate existing data pipelines to GCP or quickly set up new ones that can ingest from a number of existing or new data sources. For example, you can create a custom cluster today that includes both NiFi and Spark; this will allow you to use the extensive library of NiFi processors to easily ingest data into Google Cloud Storage, use Spark for processing and preparing the data for analytics, all in one cluster. You could then use an existing pipeline to run analytics on the prepared data in BigQuery.
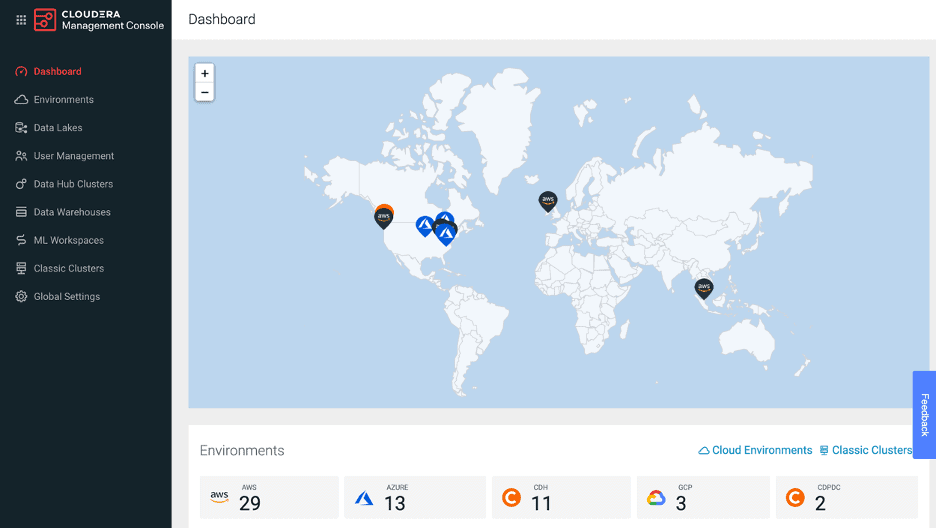
The screenshot below shows how CDP provides a single pane of glass to monitor clusters deployed both on-premises (with CDP Private Cloud) and in multiple clouds (with CDP Public Cloud).
To get started, simply request a trial account here, you will need to provide your Google Cloud account for the trial. To use CDP, you will need to set up the following resources in your Google Cloud account:
- A VPC – you can use shared or dedicated VPCs – set up with subnets and firewalls as per our documentation
- Google Cloud Storage buckets – in the same subregion as your subnets
- A provisioning Service Account with these roles assigned
When you create a CDP environment, the CDP provisioning engine running in our multi-cloud control plane will provision resources into your Google Cloud project, using the provisioning Service Account:
- Virtual Machines
- Attached Disks
- Public IPs (if required, you can also deploy with Private IPs)
- CloudSQL database
Over the next few weeks, we will also make CDP Public Cloud available on the Google Cloud Marketplace. This will make it easier for Google Cloud users to onboard onto CDP or purchase additional CDP credits by leveraging existing procurement channels.
For the full set of documentation for CDP on Google Cloud, please visit our documentation portal here.
For pricing, please see the pricing calculator and for more details, please visit our partner page for Google Cloud.
You can get started with CDP Public Cloud by requesting a trial account here.
Editor's Choice

