

Enterprises are increasingly moving portions or entire datacenters to the cloud in order to minimize their physical footprint, minimize operational overhead, and shorten their infrastructure acquisition cycles. An incidental benefit is that cloud services, like cloud-based object storage, bring a new set of tools to a Hadoop architect. At Hortonworks, our customers use a number of different cloud architectures but we frequently recommend two when it comes to using Apache Hive for analytics and reporting. In this blog, we will present those two architectures, examine their advantages and disadvantages, and provide reproducible benchmarks to support our analysis.
Cloud Architectures
Cloud storage enables the decoupling of storage and compute to varying degrees. To this effect, we propose that customers leverage this storage in one of two architectures:
- Tiered storage: Hot data is persisted to the fast volumes of HDFS that are attached to an instance while colder data is persisted to cloud storage. This can have a couple variations:
- All data is backed up to cloud storage and fully restored to HDFS when needed.
- More frequently accessed portions of a database are persisted to HDFS while colder data is pushed to cloud storage (e.g., last 3 months of partitions on HDFS and last 4.75 years on cloud storage).
- Decoupled persistent storage: All data that backs Hive tables is persisted to cloud storage and disk-based HDFS is only leveraged as temporary working space for analytics.
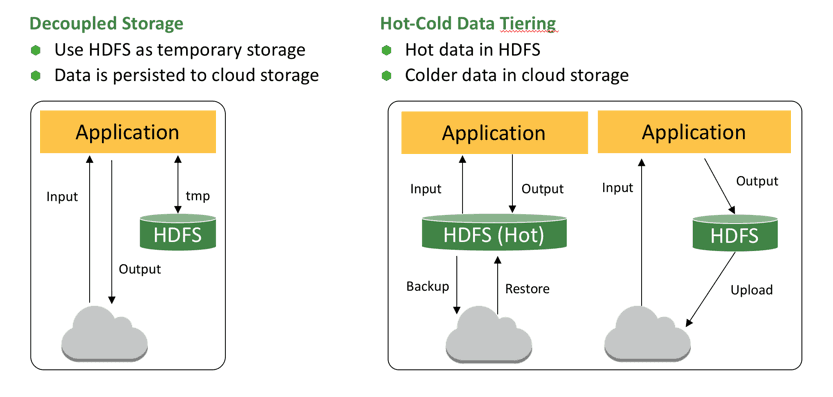
Figure 1: Cloud Architectures
There are advantages and disadvantages to each approach. The tiered approach has the most flexibility for an operator to tune the performance of the cluster while trading off size of the hot data zone for better performance or smaller resource footprint. The downside of this approach is that, having data on HDFS, resizing the cluster is a slow and tedious process due to HDFS needing to be rebalanced to achieve performance and fault-tolerance expectations. Thus this architecture is generally only used for statically sized clusters with steady, well-known workloads.
The decoupled architecture, on the other hand, enables maximum flexibility for cluster growth and reduction. For example, a cluster could run at 100 nodes during the day to support analytics and reporting and then shrink to 24 nodes overnight to support smaller ETL workloads. Historically, the disadvantage to decoupling is that cloud storage is not local and therefore could drastically affect runtime of the analytical workloads (hence the hybrid approach of tiered storage). However, the advent of LLAP in Hive 2.0 has limited this overhead making the approach far more attractive. The dynamic cache within LLAP also means that we do not need to statically define what data is hot. It can be inferred at query time (i.e., as users access the data, that data will become hot). We will look closer at how LLAP closes the runtime gap in the next section.
Evaluating the Architectures in Practice
We evaluated the architectures in Amazon EC2 with S3 for the cloud storage. However, we expect similar performance in alternative cloud environments using their respective cloud storage options. We used a 5 node (1 master + 4 workers) HDP 2.6.4 cluster consisting of m4.2xlarge machines with two 500GB volumes each for HDFS. We generated a TPCDS dataset at 50GB and duplicated the ORC database to S3 for the S3 evaluation.
The three scenarios that we evaluated are:
- Hive + Disk: the classic Hive 1.0 over data residing in HDFS
- Hive LLAP + Disk: data still resides on disk but we leverage all of the performance enhancements provided by LLAP (persistent query executors and shared cache) — this equates to the extreme version of the tiered architecture where all data is kept in HDFS and considered hot
- Hive LLAP + S3: similar to scenario 2 above but all data resides in S3 — this equates to the decoupled architecture
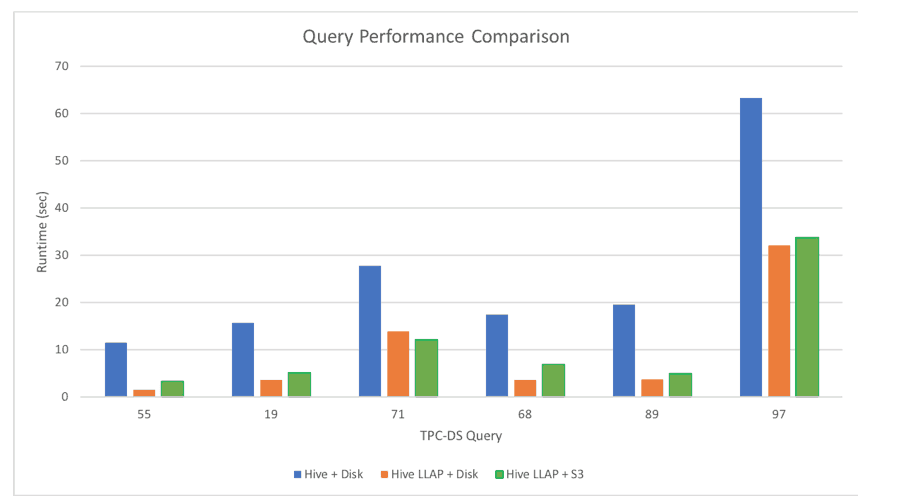
Figure 2: Cloud Architecture Performance
Figure 2 illustrates what we observed. Notice that both architectures have significant performance improvements over classic Hive 1.0 accessing data in HDFS. It also appears that, in this scenario, the overhead for leveraging cloud storage for the persistence layer is a fixed cost at around 2 seconds per query. In many situations, this overhead is worth it to gain flexibility in adjusting the cluster size over time.
Conclusion
We have presented a pair of common architectures for cloud-based Hadoop deployments and analyzed the tradeoffs of each. In summary, an organization that is willing to sacrifice a small runtime overhead that desires to minimize storage management, maximize resource flexibility (expand/reduce compute), and empower users with an interactive analytic engine can do so with a Hive data warehouse backed by cloud storage and powered by LLAP.
Editor's Choice

