

When we talk about the exponential growth of data in today’s digital world, the word “exponential” seems to be such an understatement. In 2017 alone, more data was generated than in the past 5000 years combined, and this will rise tenfold in less than a decade. A significant contributor to that data growth will be IoT. An IDC 2017 report predicts that by 2025, more than a quarter of data created across the world will be real time in nature, and real-time IoT data will make up more than 95% of this.
With this type of data growth, there are a few challenges that enterprises face –
- Data sprawl – Data is spread across the on-premises infrastructure as well across multiple clouds. And there are new data sources popping up feeding new data into the enterprise on a daily basis. The ability to ingest all different types of data across all these locations is quite challenging.
- Dark Data – When the ability of an organization to collect data exceeds the throughput at which it can process or analyze the data, then the organization starts to accumulate on dark data. Dark data is the data residing in your data stores that is not being used in any way to extract valuable business, customers, and operational insights. In 2016, the world produced 16 ZB (yup, 16 million Petabytes) of data, but only 1% was analyzed.
- Data Decay – With the fast pace at which businesses are moving and technologies are evolving, data retains its value for a certain period of time within a certain context. The insights that you derive from real-time data streams are termed as perishable insights because that insight is valuable only within a certain time window after which the opportunity to use that actionable intelligence is lost.
In essence, the need for gaining access to the correct set of data at the correct time and context is very essential to take corrective actions within the opportunity window. But, in spite of the inability to process all the data that an enterprise possesses or receives, it is still pertinent for the enterprise to look at relevant data sets that are outside the organization as well. With the mainstream use cases for AI, ML and Data Science on the rise, enterprises need to feed such algorithms larger sample sets to get more accurate predictive models for decision making. Look at the fatal incident with the autonomous Uber car in the news recently. It shows that our ML models are far from being perfect in trusting them with mission-critical or life-saving activities. More such real-life data is made available to such algorithms, the better they learn and execute.
In order to gain access to such external data sets, enterprises are willing to pay money. Every digital enterprise today is sitting on a gold mine – their own data. I am not talking about customer data or PII (Personally Identifiable Information) data. Usage metrics, consumer behavior, demographics information, machine test data and so many such data sets – with a little bit of anonymization, enterprises can monetize such data sets to their own benefit.
On a related note, the Things economy is paving way for an Ecosystem economy. IoT is only as good as the data it generates and processes. Every connected device is made up of several connected OEM components internally. A connected car is made up of several connected OEM components from various manufacturers. The sensor data from one set of devices within that connected ecosystem can be valuable for another set of devices within the same ecosystem. And it is with this premise, data marketplaces are gaining more relevance and prominence today.
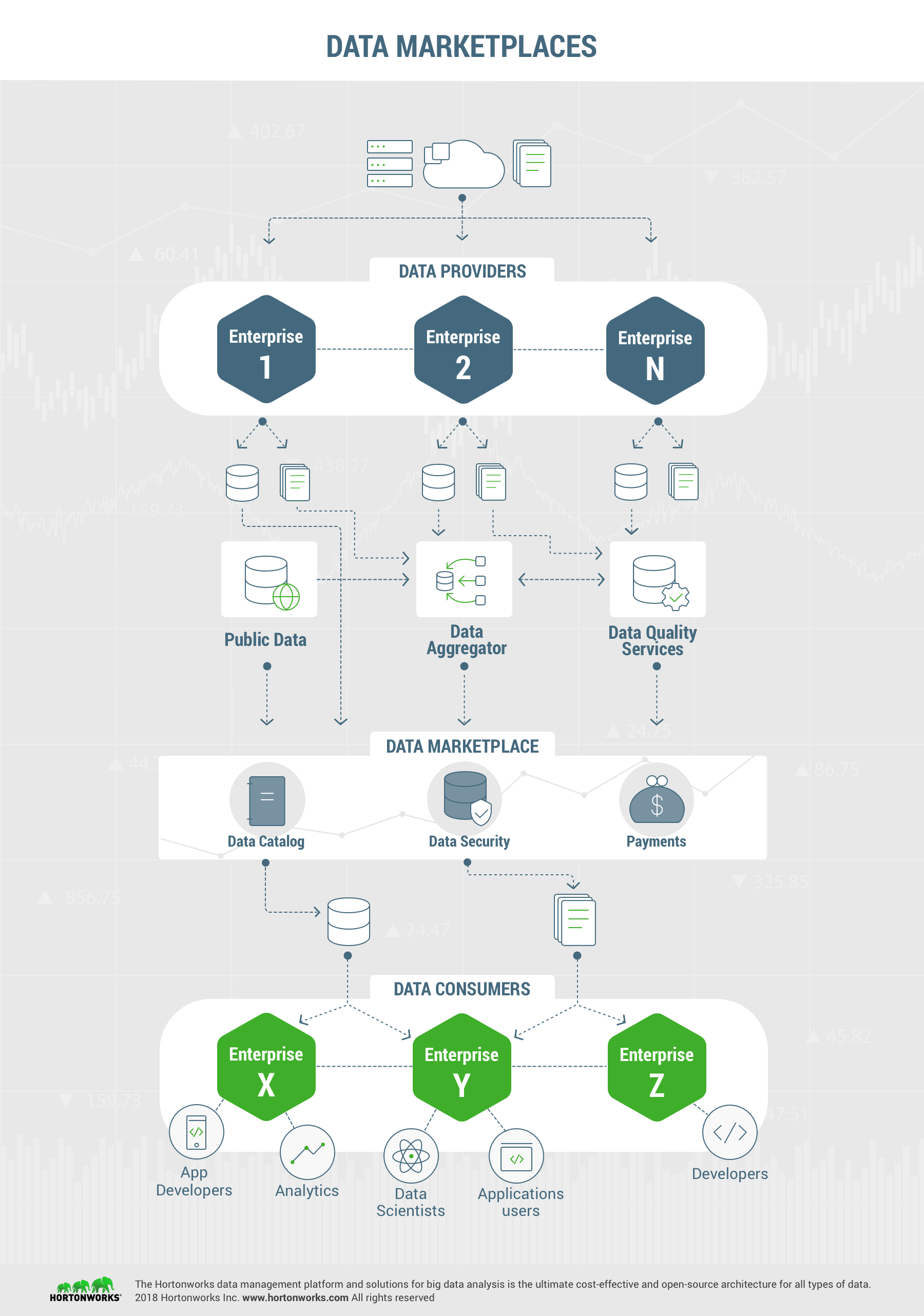
A data marketplace is a platform where data providers (those that own/license that data) can offer their data sets for a price. Data consumers can purchase or subscribe to such data sets and use it for their research, modeling or analysis. The marketplace itself may be hosted by a third party proving this secure platform for such data exchanges to smoothly happen. Data is made available through a data catalog. Data can be sold in chunks or segments. Data can also be made available as Data-as-a-Service.
There may be other services providers in such platforms such as data aggregators that can collect and combine specific data sets from multiple providers and create a logical dataset aggregation. This is made possible with metadata-driven models that allow for data tagging within the catalog. So, when looking for “tire wear-and-tear data”, data related to the tag “Tires” can come from multiple data sets across multiple data providers. In the marketplace, there may also be data quality service providers that may offer to cleanse up data sets for a price. There are some marketplaces that even crowdsource data quality services.
Now, you may ask, who would want to purchase such data? Companies looking for new business opportunities, new markets, competitive threats etc. are ideal data consumers. Companies planning to use such data sets for their product enhancements are ideal marketplace customers. And, companies using such information for enhanced or premium services to their customers are ideal for this model too. An example of that will be insurance companies using connected car usage metrics from automotive vendors to create more accurate and personalized insurance quotes for their customers in various regional locations.
If all this sounds so ideal, why aren’t we seeing more data marketplaces still? There are a few challenges to the adoption of this model. I will go into more details in my next post on the challenges and how emerging technologies like Blockchain can enable marketplaces.
Editor's Choice

