

We’re excited to share that after adding ANSI SQL, secondary indices, star schema, and view capabilities to Cloudera’s Operational Database, we will be introducing distributed transaction support in the coming months.
What is ACID?
The ACID model of database design is one of the most important concepts in databases. ACID stands for atomicity, consistency, isolation, and durability. For a very long time, strict adherence to these four properties was required for a commercially successful database. However, this model created problems when it came to scaling beyond a one server database. To accommodate this limitation, customers scaled up the hardware on which the databases were deployed.
NoSQL databases loosened one or more of these 4 properties to achieve dramatic improvements in scalability — Cloudera Operational Database (Powered by Apache HBase) was one such database. We made trade-offs on atomicity — specifically, Cloudera provided single-row atomicity. To compensate, we supported very wide tables (with potentially millions of columns). This allowed customers to denormalize their star schemas and represent them as single rows in order to make atomic commits in a single row of what used to be represented as multiple tables.
Since the birth of HBase, we have been working towards building capabilities that narrows the feature gap with traditional RDBMs while maintaining the benefits of NoSQL scalability, consistency, durability, and isolation.
Earlier this year, we provided support for ANSI SQL, secondary indices, star schema, and views on top of Apache HBase bringing an interface and capabilities that are familiar to all application developers that have ever built an application that uses MySQL or PostGres.
We are now on the cusp of delivering the ability to make atomic commits to data that crosses rows and tables across the cluster.
What is an atomic transaction?
A transaction comprises a set of operations in a database that are managed atomically, so all the operations must either entirely be completed (committed) or have no effect (aborted).
Currently, we only support single-row atomic transactions. This means that when developers look to adopt Cloudera’s Operational Database, they need to think differently about their schema.
We are now introducing the ability to have complex transactions that span multiple rows and tables, meaning that developers can implement traditional star schema or take advantage of wide columns or both depending on their needs. This flexibility combined with Cloudera Operational Database’s evolutionary schema approach allows developers to take advantage of a modern scale-out database while carrying their existing skill set forward.
An important thing to note is that transaction support in Cloudera Operational Database is “lock-free” and provides snapshot isolation guarantees. Traditional databases implement a “lock” to all the data associated with a transaction so that other clients accessing the data don’t change it before it is committed to the database. However, this could result in race-conditions that would end up with circular dependencies and hang. Locks were also the cause of dramatically poor performance on the part of an application as applications waited on each other so that they could get a lock and proceed.
Our approach allows the first transaction that completes to move forward and the others that were trying to make changes to the same set of data will have to retry. This prevents any slow-down to the entire ecosystem of applications running simultaneously on the database. In other words, our approach allows linear scalability while providing the atomicity that traditional transactional databases are able to provide.
Preliminary performance results
Our transaction support capability is currently in beta and being put through extensive performance testing.
Current testing includes the industry-standard TPC-C benchmark using the OLTP Bench application. The TPC-C benchmark simulates a number of purchases conducted simultaneously across a number of warehouses. The schema used in TPC-C are represented in the following entity-relationship diagram:
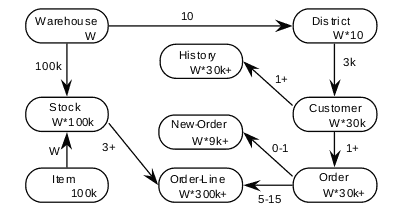
The numbers in the entity blocks represent the cardinality of the tables (number of rows). These numbers are factored by W, the number of Warehouses, to illustrate the database scaling. The numbers next to the relationship arrows represent the cardinality of relationships (the average number of children per parent). + symbol represents the number small variation of database population.
An order placement requires the following 10 queries to be run as a single atomic transaction:
1.SELECT c_discount, c_last, C_credit FROM customer WHERE c_w_id = ? AND c_d_id = ? AND c_id = ? 2. SELECT w_tax FROM warehouse WHERE w_id = ? 3. SELECT d_next_o_id, D_tax FROM district WHERE d_w_id = ? AND d_id = ? 4. UPSERT INTO district (d_next_o_id, d_w_id, d_id) SELECT d_next_o_id + 1, d_w_id, D_id FROM district WHERE d_w_id = ? AND d_id = ? 5. UPSERT INTO new_order (no_o_id, no_d_id, no_w_id) VALUES (?,?,?) 6. UPSERT INTO order (o_id, o_d_id, o_w_id, o_c_id, o_entry_d, o_ol_cnt, o_all_local) VALUES (?,?,?,?, ?,?,?) Repeat following queries for each item selected for order. 7. SELECT i_price, i_name, i_data FROM item WHERE i_id = ? 8. SELECT s_quantity, s_data, s_dist_01, s_dist_02, s_dist_03, s_dist_04, s_dist_05, s_dist_06, s_dist_07, s_dist_08, s_dist_09, s_dist_10 FROM stock WHERE s_i_id = ? AND s_w_id = ? 9. UPSERT INTO stock (s_quantity, s_ytd, s_order_cnt, s_remote_cnt, s_i_id, s_w_id) SELECT ?, s_ytd + ?, s_order_cnt + 1, s_remote_cnt + ?, s_i_id, s_w_id FROM stock WHERE s_i_id = ? AND s_w_id = ? 10. INSERT INTO order_line (ol_o_id, ol_d_id, ol_w_id, ol_number, ol_i_id, ol_supply_w_id, ol_quantity, ol_amount, ol_dist_info) VALUES (?,?,?,?,?,?,?,?,?)
An payment transaction requires the 6 following queries to be run as a single atomic transaction:
1. UPSERT INTO warehouse (w_ytd, w_id) SELECT w_ytd + ?, w_id FROM warehouse WHERE w_id =? 2. SELECT w_street_1, w_street_2, w_city, w_state, w_zip, w_name FROM warehouse WHERE w_id = ? 3. UPSERT INTO district (d_ytd, d_w_id, d_id) SELECT d_ytd + ?, d_w_id, d_id FROM district WHERE d_w_id = ? AND d_id = ? 4. SELECT d_street_1, d_street_2, d_city, d_state, d_zip, d_name FROM district WHERE d_w_id = ? AND d_id = ? 6. UPSERT INTO customer (c_balance, c_ytd_payment, c_payment_cnt, c_w_id, c_d_id, c_id) SELECT ?, ?, ?, c_w_id, c_d_id, c_id FROM customer WHERE c_w_id = ? AND c_d_id = ? AND c_id = ? 7. INSERT INTO history (h_c_d_id, h_c_w_id, h_c_id, h_d_id, h_w_id, h_date, h_amount, h_data) VALUES (?,?,?,?,?,?,?,?)
With 3 region servers running on Dell PowerEdge R440 nodes, we were able to achieve the following results:
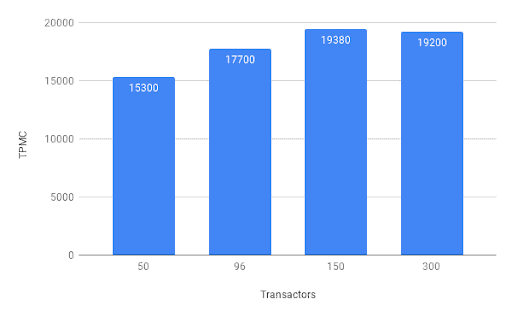
In this graph, the Y-axis represents the number of number of orders that can be fully processed (including new order creation, payment, delivery etc.) per minute and is expressed in the tpm-C benchmark. The X-axis represents the number of entities executing transactions in parallel.
These preliminary results indicate that the system reaches a peak transaction throughput somewhere between 150 and 300 transactors and further testing is required to identify that peak.
As this capability matures, both the OpDB throughput and our ability to measure throughput will improve.
Conclusion
Most applications leverage transactions to support the myriad of needs that enterprises face. However, when traditional RDBMSs can’t scale, customers are forced to manually shard the database and to manage each sharded database as an independent database on its own.
When this becomes too cumbersome to manage, customers should consider migrating that application to Cloudera’s Operational Database. Complex transaction support combined with ANSI SQL support and the scale-out nature of Apache HBase provides a combination that can significantly reduce operational complexity of managing growth.
If you are tired of managing sharded databases and looking to lower database TCO, reach out to your Cloudera account team to see how we can help.
Editor's Choice

