

Across nearly every sector working with complex data, Spark has quickly become the de-facto distributed computing framework for teams across the data and analytics lifecycle. One of most awaited features of Spark 3.0 is the new Adaptive Query Execution framework (AQE), which fixes the issues that have plagued a lot of Spark SQL workloads. Those were documented in early 2018 in this blog from a mixed Intel and Baidu team. For a deeper look at the framework, take our updated Apache Spark Performance Tuning course.
Our experience with Workload XM certainly confirms the reality and severity of those problems.
AQE was first introduced in Spark 2.4 but with Spark 3.0 it is much more developed. Although Cloudera recommends waiting to use it in production until we ship Spark 3.1, AQE is available for you to begin evaluating in Spark 3.0 now.
First, let’s look at the kind of problems that AQE solves.
The Flaw in the Initial Catalyst Design
The diagram below represents the kind of distributed processing that happens when you do a simple group-by-count query using DataFrames.
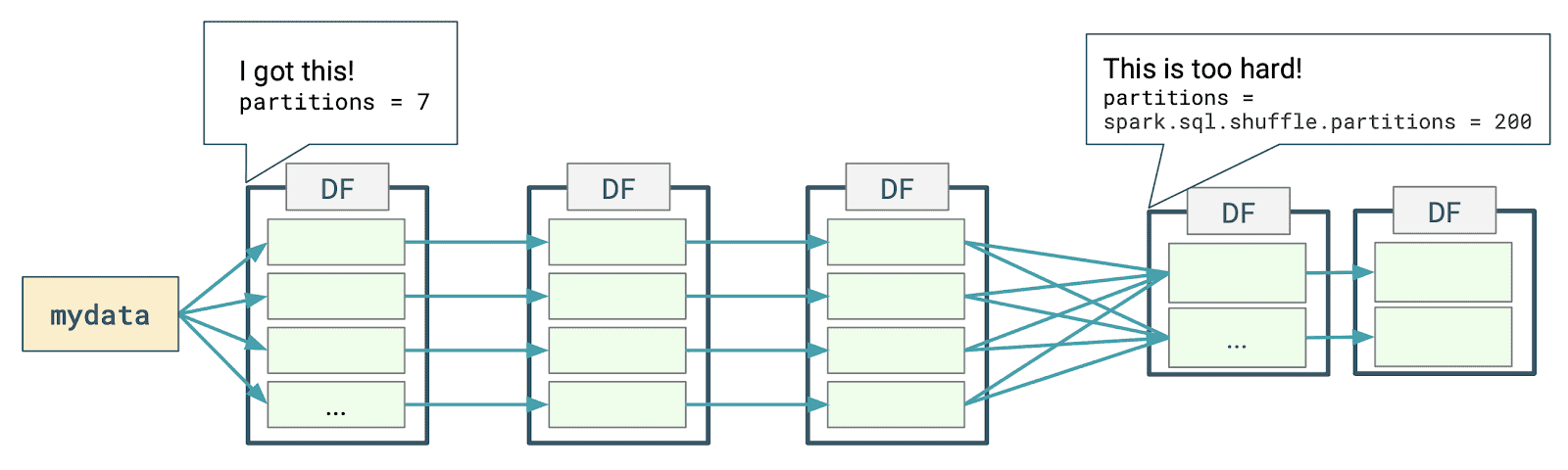
Spark determines an appropriate number of partitions for the first stage, but for the second stage, uses a default magic number of 200.
That’s bad for three reasons:
- 200 is very unlikely to be the ideal number of partitions and the number of partitions is one of the critical factors that influences performance;
- if you write the output of that second stage to disk, you may end up with 200 small files;
- Optimizations and their absence have knock-on effects: if the processing should continue after the second stage you could miss potential opportunities for more optimizations.
What you could do is manually set the value of this property for this shuffle before executing your query with a statement like this one:
spark.conf.set(“spark.sql.shuffle.partitions”,”2″)
That also creates some challenges:
- Setting this property before each query is tedious
- Those values will become obsolete with the evolution of your data
- This setting will be applied to all the shuffles in your query
Before the first stage in the previous example, the distribution and volume of data are known, and Spark can come up with a sensible value for the number of partitions. For the second stage, however, this information is not yet known as the price to pay to get it is to perform the actual processing of the first stage: hence the resort to a magic number.
Adaptive Query Execution Design Principle
The main idea of AQE is to make the execution plan not final and allow for reviews at each stage boundary. Thus the execution plan is broken down into new “query stages” abstractions delimited by stages.
Catalyst now stops at each stage boundary to try and apply additional optimizations given the information available on the intermediate data.
Therefore AQE can be defined as a layer on top of the Spark Catalyst which will modify the Spark plan on the fly.
Any drawbacks? Some, but they are minor:
- The execution stops at each stage boundary for Spark to review its plan but that is offset by the gains in performance.
- The Spark UI is more difficult to read because Spark creates more jobs for a given application and those jobs do not pick up the Job group and description that you set.

Adaptive Number of Shuffle Partitions
This feature of AQE has been available since Spark 2.4.
To enable it you need to set spark.sql.adaptive.enabled to true, the default value is false. When AQE is enabled, the number of shuffle partitions are automatically adjusted and are no longer the default 200 or manually set value.
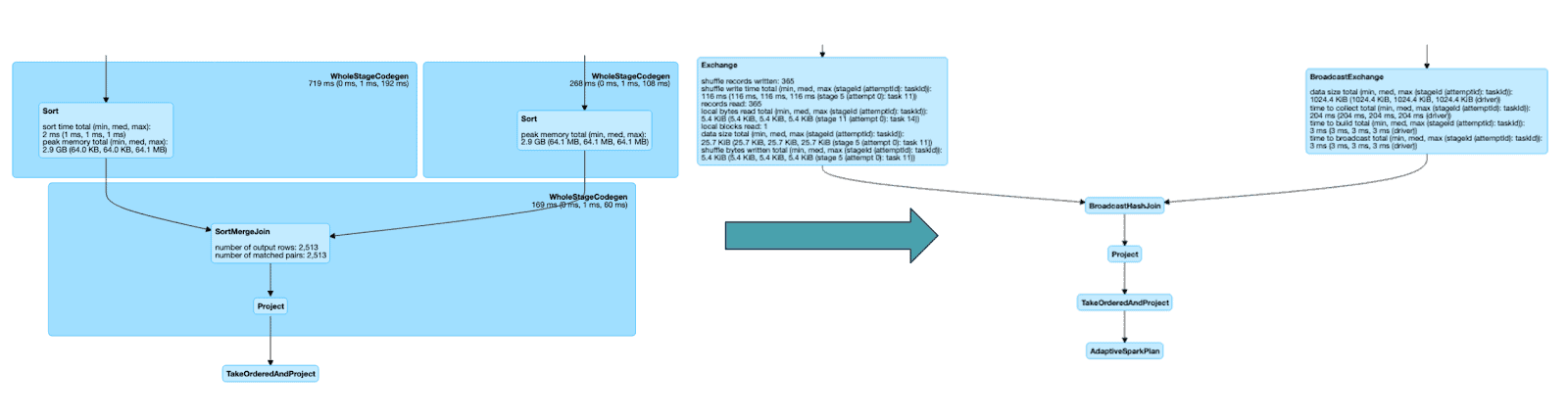
This is what the execution of the first TPC-DS query looks like before and after enabling AQE:

Dynamically Converting Sort Merge Joins to Broadcast Joins
AQE converts sort-merge joins to broadcast hash joins when the runtime statistics of any join side is smaller than the broadcast hash join threshold.
This is what the last stages of the execution of the second TPC-DS query looks like before and after enabling AQE:
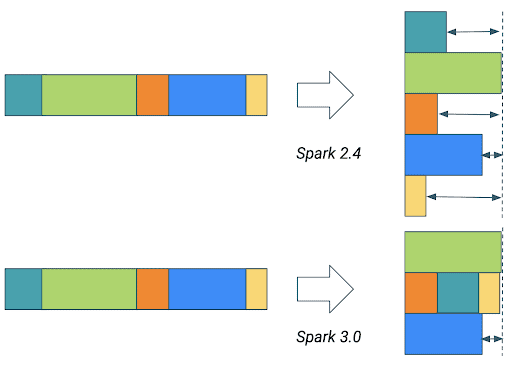
Dynamically Coalesce Shuffle Partitions
If the number of shuffle partitions is greater than the number of the group by keys then a lot of CPU cycles are lost due to the unbalanced distribution of the keys
When both
-
spark.sql.adaptive.enabled and
-
spark.sql.adaptive.coalescePartitions.enabled
are set to true, Spark will coalesce contiguous shuffle partitions according
to the target size specified by spark.sql.adaptive.advisoryPartitionSizeInBytes to avoid too many small tasks.
Dynamically Optimize Skewed Joins
Skew is the Kryptonite of distributed processing. It can literally stall your processing for hours:

Without optimizations, the time required to perform the join will be defined by the largest partition.
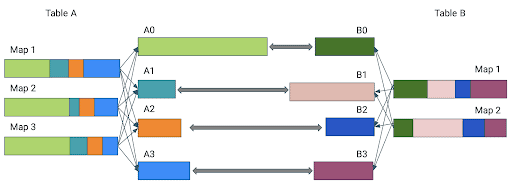
The skew join optimization will thus split partition A0 into subpartitions using the value specified by spark.sql.adaptive.advisoryPartitionSizeInBytes and join each of them to the corresponding partition B0 of table B.
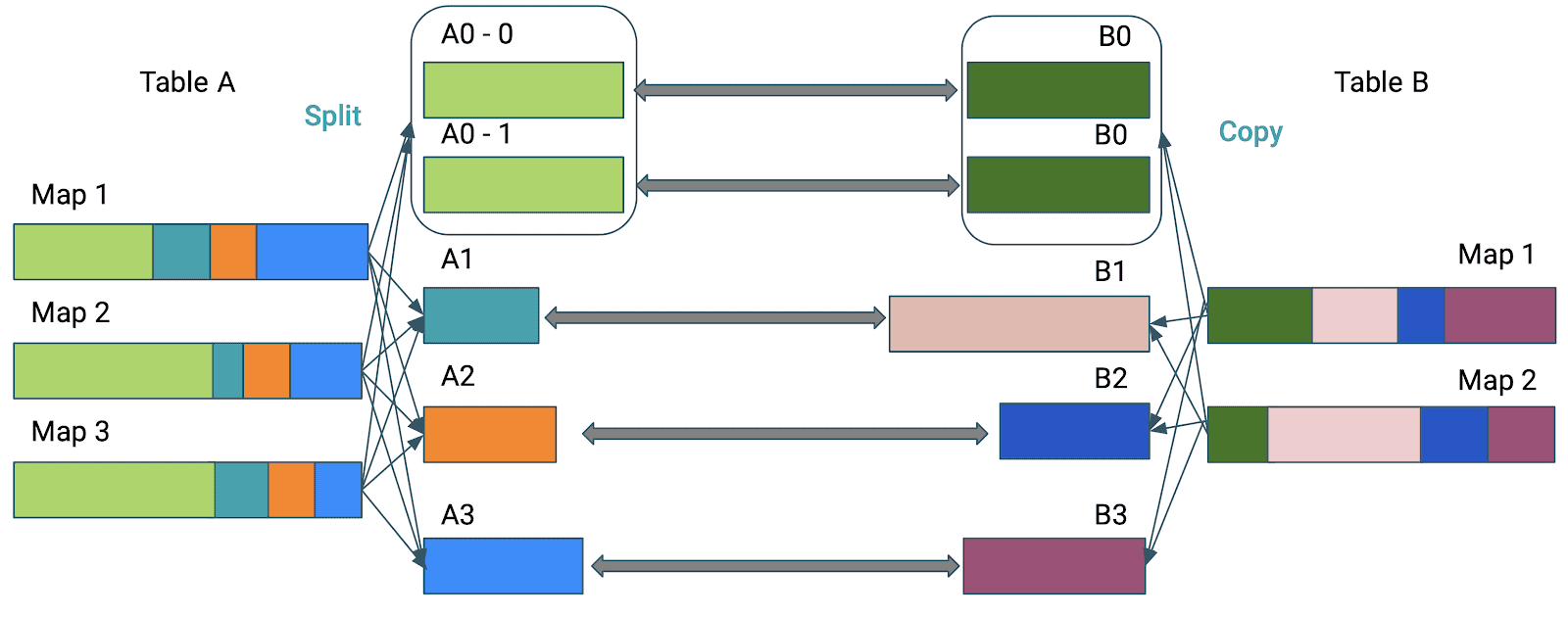
You, therefore, need to provide AQE with your definition of skew.
This involves two properties:
- spark.sql.adaptive.skewJoin.skewedPartitionFactor is relative: a partition is considered as skewed if its size is larger than this factor multiplying the median partition size and also larger than
- spark.sql.adaptive.skewedPartitionThresholdInBytes, which is absolute: it’s the threshold below which skew will be ignored.
Dynamic Partition Pruning
The idea of dynamic partition pruning (DPP) is one of the most efficient optimization techniques: read only the data you need. If you have DPP in your query then AQE is not triggered. DPP has been backported to Spark 2.4 for CDP.
This optimization is implemented both on the logical plan and the physical plan.
- At the logical level, the dimensional filter is identified and propagated across the join to the other side of the scan.
- Then at the physical level, the filter is executed once on the dimension side and the result is broadcasted to the main table where the filter is also applied.
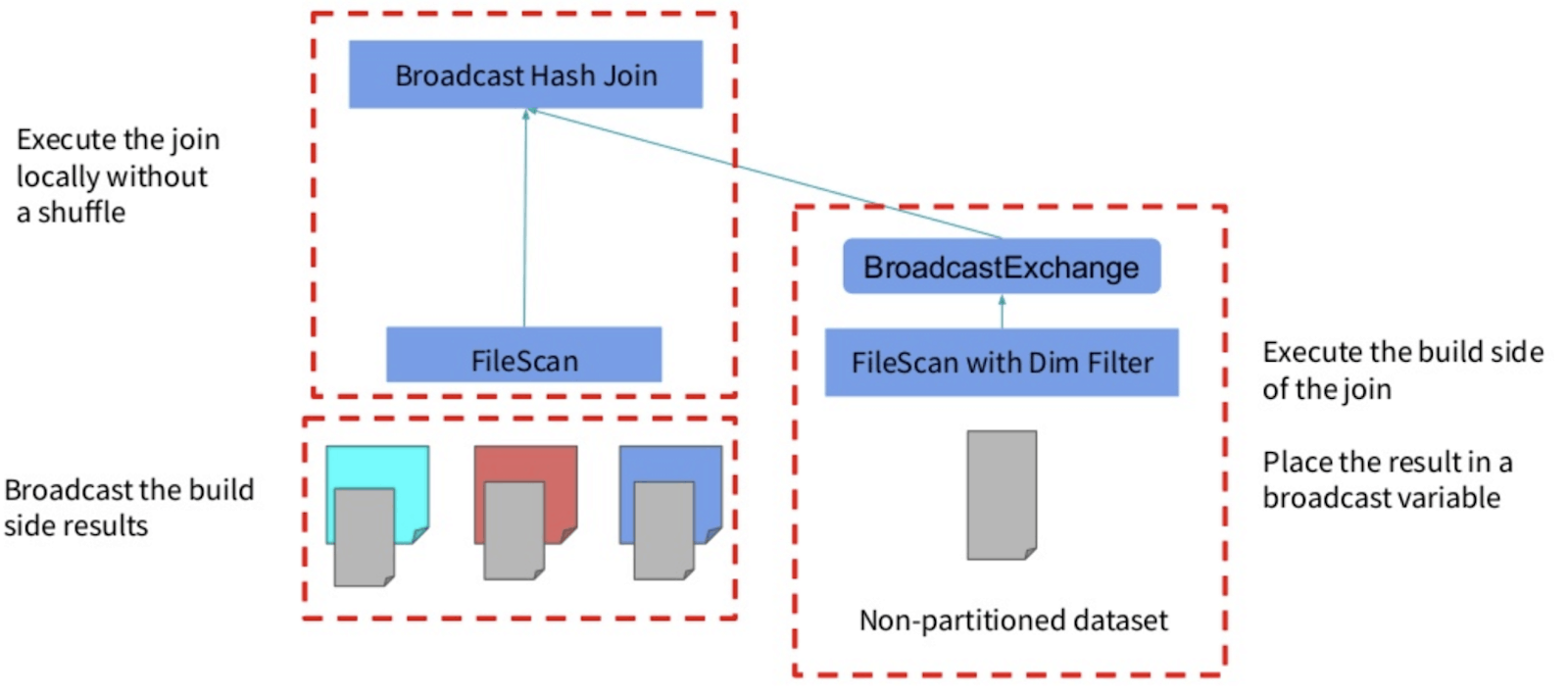
DPP can actually work with other types of joins (e.g. SortMergeJoin) if you disable spark.sql.optimizer.dynamicPartitionPruning.reuseBroadcastOnly.
In that case Spark will estimate whether the DPP filter actually improves the query performance.
DPP can result in massive performance gains for highly selective queries for instance if your query filters on a single month out of 5 years worth of data.
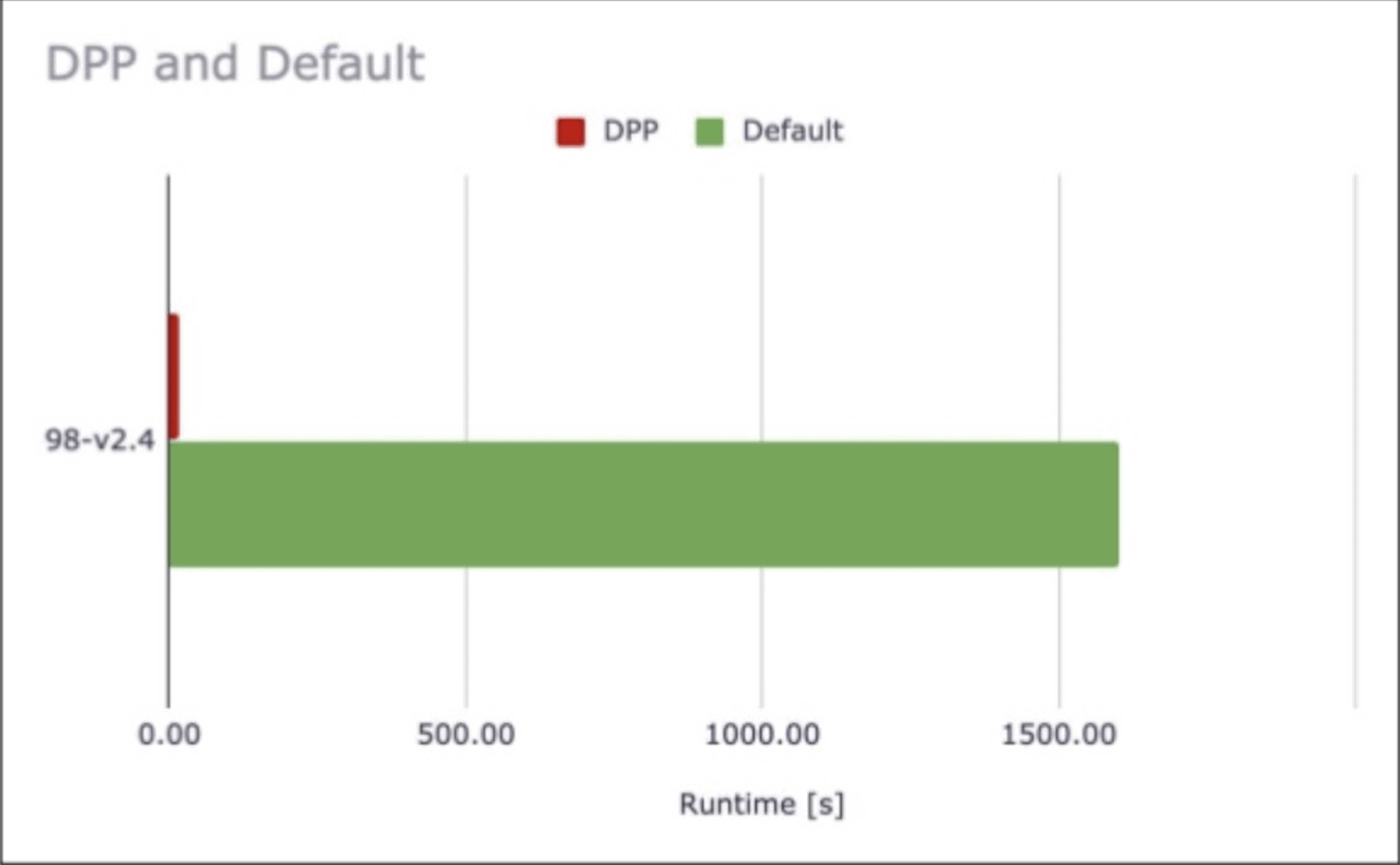
Not all queries get such an impressive boost in performance but 72 out of the 99 TPC-DS queries are positively affected by DPP.
Conclusion
Spark has come a long way from its initial core paradigm: lazily execute an optimized static plan on a static dataset.
The static dataset part was challenged by streaming: the Spark team first created a clumsy RDD-based design before coming up with a better solution involving DataFrames.
The static plan part was challenged by SQL and the Adaptive Query Execution framework, in a way, is what Structured Streaming is to the initial streaming library: the elegant solution it should have been all along.
With the AQE framework, DPP and the increased support for GPUs and Kubernetes, the perspectives of performance increase are very promising and we should see rapid adoption of Spark 3.0. If you’d like to get hands-on experience with AQE, as well as other tools and techniques for making your Spark jobs run at peak performance, sign up for Cloudera’s Apache Spark Performance Tuning Training Course and get a sneak preview in our Apache Spark Application Performance Tuning Webinar.
Editor's Choice

