

Mayank Bansal, of EBay, is a guest contributing author of this collaborative blog.
This is the 4th post in a series that explores the theme of enabling diverse workloads in YARN. See the introductory post to understand the context around all the new features for diverse workloads as part of Apache Hadoop YARN in HDP.
Background
In Hadoop YARN’s Capacity Scheduler, resources are shared by setting capacities on a hierarchy of queues.
A queue’s configured capacity ensures the minimum resources it can get from ResourceManager. Sum of capacities of all the leaf-queues under a parent queue at any level is equal to 100%. As shown below, queueA has 20% share of the cluster, queue-B has 30% and queue-C has 50%, sum of them equals to 100%.
To enable elasticity in a shared cluster, CapacityScheduler can allow queues to use more resources than their configured capacities when a cluster has idle resources.
Without preemption, let’s say queue-A uses more resources than its configured capacity taking advantage of the elasticity feature of CapacityScheduler. At the same time, say another queue, queue-B, currently under-satisfied starts asking for more resources. queue-B will now have to wait for a while before queue-A relinquishes resources it is currently using. Due to this, high delay of applications in queue-B will be expected, there isn’t any way we can meet SLAs of applications being submitted in queue-B in this situation.
Support for preemption is a way to respect elasticity and SLAs together: when no resources are unused in a cluster, and some under-satisfied queues ask for new resources, the cluster will take back resources from queues that are consuming more than their configured capacities.
How preemption works
All the information related to queues is tracked by the ResourceManager. A component called PreemptionMonitor in ResourceManager is responsible for performing preemption when needed. It runs in a separate thread making relatively slow passes to make decisions on when to rebalance queues. The regular scheduling itself happens in a thread different from the PreemptionMonitor.
We will now explain how preemption works in practice taking an example situation occurring in a Hadoop YARN cluster. Below is an example queue state in a cluster:
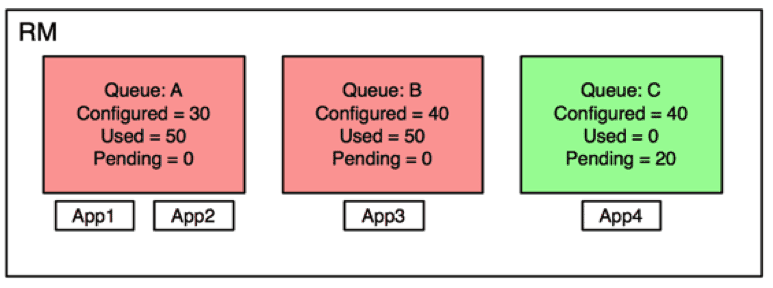
Let’s say that we have 3 queues in the cluster with 4 applications running. Queues A and B have already used resources more than their configured minimum capacities. Queue-C is under satisfied and asking for more resources. Two applications are running in queue-A and one in each of queues B and C.
We now describe the steps involved in the preemption process that tries to balance back the resource utilization across queues over time.
Preemption Step #1: Get containers to-be-preempted from over-used queues
The PreemptionMonitor checks queues’ status every X seconds, and figures out how many resources need to be taken back from each queue / application so as to fulfil needs of under-satisfied queues. As a result, it arrives at a list of containers to be preempted, as demonstrated below:
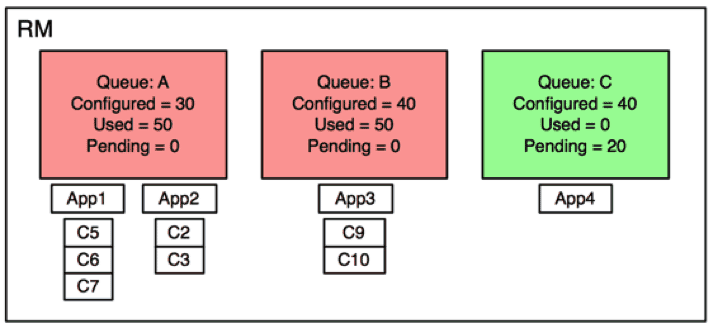
For example, containers C5, C6, C7 from App1 and containers C2 and C3 from App2 are marked to-be-preempted. We will explore internal algorithms of how we select containers to be preempted in a separate detailed post shortly.
Preemption Step #2: Notifying ApplicationMasters so that they can take actions
Instead of killing thus-marked containers immediately to free resources, PreemptionMonitor inside the ResourceManager notifies ApplicationMasters (AM) so that AMs can take advanced actions before ResourceManager itself commits a hard decision. More details on what information AMs obtain and how they can act on it is described in the section “Impact of preemption on applications” below. This is a way for ApplicationMasters to do a second level pass (similar to scheduling) on what containers for the right set of resources to free up.
Preemption Step #3: Wait before forceful termination
After some containers gets added to to-be-preempted list, and the queues over capacity don’t shrink down (through actions from applications) to the targeted capacity even after an admin-configured interval (see yarn.resourcemanager.monitor.capacity.preemption.monitoring_interval in Configurations section below), such containers will be forcefully killed by the ResourceManager to ensure that SLAs of applications in under-satisfied queues are met.
Advantages of preemption
We now demonstrate the advantages of preemption.The following example scenario should give you an intuitive understanding about how preemption can achieve a balance between elasticity (and making use of fallow resources) and application SLAs.
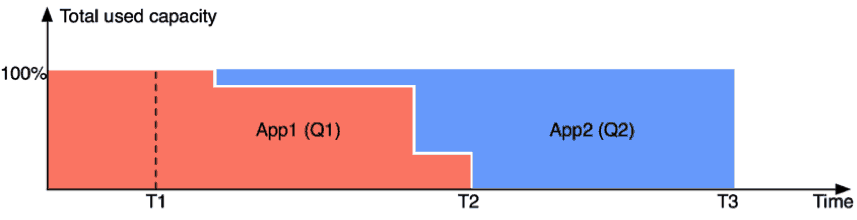
Consider a simple case. Queues Q1 and Q2 have configured minimum capacity of 50%, and each of them have exactly one application running – App1 in Q1 and App2 in Q2. App1 starts running first, it occupies all the resources in the cluster (elasticity). Let’s say that while App1 is running at the full cluster capacity, a user submits App2 to queue Q2.
The following is the timeline of the above events:
- App1 starts running at time 0
- T1: Time of App2’s submission
- T2: Time when App1 can complete
- T3: Time when App2 can complete
When preemption is not enabled
When preemption is enabled
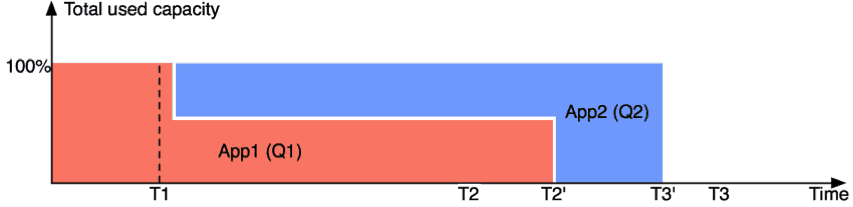
With preemption enabled, ResourceManager will start preempting resources in a short time after App2 gets submitted, irrespective of whether App1 voluntarily releases containers or not. Apps in Q1 and Q2 will now share cluster-resources, each of them will get 50% of cluster resource, just as they were originally promised via minimum configured capacities. T2’ is the new time at which App1 completes in this setup, T3’ is the new time App2 gets completed.
After preemption is enabled, App2 usually finishes faster (than when preemption was not enabled) – T3’ < T3. It is possible though that App1 now finishes slower – T2’ > T2. This is acceptable though given App1 originally got much more resources than was originally guaranteed. This way the system achieves a balance between using barren capacity and promising reasonable SLAs to new applications.
Preemption across a hierarchy of queues
So far, we have only talked about how preemption works across two queues at the same level. CapacityScheduler also supports the notion of a hierarchy of queues. Let’s see how preemption works in this context with an example.
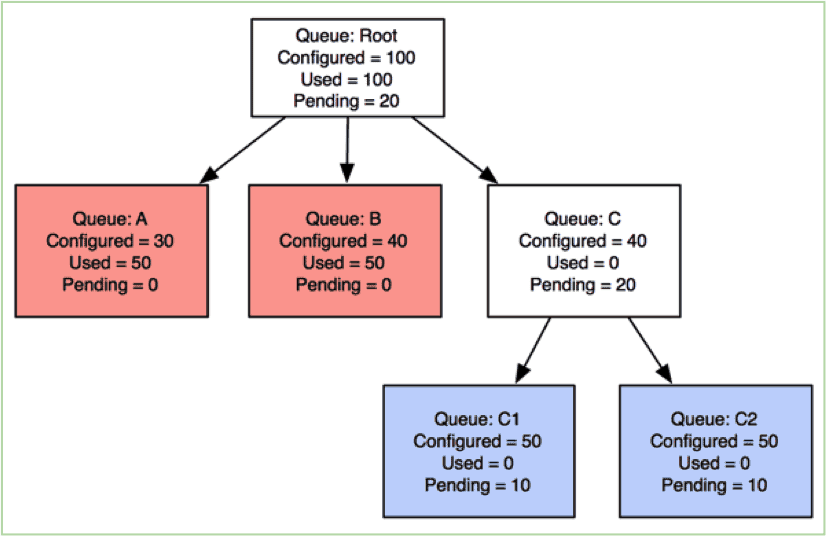
Queues C1 and C2 are under-satisfied and start to ask for reclaiming their originally promised resources back. Queues A/B are over-allocated. In this case, PreemptionMonitor will preempt containers in queues A and B so that the next scheduling cycle can allocate the freed-up resources to applications in queues C1 and C2.
This way, preemption works in conjunction with the scheduling flow to make sure that resources freed up at any level in the hierarchy are given back to the right queues in the right level.
Impact of preemption on applications
As hinted before, ResourceManager sends preemption messages to ApplicationMasters in the AM-RM heartbeats. The preemption messages contain the list of containers about to be preempted – see the API record org.apache.hadoop.yarn.api.records.PreemptionMessage.
A PreemptionMessage may return two different types of ‘contracts’:
- The first type is a StrictPreemptionContract, which contains a list of containers that should definitely be freed up by the ApplicationMaster. The AM cannot do anything beyond creating checkpoints of work done by such containers.
- The second type of contract is simply a PreemptionContract. This contract leaves the AM the flexibility to either make checkpoints for such containers or release other containers matching the size of ResourceRequests in PreemptionContract#getResourceRequests().
As of the writing of this post, the PreemptionMonitor in the CapacityScheduler supports only the latter one.
Acting on about-to-be-preempted-containers
With the information present in PreemptionMessage, AMs can better handle preemption events
- Instead of letting the RM forcefully kill marked containers, AMs themselves can kill other containers belonging to the same application. RM is always agnostic to a specific application’s life cycle, the AMs know much more about the characteristics of its containers. It is possible that some containers are more important than others from the AM’s perspective – they may have just have been further along in terms of their work-in-progress. AMs can release other ‘cheaper’ containers before their more “important” containers get forcefully killed.
- Before RM pulls the trigger, applications can checkpoint the state of containers marked to be preempted. Using such checkpointed state, AMs can resume progress of the work done by the killed containers once there is a scope for obtaining a new wave of resources again.
Handling already preempted containers
If applications in a queue do not act on the preemption messages, after a while containers get forcefully killed by the RM. In this case, RM will set a special exit-code (ContainerExitStatus#Preempted) for such preempted containers, and AMs get notifications of the same in the next AM-RM heartbeat. The ApplicationMasters should handle these preempted containers specially – they don’t really count towards failure of the container process itself.
An example of this is the MapReduce AM (MAPREDUCE-5900, MAPREDUCE-5956), it doesn’t count any preempted containers towards task failures. So even if a task gets killed due to preemption a number of times, the AM will continue to launch a fresh task-attempt for that task.
Configurations
To enable preemption in CapacityScheduler, administrators have to set the following in the configuration file yarn-site.xml
(1) yarn.resourcemanager.scheduler.monitor.enable
This informs ResourceManager to enable the monitoring-policies specified by the next configuration property. Set this to true for enabling preemption.
(2) yarn.resourcemanager.scheduler.monitor.policies
Specifies a list of monitoring-policies that ResourceManager should load at startup if monitoring-policies are enabled through the previous property. To enable preemption, this has to be set to org.apache.hadoop.yarn.server.resourcemanager.monitor.capacity.ProportionalCapacityPreemptionPolicy
The following is a list of advanced configuration properties that administrators can use to further tune the preemption mechanism:
(3) yarn.resourcemanager.monitor.capacity.preemption.monitoring_interval
Time in milliseconds between successive invocations of the preemption-policy, defaulting to 3000 (3 seconds). One invocation of the preemption-policy will scan for queues, running applications, containers and makes a decision as to which container will be preempted (Steps described above in the section “How preemption works”).
If an admin wants to set a fast-paced preemption, together with other properties below, he/she should set it to a low value. Similarly a higher value can be set for slower preemption.
(4) yarn.resourcemanager.monitor.capacity.preemption.max_wait_before_kill
Time in milliseconds between the starting time when a container is marked to-be preempted and the final time when the preemption-policy forcefully kills the container. By default, preemption-policy will wait for 15 seconds for AMs to release resources before a forceful-kill of containers.
Administrators can adjust this parameter to a smaller value if he/she wants to reclaim resource back faster or set it to a higher value if he/she wants more gradual reclamation of resources.
(5) yarn.resourcemanager.monitor.capacity.preemption.total_preemption_per_round
This option controls the pace at which containers-marked-for-preemption are actually preempted in each period (see monitoring_interval above). It is defined as a percentage of cluster-resource, defaulting to 0.1 (read as 10%). For example, if it is set to 0.1 and the total memory allocated for YARN in the cluster is 100G, at most 10G worth of containers can be preempted in each period.
This way, even if there are times during which there is a need to preempt a large share of the cluster suddenly, the process is spread out over time to smoothen the impact of preemption.
(6) yarn.resourcemanager.monitor.capacity.preemption.max_ignored_over_capacity
Similar to total_preemption_per_round above, this configuration specifies a threshold to avoid resource-joggling and aggressive preemption. When configured to a value x >= 0, RM will wait till a queue uses resources amounting to configured_capacity * (1 + x) before starting to preempt containers from it. A similar example in real life is a freeway’s speed limit – it can be marked as X (65) MPH, but you will usually be considered overspeeding if your speed is above Y% (say 10%) of the speed limit (you are advised to refer to your State’s driving rules’ book). By default, it is 0.1, which means RM will start preemption for a queue only when it goes 10% above its guaranteed capacity – this avoids sharp oscillations of capacity allocated.
(7) yarn.resourcemanager.monitor.capacity.preemption.natural_termination_factor
Similar to total_preemption_per_round, we can apply this factor to slowdown resource preemption after preemption-target is computed for each queue (for e.g. “give me 5G resource back from queue-A”). By default, it equals to 0.2, meaning that at most 20% of the target-capacity is preempted in a cycle.
For example, if 5GB is needed back, in the first cycle preemption takes back 1GB (20% of 5GB), 0.8GB (20% of the remaining 4GB) in the next, 0.64GB (20% of the remaining 3.2GB) next and so on – a sort of a geometrically smoothened reclamation.You can increase this value to make resource reclamation faster.
Conclusion & future work
In this post, we have given an overview of CapacityScheduler’s preemption mechanism, how it works and how user-land applications interact with the preemption process.
For more details, please see the Apache JIRA ticket YARN-45 (YARN preemption support umbrella). We’re also continuously improving preemption support in YARN’s CapacityScheduler. In the near future, we plan to add:
- Support preemption of containers within a queue while also respecting user-limit (YARN-2069)
- Support preemption of containers while also respecting node labels (YARN-2498)
More efforts are in progress. Given that preemption is tied to the core of scheduling, any new scheduling functionality potentially needs corresponding changes to the preemption algorithm, so improving preemption is always an ongoing effort!
Acknowledgements
We would like to thank all those who contributed patches to CapacityScheduler’s preemption support: Carlo Curino, Chris Douglas, Eric Payne, Jian He and Sunil G (besides the authors of this post). Thanks also to Alejandro Abdelnur, Arun C Murthy, Bikas Saha, Karthik Kambatla, Sandy Ryza, Thomas Graves, Vinod Kumar Vavilapalli for their help with reviews! And thanks to Tassapol Athiapinya from Hortonworks who helped with testing the feature in great detail.
Editor's Choice


Hi, this doesn’t seem to work in Hadoop Yarn 3.2.1 (works with Hadoop Yarn 2.7.0), please suggest how to achieve demand/capacity based preemption, thank you
Arunachalam, I will be surprised if this won’t work anymore in 3.2.1, what is the specific issue you see?