


This post describes an architecture, and associated controls for privacy, to build a data platform for a nationwide proactive contact tracing solution.
Background
After calls for a way of using technology to facilitate the lifting of restrictions on freedom of movement for people not self isolating, whilst ensuring regulatory obligations such as the UK Human Rights Act and equivalent GDPR provisions, this paper proposes a reference architecture for a contact pairing database that maintains privacy, yet is built to scale to support large-scale lifting of restrictions of movement.
Contact Tracing
This article in Science Magazine proposes an App that could be installed on mobile phones in order to alert people who have come into contact with someone who was pre-symptomatic in order to allow them to self-isolate and this app is reportedly under development by NHSX. By using such a system it would be possible to significantly improve the speed at which social distancing restrictions can be lifted.
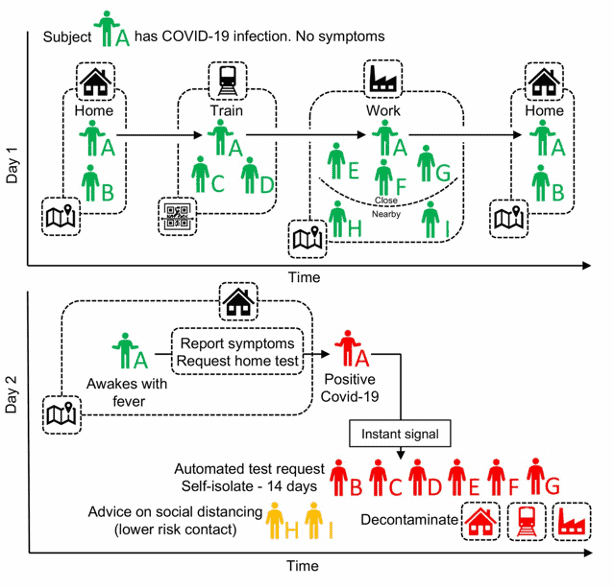
Source: Quantifying SARS-CoV-2 transmission suggests epidemic control with digital contact tracing, Fig 4
Similar solutions are already in operation in Singapore with its TraceTogether application as well as new projects such as the Pan European Proximity Tracing Initiative https://www.pepp-pt.org/ and https://nexttrace.org/about/ in the US. Enterprise-class open-source software supports the critical element of trust in the provision of such applications with robust and resilient security features that can be subject to proper peer review by regulators and authorities.
Maintaining Privacy
In the UK and Europe, the appetite for wide-scale surveillance is low, and therefore it is imperative that the general public have confidence in the privacy of the solution being developed. There would exist a quid pro quo between the individual and the state – by sharing anonymized data about your interactions, you are able to have enhanced freedom of movement.
Access by public bodies to Bulk Personal Datasets is covered by the Investigatory Powers Act 2016 which lists the Department for Health as a regulated body. As such, safeguards would need to be put in place to ensure that any access by analysts is both necessary and proportionate to the intrusion that is caused. We will look to introduce safeguards into the architecture to protect against misuse and hence increase the public’s trust in the system.
Data Model
A simple data model would be proposed based on three key attributes.
- Each installation of the app has a single UUID. No personal information (name, date of birth, email address) would be harvested.
- The app requires high-level access to Bluetooth information from the device, specifically the device’s MAC address and the MAC address of nearby devices (the device in question would be forced to broadcast its MAC).
- Upon installation the application provides the user with a key code in order to seed the UUID. The user can supply a private key/password/biometric in order that the UUID can be revoked at any time by the user. The resultant UUID acts as the public key.
- The date of observations.
- Additional datasets might include the use of location-aware call descriptor records with suitably hashed subscriber attributes (already in common use for predictive churn analytics) subject to regulatory approval.
Note: Apple and Google have proposed a similar model that includes a Rolling Proximity Identifier that changes every 15 minutes. The specification above also works with this model, however, the Apple/Google approach tends towards a decentralised store of contacts.
In China, it has been reported that contactless thermometers can be used in public places to take temperature readings of individuals. This would also be a possibility here, but we would only associate an observed temperature reading with a QR code containing the UUID of the device. Again, no PII is collected here, but a high-temperature reading could then be used to flag at-risk UUIDs to devices which have come into contact with that device.
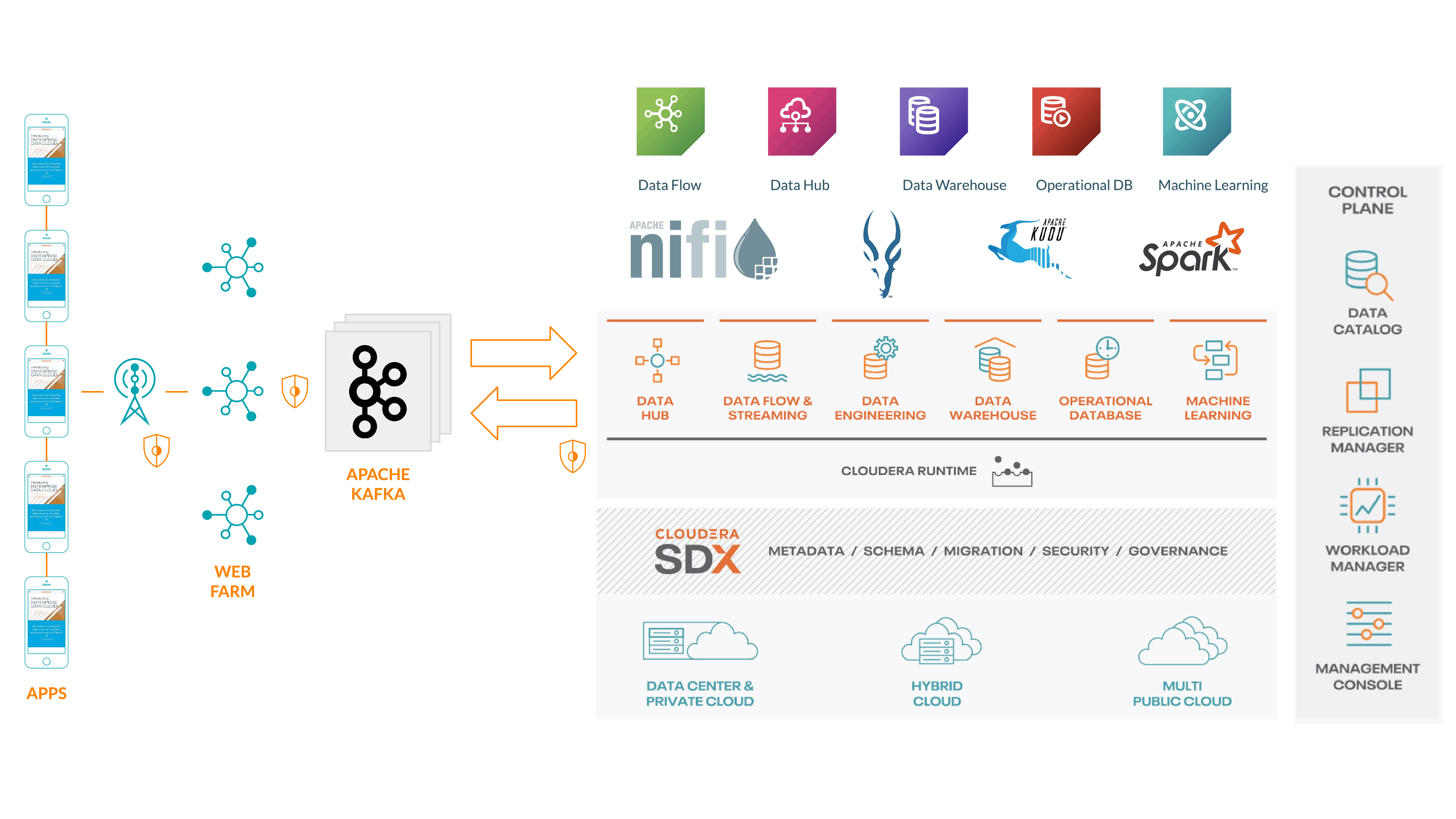
System Architecture
In order to run this technology at population-scale, careful architecture design would be required in order to ensure the Consistency, Integrity and Availability of the solution, as well ensuring that the data is not susceptible to unauthorized access.
Ingest
For a European country such as the UK we would assume an install base of 30 million individuals, who potentially may come into contact with upwards of 200 people per day (especially in high-density areas such as London), we need an ingest architecture that can scale to well over 6 billion events per day. We need to ensure continuous fault tolerance of the pipeline in order to ensure we don’t suffer from outages in availability.
Apache Nifi and Apache Kafka are ideal technology solutions for this type of ingest architecture and are trusted by web-scale technology companies around the globe and can include wire-encryption along all pathways.
In this case we will front a web-farm with a REST API that forwards onto Apache Kafka and then use Apache Nifi to consume the events from Kafka and forward onto the CDP data lake where analytics and machine learning can be performed. The mobile app itself would make the REST calls posting the UUID, location data and observation timestamp over a TLS-secured collection, ensuring that data cannot be intercepted by malicious or surveillance actors.
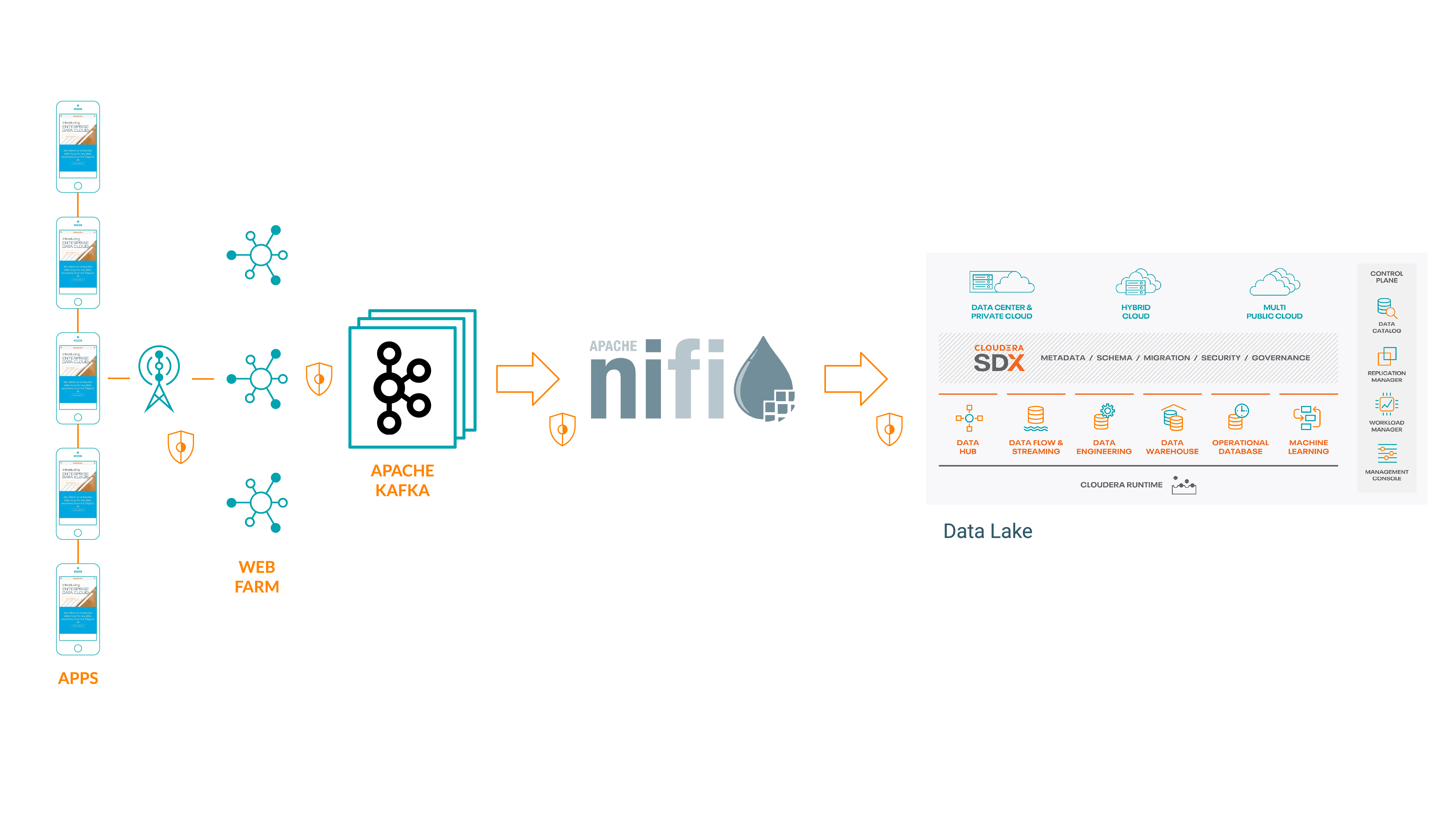
Where streaming analytics is required, perhaps to provide real-time analytics of the extent to which geo-specific social-distancing measures are reducing the number of potential transmission opportunities, Apache Flink and/or Apache Spark with Structured Streaming could both be used.
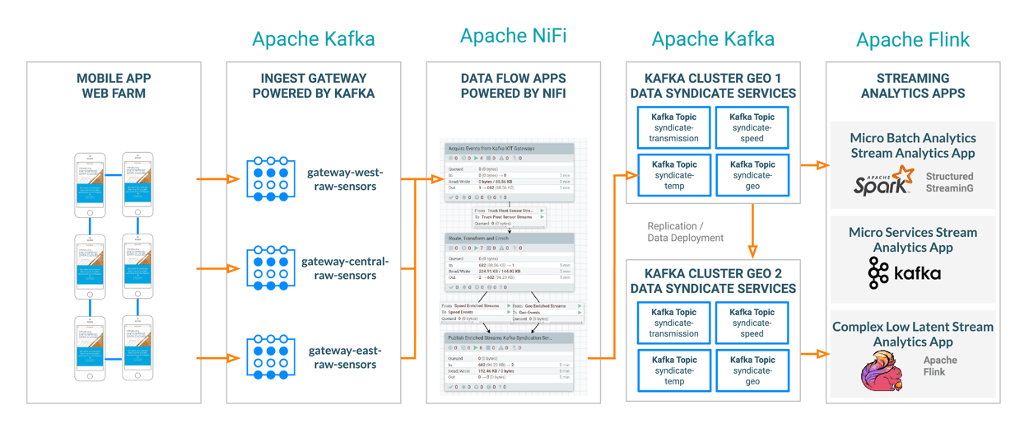
Storage
For the data warehouse layer we need a solution that can deal with high throughput streaming ingest as well as fast random access and good scan performance and Cloudera’s Real Time Data Warehouse offering. Todd Lipcon recently demonstrated that Apache Kudu is able to sustain high levels of ingest throughput whilst delivering fantastic scan performance, which we would want to leverage when we have a suspected infection that we need to trace.
With Kudu we also get the following benefits:
- Range partitioning allows us to drop partitions as they age out over a 2-3 week period.
- Interactive SQL analysis via Apache Impala
- Attribute based access control with Impala via Apache Ranger
- Auditing of SQL queries via Apache Ranger
- On-disk encryption when used in conjunction with Cloudera Navigator Encryption.
- Multi-function query support, with bindings for Apache Spark and Apache Hive.
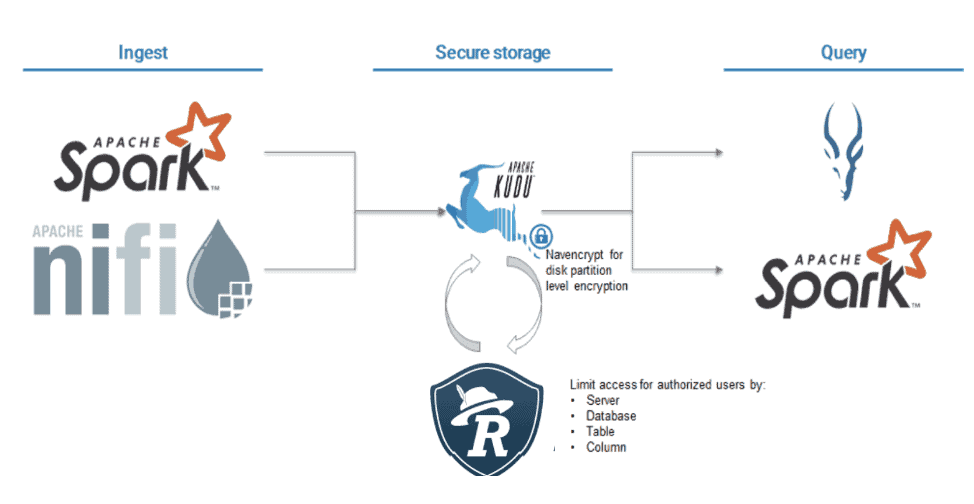
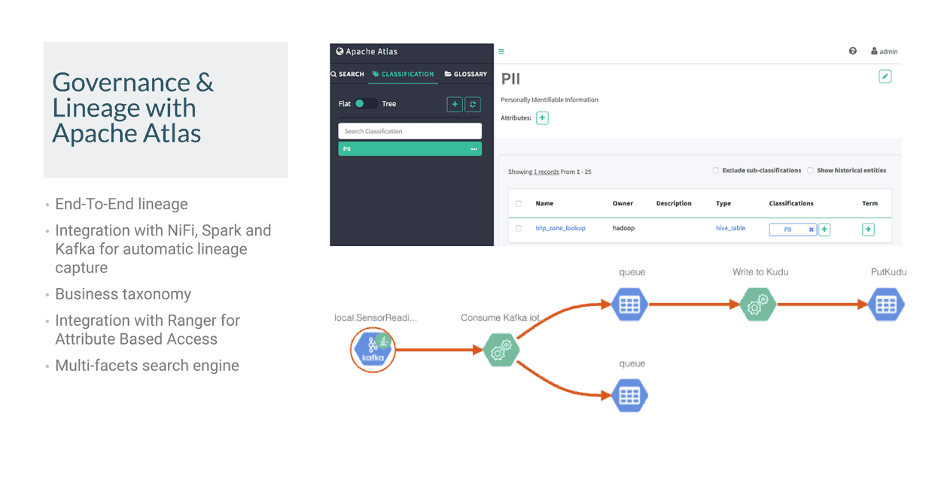
Our overall end to end architecture can leverage the breadth of the Cloudera Data Platform, whether hosted on-premises or in the public cloud. By combining the strengths of technologies such as Nifi, Impala, Kudu and Spark, all proven at web-scale, combined with the security and governance capabilities of Apache Ranger and Apache Atlas, we are able to demonstrate an extremely high level of assurance that data is being protected.
Alerting
When an alert message is received that indicates that an individual possibly, or is confirmed to be infected with COVID-19, the contact tracing algorithm comes into play. Using Apache Kudu’s fast scan performance, we can easily trace those Bluetooth MAC addresses that have been observed by the app on the patient’s device, and vice versa (this would be a reverse lookup by the MAC of the infected patient).
Once the list of high (first order contacts within 48 hours) and medium priority (second order contacts within 48 hours, or first order contacts with 96 hours) has been identified, we would need to generate an alert to be sent to the devices of those at-risk individuals. Note: We still are not introducing any PII data at this point.
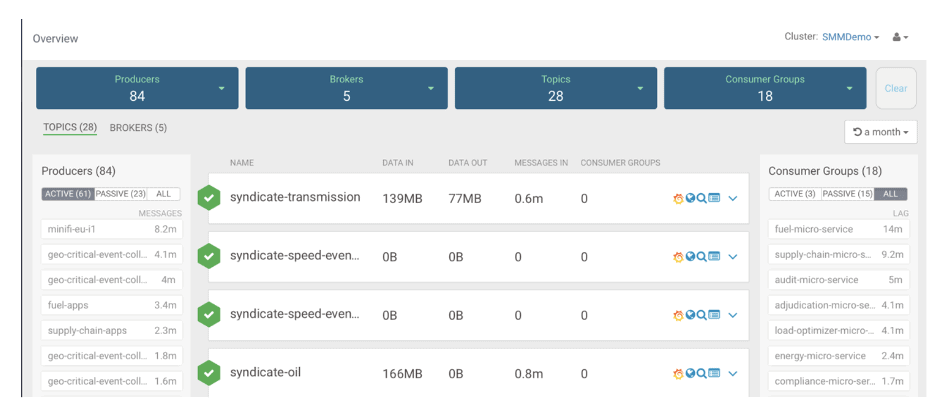
Monitoring Alerts via Kafka Topics with Streams Messaging Manager
Apache Kafka’s publish/subscribe mechanism would be ideal for publishing alerts per UUID, exposed over a REST interface, which can then age off after 48 hours (or an appropriate period of time). An appropriate period of time may be the incubation period of the virus for example. These can be consumed by existing alerting systems such as text messaging and apps with monitoring of the Kafka throughput by Streams Messaging Manager.
Analysis and Machine Learning
As detailed above, access to this data must be necessary and proportionate to the purpose of which it is being queried. Public Health use cases might include monitoring of regional rates of transmission in response to policy interventions. In this case, we will use ensure that:
- All data is encrypted when in transmission and when at rest.
- System administrators do not have access to the datasets themselves (separation of duties).
- All-access is by authenticated and authorised individuals.
- All-access is audited.
In this architecture, all access to the data will be via Apache Impala and as such we can be confident that we will have an accurate audit record of who executed which queries, via Apache Ranger. Apache Knox will ensure that all users are authenticated, via integration with the Public Health Department’s SAML compliant identity provider solution.
Machine Learning access would be via Cloudera Machine Learning (CML) which runs on Kubernetes containers in the public cloud (or via Cloudera Data Science Workbench on-premises). Predicting customer churn is one example of a machine learning application. For example, in the Telco space,algorithms are typically trained to recognise signals for propensity to churn which usually relate to poor service provision as a result of signal coverage or a superior competing service. Case Tracing could be supplemented with similar technology that alerts to higher levels of immediate risk and supports the rapid facilitation of practical interventions such hygiene equipment and deep cleans. Once experiments and models are built using CML, CML’s Applications feature could be used to provide access to interactive visualizations.
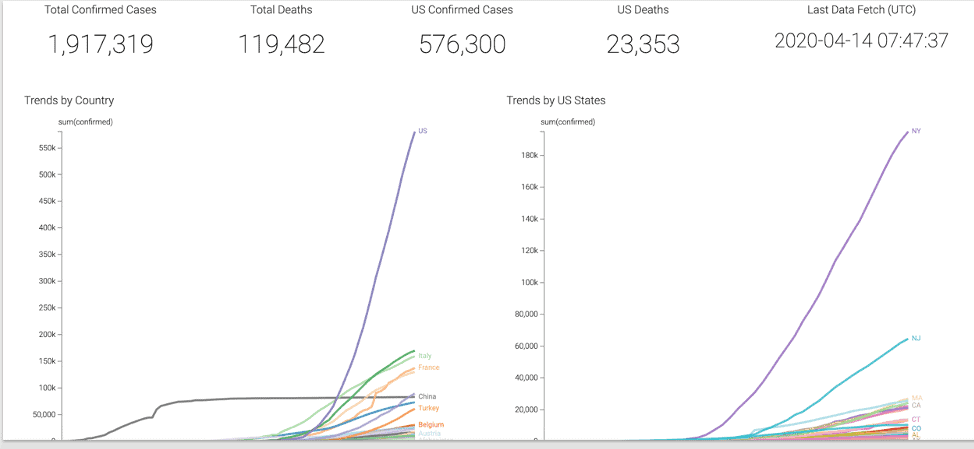
Covid-19 Trends
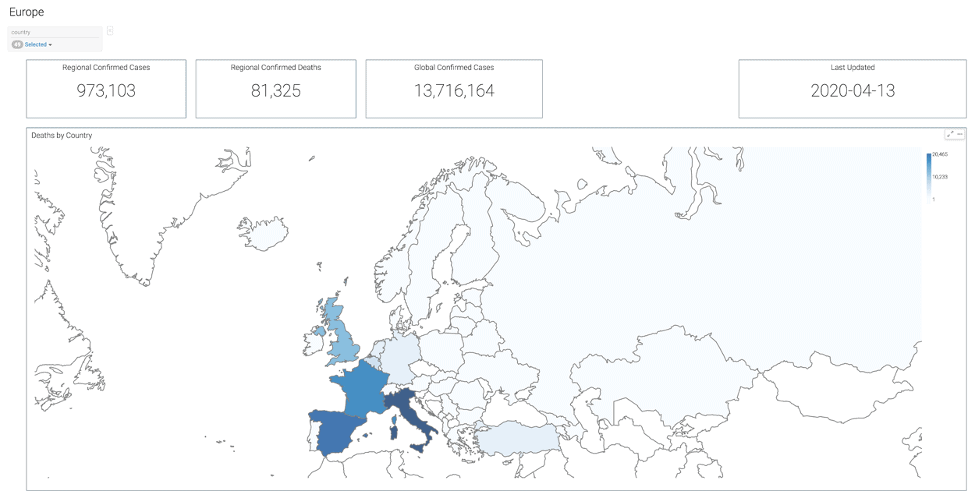
Covid-19 Case by Location
Governance
Critical to the success of such a project is proper governance that can meet the requirements of pre-existing regulations such as GDPR and PCI-DSS. Cloudera Atlas/Navigator/Data Catalogue ensures that administrators and regulators understand:
- Where the relevant data is located
- How that data is interpreted for use
- How the data may have been created or modified
- How the data access is secured and protected
- Auditing of who has access to the data and how it was used
Summary
In this post we summarise an architecture for ingest, analysis and visualisation of a Nationwide COVID-19 contact-tracing data platform built on proven, scalable, open-source technologies, with security and privacy built-in by default to ensure that we are able to balance the privacy concerns and the need for fast, accurate data. For further information contact https://www.cloudera.com/ or your local account representative.
Editor's Choice


Great, great! Thank you for share!
This should terrify all freedom loving people. This is opening up the door for a totalitarian dystopia complete with facial recognition and tracking (under the guise of stopping a pandemic). This is unconstitutional and is not necessary to stop a pandemic. It makes no sense why we are all so afraid of Covid-19. The flu is more serious and kills more people, car crashes kill tons of people, heart disease and cancer kill a lot of people to. We aren’t contact tracing for things that are actually a threat to our safety so why should we contact trace for this?