

Cloudera recently launched CDH 6.3 which includes two new key features from Apache Kudu:
- Fine-grained authorization with Apache Sentry integration
- Backup & restore of Kudu data
Fine-grained authorization with Sentry integration
Kudu is typically deployed as part of an Operations Data Warehouse (DWH) solution (also commonly referred to as an Active DWH and Live DWH). As such, it is typically deployed as the storage engine of choice for streaming ingest using Apache Nifi or Apache Spark and query using Apache Impala and sometimes Spark SQL.
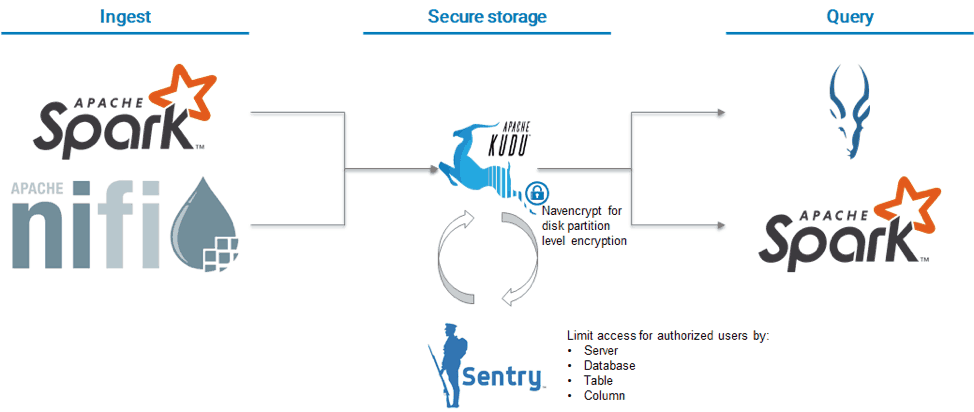
In the past, customers were able to use fine-grained authorization through Impala’s integration with Sentry but could only leverage coarse-grained authorization for ingest or query via Spark This meant that, while Impala based queries could be restricted to users with access to the table or column, other integrations could only be given access to all the tables in Kudu or none.
This solution enabled many customers to move forward with Kudu as long as:
- They didn’t need fine-grained authorization support
- They were in environments where IT was setting up Spark-based ingest pipelines (and were trusted users) and were only using Impala for query (and Impala enforced fine-grained security)
However, this didn’t work for customers that
- Were in multi-tenant environments and IT was not globally trusted to set up everyone’s ingest pipelines
- Wanted to use Spark for query (i.e., data scientists) in addition to Impala
- Wanted to use Kudu APIs but not have their application be responsible for authorization
For the latter group of customers, Kudu now implements direct integration with Sentry in CDH 6.3 enabling Kudu to act as an authorization point regardless of the application used to ingest or query Kudu. As a part of delivering this capability, Kudu introduces the concept of databases which are in essence collections of tables that have a common set of security policies.
Now that Kudu is integrated with Sentry, setting up fine-grained privileges is straightforward with a GRANT statement in Impala:
GRANT privilege ON TABLE object_name TO [ROLE] roleName
Similarly, data scientists, who were restricted from accessing data in Kudu due to a lack of fine-grained security controls, can now also be given access using the same Sentry-based grants. For these users, admins and data owners can also consider using column-level restrictions to ensure that access to sensitive data (e.g., PII) is restricted.
Note: The examples assume that Authentication has already been configured for Kudu, Impala, Nifi, Sentry, and Spark and HMS integration has been enabled. For help configuring authentication, see the Cloudera authentication documentation.
Backup & Restore of Kudu data
Kudu typically stores some of the most valuable data in a company’s data warehouse. As such, you need to be able to back up it up and restore from point-in-time copies as part of both a backup strategy as well as a cybersecurity strategy.
With CDH 6.3, Kudu now provides a toolset for backup, restore and backup management. The Kudu backup tool provides table level backups (Kudu provides a tool to generate a list of tables). The first time the backup tool is run, it will take a full backup. The same tool, with the same arguments, will take incremental backups after the first successful full backup for a table — using an incremental forever backup approach similar to traditional backup solutions for simplicity of use. Full backups can be done at any point with a simple flag (–forceFull). The backup target destination with Kudu’s backup tool can be in HDFS (a component of Apache Hadoop) or cloud storage. For HDFS, erasure-encoded directories are recommended to reduce storage consumption. Backups can be scheduled using your enterprise scheduler.
A separate tool is provided that allows the exploration of Kudu backup sets as well as aging out expired backups and thus reducing the amount of storage used.
A third tool is provided to provide table-level restore from the backup set to Kudu. This tool also allows restoration of data into a different table if you don’t want to overwrite the data that is already present in Kudu (for the relevant table).
If you store backup data in HDFS, you should also use the BDR tool in Cloudera Manager to schedule replication of the backup to other clusters or cloud backup locations allowing the creation of multi-tier backup strategies.

Test Fine Grained Authorization & Backup capabilities to see if you are able to promote Kudu deployments to production.
Editor's Choice


Looking forward for your support