

Airflow has been adopted by many Cloudera Data Platform (CDP) customers in the public cloud as the next generation orchestration service to setup and operationalize complex data pipelines. Today, customers have deployed 100s of Airflow DAGs in production performing various data transformation and preparation tasks, with differing levels of complexity. This combined with Cloudera Data Engineering’s (CDE) first-class job management APIs and centralized monitoring is delivering new value for modernizing enterprises. As we mentioned before, instead of relying on one custom monolithic process, customers can develop modular data transformation steps that are more reusable and easier to debug, which can then be orchestrated with glueing logic at the level of the pipeline. That’s why we are excited to announce the next evolutionary step on this modernization journey by lowering the barrier even further for data practitioners looking for flexible pipeline orchestration — introducing CDE’s completely new pipeline authoring UI for Airflow.
Until now, the setup of such pipelines still required knowledge of Airflow and the associated python configurations. This presented challenges for users in building more complex multi-step pipelines that are typical of DE workflows. We wanted to hide those complexities from users, making multi-step pipeline development as self-service as possible and providing an easier path to developing, deploying, and operationalizing true end-to-end data pipelines.
Easing development friction
We started out by interviewing customers to understand where the most friction exists in their pipeline development workflows today. In the process several key themes emerged:
- Low/No-code
By far the biggest barrier for new users is creating custom Airflow DAGs. Writing code is error prone and requires trial and error. Anyway to minimize coding and manual configuration will dramatically streamline the development process. - Long-tail of operators
Although Airflow offers 100s of operators, users tend to use only a subset of them. Making the most commonly used as readily available as possible is critical to reduce development friction. - Templates
Airflow DAGs are a great way to isolate pipelines and monitor them independently, making it more operationally friendly for DE teams. But a lot of times when we looked across Airflow DAGs we noticed similar patterns, where the majority of the operations were identical except for a series of configurations like table names and directories – the 80/20 rule clearly at play.
This laid the foundation for some of the key design principles we applied to our authoring experience.
Pipeline Authoring UI for Airflow
With CDE Pipeline authoring UI, any CDE user irrespective of their level of Airflow expertise can create multi-step pipelines with a combination of out-of-the-box operators (CDEOperator, CDWOperator, BashOperator, PythonOperator). More advanced users can still continue to deploy their own customer Airflow DAGs as before, or use the Pipeline authoring UI to bootstrap their projects for further customization (as we describe later the pipeline engine generates Airflow code which can be used as starting to meet more complex scenarios). And once the pipeline has been developed through the UI, users can deploy and manage these data pipeline jobs like other CDE applications thru the API/CLI/UI.
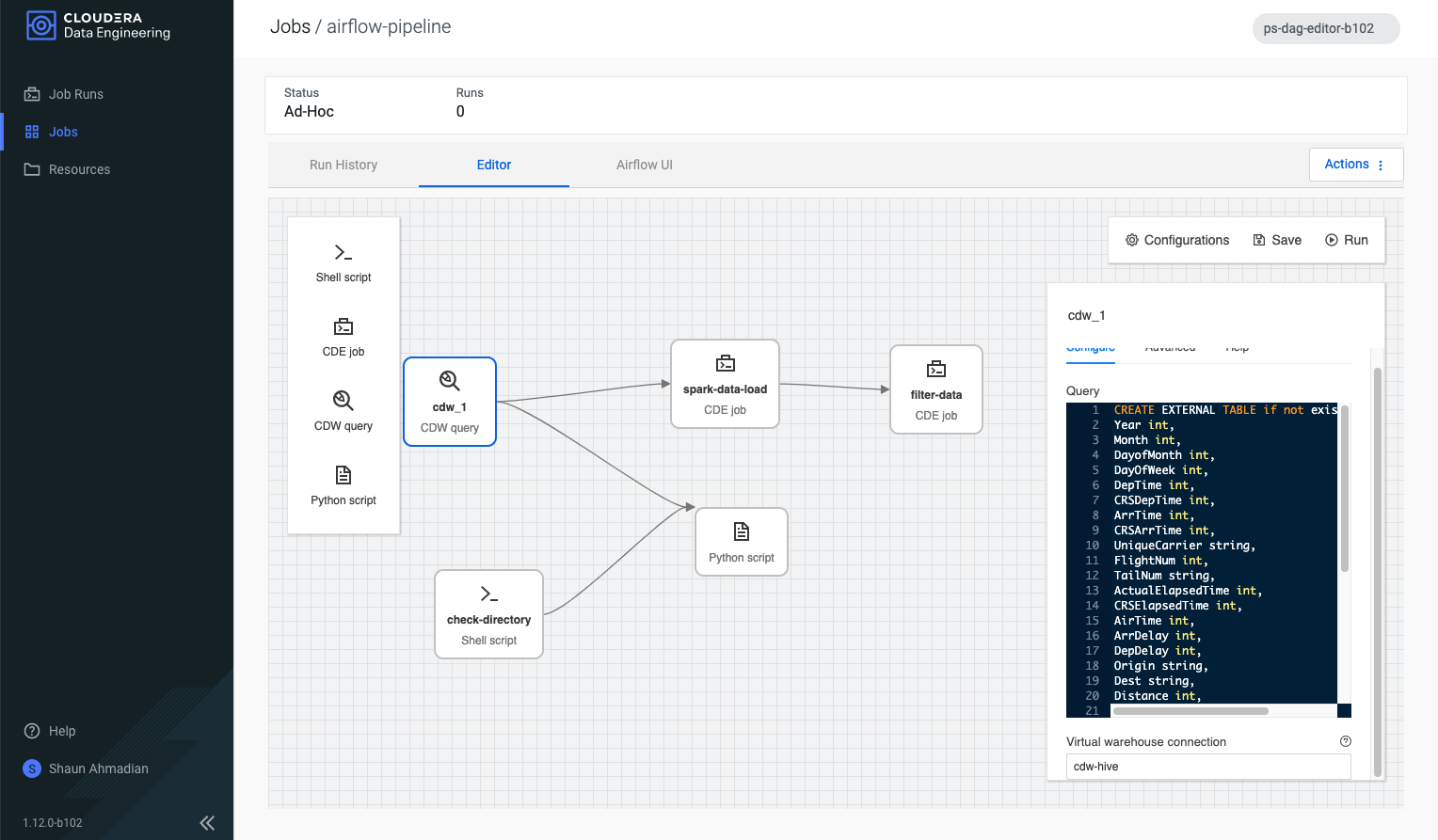
Figure 1: “Editor” screen for authoring Airflow pipelines, with operators (left), canvas (middle), and context sensitive configuration panel (right)
The “Editor” is where all the authoring operations take place — a central interface to quickly sequence together your pipelines. It was critical to make the interactions as intuitive as possible to avoid slowing down the flow of the user.
The user is presented with a blank canvas with click & drop operators. A palette focused on the most commonly used operators on the left, and a context sensitive configuration panel on the right. And as the user drops new operators onto the canvas they can specify dependencies through an intuitive click and drag interaction. Clicking on an existing operator within the canvas brings it to focus which triggers an update to the configuration panel on the right. Hovering over any operator highlights each side with four dots inviting the user to use a click & drag action to create connection with another operator.
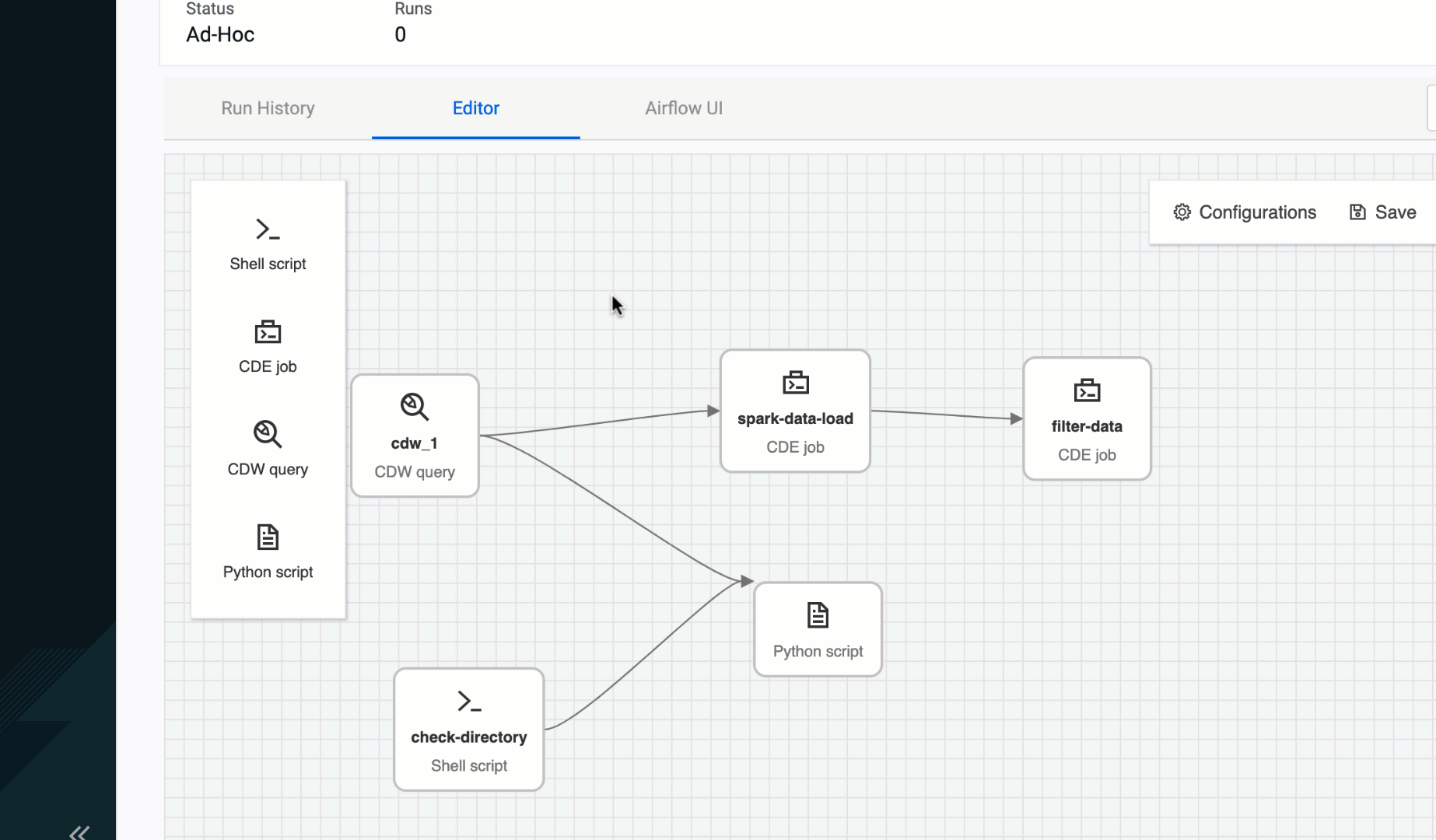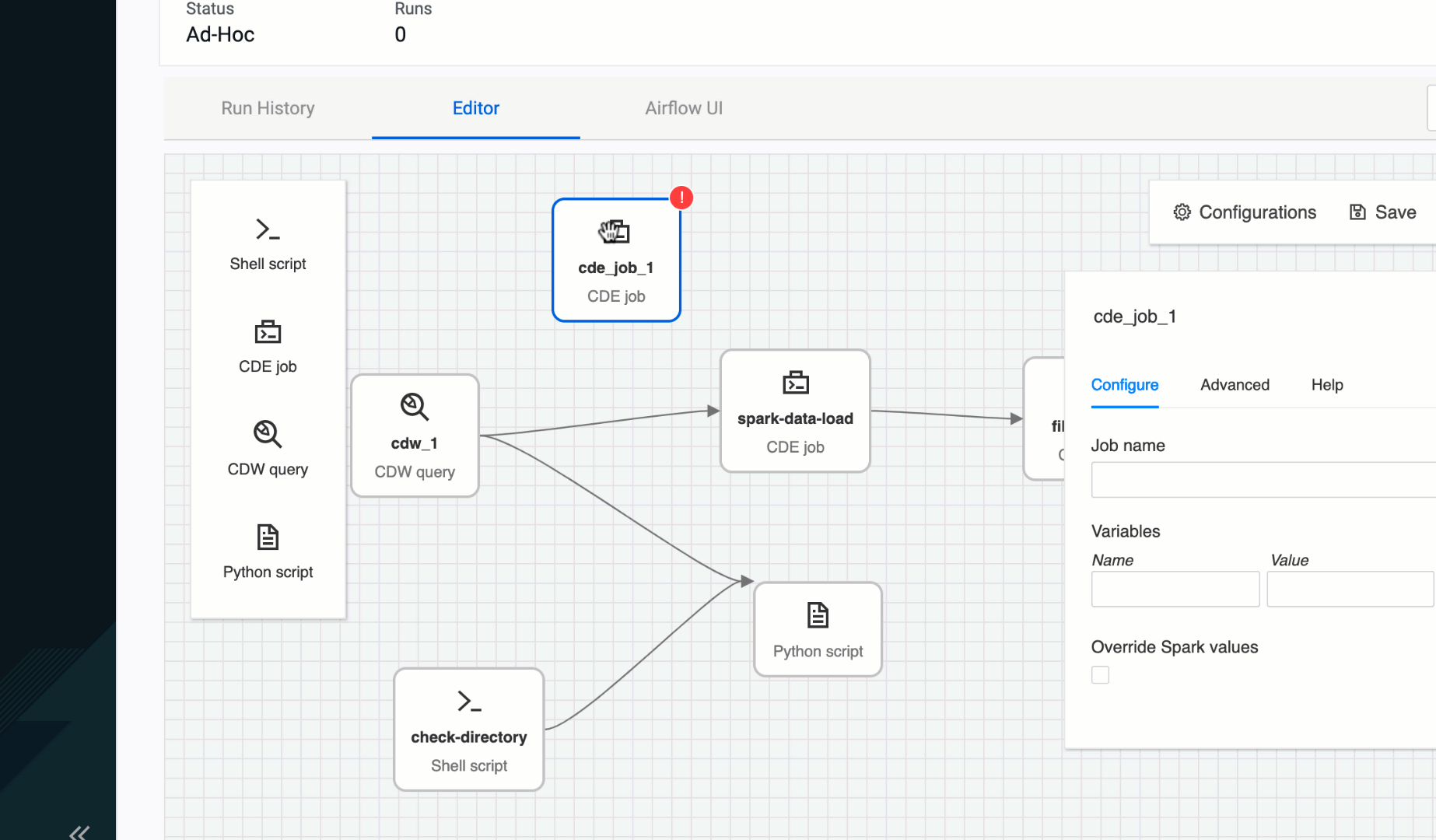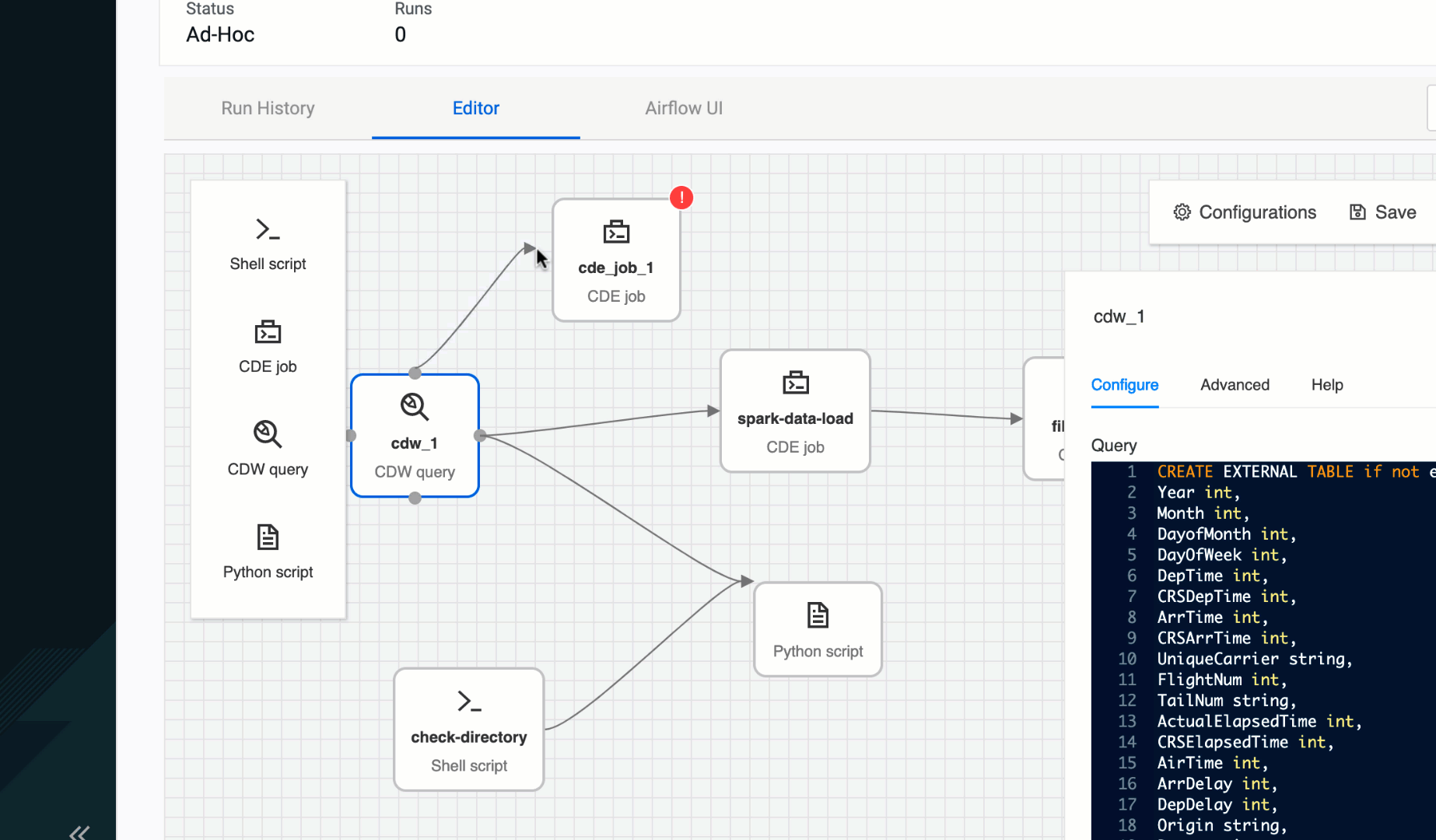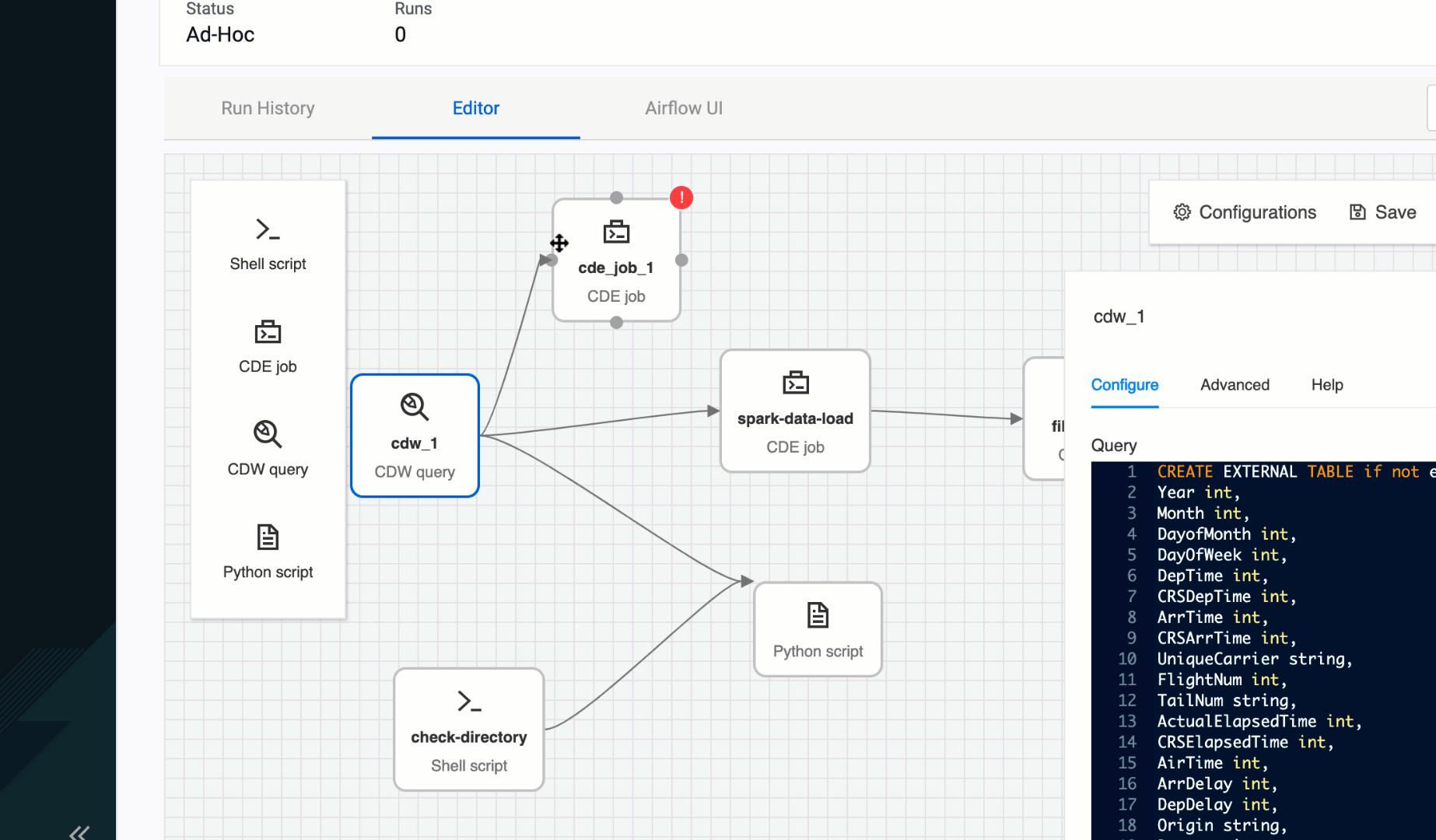
Figure 2: Creating dependencies with simple click & drag
Pipeline Engine
To make the authoring UI as flexible as possible a translation engine was developed that sits in between the user interface and the final Airflow job.
Each “box” (step) in on the canvas serves as a task in the final Airflow DAG. Multiple steps comprise the overall pipeline, which are stored as pipeline definition files in the CDE resource of the job. This intermediate definition can easily be integrated with source code management, such as Git, as needed.
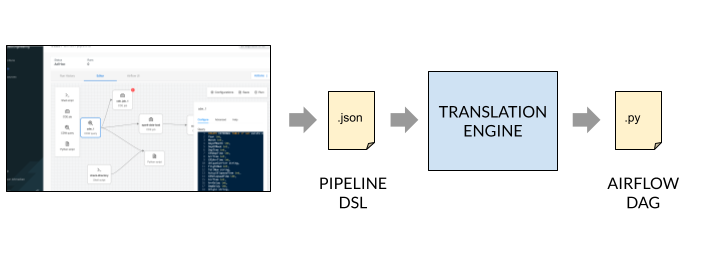
When the pipeline is saved in the editor screen, a final translation is performed whereby the corresponding Airflow DAG is generated and loaded into the Airflow server. This makes our pipeline engine flexible to support multitude of orchestration services. Today we support Airflow but in the future it can be extended to meet other requirements.
An additional benefit is that this can also serve to bootstrap more complex pipelines. The generated Airflow python code can be modified by end users to accommodate custom configurations and then uploaded as a new job. This way users don’t have to start from scratch, but rather build an outline of what they want to achieve, output the skeleton python code, and then customize.
Templatizing Airflow
Airflow provides a way to templatize pipelines and with CDE we have integrated that with our APIs to allow job parameters to be pushed down to Airflow as part of the execution of the pipeline.
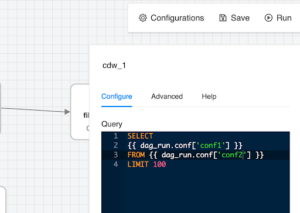
A simple example of this would be parameterizing SQL query within the CDW operator. Using the special syntax {{..}} the developer can include placeholders for different parts of the query, for example the SELECT expression or the table being referenced in the FROM section.
SELECT {{ dag_run.conf['conf1'] }} FROM {{ dag_run.conf['conf2'] }} LIMIT 100
This can be entered through the configuration pane in UIl as shown here:
Once the pipeline is saved and the Airflow job generated, it can be programmatically triggered through the CDE CLI/API with the configuration override options.
$ cde job run --config conf1='column1, sum(1)' --config conf2='default.txn' --name example_airflow_job
The same Airflow job can now be used to generate different SQL reports.
Looking forward
With early design partners we already have enhancements in the works to continue improving the experience. Some of them include:
- More operators – as we mentioned earlier there is a small set of highly used operators. We want to ensure these most commonly used ones are easily accessible to the user. Additionally, the introduction of more CDP operators that integrate with CML (machine learning) and COD (operation database) are critical for a complete end-to-end orchestration service.
- UI improvements to make the experience even smoother. These span common usability improvements like pan and zoom and undo-redo operations, and a mechanism to add comments to make more complex pipelines easier to follow.
- Auto-discovery can be powerful when applied to help autocomplete various configurations, such as referencing pre-defined spark job for the CDE task or the hive virtual warehouse end-point for the CDW query task.
- Ready-to-use pipelines – although parameterized Airflow jobs are great way to develop reusable pipelines, we want to make this even easier to specify through the UI. Also there’s opportunities for us to provide read-to-use pipeline definitions that capture very common patterns such as detecting files on S3 bucket, running data transformation with Spark, and performing data mart creation with Hive.
With this Technical Preview release, any CDE customer can test drive the new authoring interface by setting up the latest CDE service. When creating a Virtual Cluster a new option will allow the enablement of the Airflow authoring UI. Stay tuned for more developments in the coming months and until then happy pipeline building!
Editor's Choice


Hi! great job! what about CDP? is there a release date?
As of today, this is available in CDP data services in the Public Cloud and soon in Private Cloud .