

Data pipelines are in high demand in today’s data-driven organizations. As critical elements in supplying trusted, curated, and usable data for end-to-end analytic and machine learning workflows, the role of data pipelines is becoming indispensable. To keep up, data pipelines are being vigorously reshaped with modern tools and techniques. At Cloudera, we recently introduced several cutting-edge innovations in our Cloudera Data Engineering experience (CDE) as part of our Enterprise Data Cloud product — Cloudera Data Platform (CDP) — to serve the growing demands.
In this three-part blog series, we will outline key elements of our state-of-the-art CDE service – covering motivations (in Part 1), key capabilities (in Part 2), and a step-by-step how-to-guide (in Part 3).
As data pipelines rapidly grow in complexity, scale, and scope, the burden of keeping up and staying agile, falls on the strength and versatility of the solution that power these pipelines. Most data pipelines deployed in production suffer from one or more of the following shortcomings:
- Difficult to orchestrate them at scale, especially with multi-stage transformations
- Lack of automation to deliver good quality data sets in a timely fashion to meet SLAs
- Limited visibility into health and progress of data pipelines at any given point in time
- Challenging to diagnose and troubleshoot issues at one or more stages in the pipeline
- Harmonizing varying security protocols between stages of data pipelines and their downstream applications
- Incomplete visibility into the lineage of the data pipelines from source to target
Often, these can be traced back to the weaknesses in the underlying data engineering solution architectures that have become archaic for modern data pipelines — posing a perennial problem for the data architects, data engineers, and data administrators. This becomes especially acute as the downstream consumers of these pipelines start multiplying in great numbers feeding the likes of data warehouses and machine learning practitioners.
Furthermore, the need for a robust data engineering solution architecture comes to a head when viewed from the lens of the needs of Lines Of Businesses (LOB) that utilize data pipelines as part of the end to end workflows that feed their use cases. In the most common scenario, data is ingested into object stores in the cloud from myriad sources and then curated (formated, corrected, transformed), optimized (structured for specific needs), and orchestrated (sequenced, managed) in a timely manner to feed the downstream LOB use cases. Today’s enterprises are required to ingest, prepare and deliver data faster than ever in history. Because of this, automated, intelligent, and reliable data engineering workflows are key to ensuring a robust end-to-end workflow.
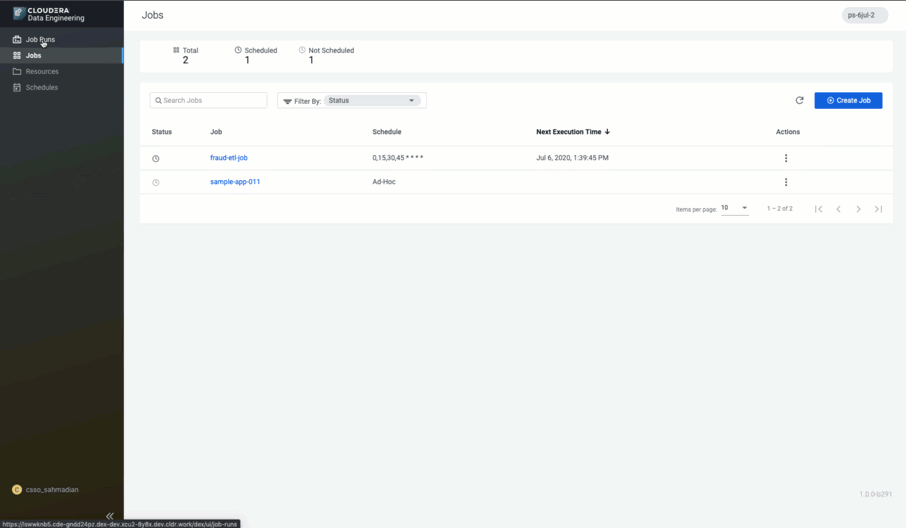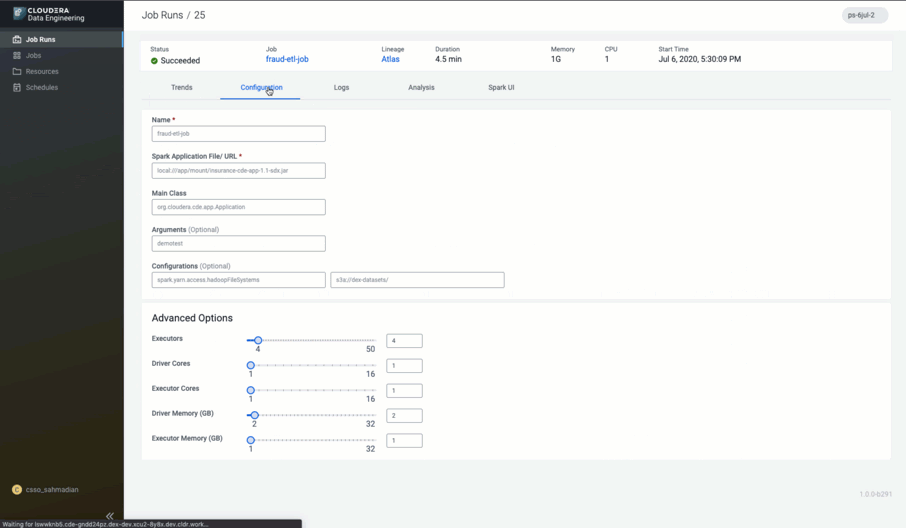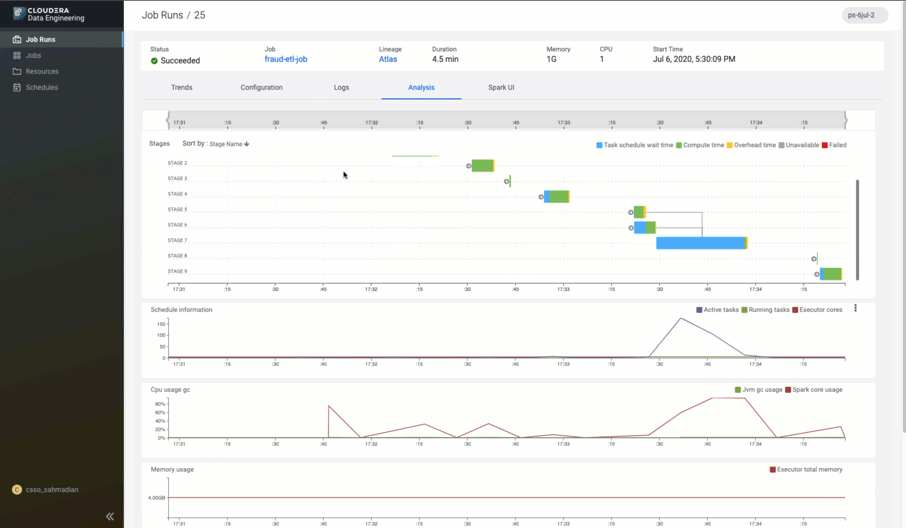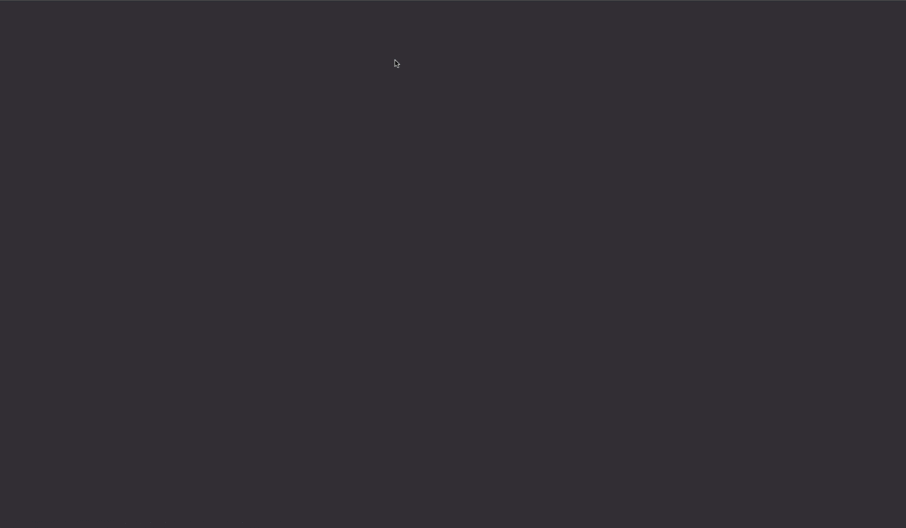
With a fully-featured CDE service in CDP, we are changing the game.
CDE is the only cloud-native service purpose-built for enterprise data engineering teams who are tasked with crafting complex yet reliable data pipelines at scale and across many LOBs. CDE is an all-inclusive data engineering toolset that enables orchestration automation, advanced pipeline monitoring, visual troubleshooting, and comprehensive management tools to streamline ETL processes across enterprise analytics teams.
With CDE we have specifically addressed the shortcomings highlighted earlier, especially in the context of end to end workflows, seamlessly integrating tools such as Apache Spark, Apache Hive, Apache Airflow and Apache Atlas to enable:
- Complex data processing functionality through data frames or SQL or low level distributed data sets to ensure reliable multi-stage transformations at scale
- Quick resolutions to pipeline issues with built-in monitoring and troubleshooting tools
- Robust orchestration using Airflow that allows for flexible flows of the integration and transformation jobs across Spark and Hive engines utilizing latest innovations such as large query isolation in CDP’s Data Warehouse service
- Reliably and quickly deploy end to end LOB workflows via pre-tested integration with other key services in CDP such as Data Flow, Data Warehousing, and Machine Learning
- Integrated with key CDP shared services such as Shared Data Experience (SDX) and Workload Management to offer harmonized security protocols, insightful lineage traceability for the end to end workflows, and an optimal data pipeline health
- Integrate with a wide swathe of 3rd party data sources with Spark to provide an extensive library that can be leveraged in CDE. For example, all common databases (redshift, snowflake, mongo, hbase, … ), service integrations (salesforce) and popular file formats (avro, parquet, ORC, csv…) and dozens more listed here.
- Integration with ISV solutions via CDE APIs (latest partner integration blog here.
Unlike other software products in the market that have taken a fragmented approach towards data engineering, Cloudera is taking a more integrative approach. With CDE, we are satisfying the demand for modernizing critical data pipelines not as isolated data processing, but as part of end-to-end workflows that power LOB use cases.
In the next blog in this series (Part 2), we will explore, in detail, key capabilities of the Airflow orchestrated CDE solution and highlight their value in modernizing data pipelines.
To learn more about leveraging data engineering for analytics success, download the Taking Your Data Lifecycle to the Next Level eBook.
Editor's Choice


Really great content and explanation.
Where is the link for part-2 and part-3