

On May 3, 2023, Cloudera kicked off a contest called “Best in Flow” for NiFi developers to compete to build the best data pipelines. This blog is to congratulate our winner and review the top submissions.
On the verge of the release of NiFi 2.0, Cloudera VP of Engineering and NiFi founder Joe Witt, joined by principal committers Mark Payne and Matt Gillman, addressed the global community via a virtual event dubbed “Meet the Committers.” The team discussed NiFi’s origins and the journey to NiFi 2.0 as well as significant features in the upcoming release, and surveyed the community about the dev/ops challenges of managing their own nodes. As part of the event, Cloudera kicked off the “Best in Flow” contest. The contest challenged developers to build data pipelines that represent their business use cases using Cloudera DataFlow. DataFlow is a cloud-native data service powered by Apache NiFi with a streamlined user experience for development and deployment enabling true universal data distribution. For the contest, Cloudera made a sandbox environment available for developers to use DataFlow Public Cloud. We had more than 40 developers active in the environment and many high-quality contest submissions. But in the end there could only be one winner.
Best in Flow champion
So without any further ado, our winner and the new Best in Flow Champion is:
Vince Lombardo! Vince is a Senior Infrastructure Engineer at Wells Fargo, and he developed a cybersecurity pipeline to efficiently collect, process, and make data from an asset polling tool available for database ingestion. Cybersecurity is a common domain for DataFlow deployments due to the need for timely access to data across systems, tools, and protocols. What’s interesting about Vince’s tool is that it cleverly uses “pagination” functionality to continuously distribute up-to-the minute results from a tool that doesn’t always return a full set of results instantly. For more detail on the winning flow, check out Vince’s github page here.
Vince’s winning flow
Vince began by funneling data from six API endpoints from an asset polling tool containing cybersecurity and tech ops data into two discrete data topics. The flow he built differentiates between test or true API call before initiating a secure log in. The brilliant part comes next. Because the polling tool can take time to return queries, Vince added a processor to loop until the query completes, returning query status until the query is complete. Completeness is estimated by comparing a test result with “estimated total.” When a near match is detected, the data pull is triggered and then checked again for completeness before being transformed into rows and columns and merged into a batch for database ingestion.
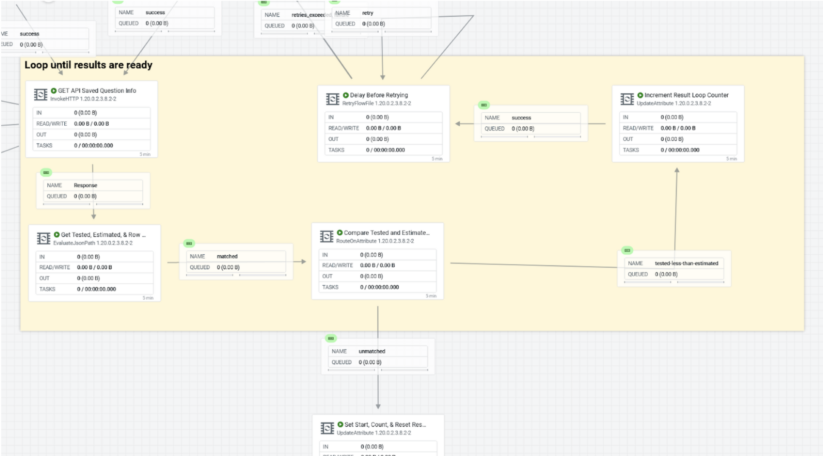
Figure 1: The part of the flow that loops until the Tanium query has completed
Vince’s flow met all of our criteria and was the clear contest winner. This flow is complete and adheres to NiFi best practices being both efficient and highly secure. By utilizing pagination, this dataflow ensures a complete result set is readily available from a data source with highly variable query execution times. It is deployable, has clear business value, and serves as a great example of universal data distribution in action. Congratulations Vince!
Runner up
Ramakrishna Sanikommu was our runner up. His submission post can be found here. RK built some simple flows to pull streaming data into Google Cloud Storage and Snowflake. Many developers use DataFlow to filter/enrich streams and ingest into cloud data lakes and warehouses where the ability to process and route anywhere makes DataFlow very effective. RK built multiple flows quickly, first pulling multiple data sources from a Google Pub/Sub topic and merging them into a file for ingestion into GCS. He then built a second flow to execute a Python script and load the data into Snowflake. His flows adhered to best practices and demonstrated some light transformations. RK properly used the DataViewer as well to view contents of a queue.
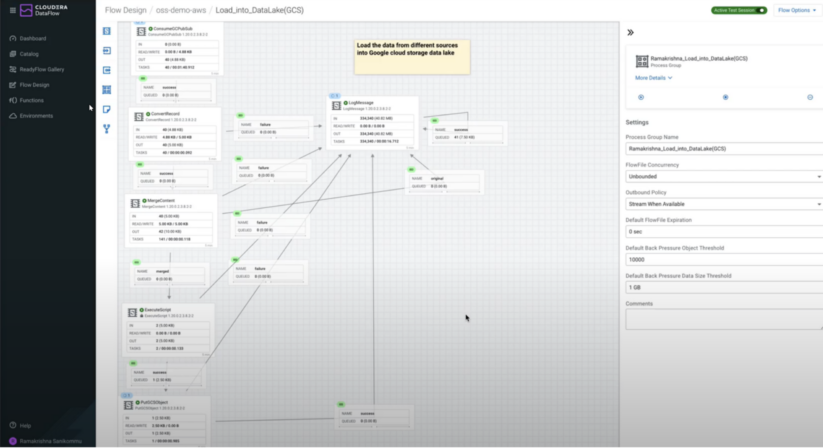
Figure 2: Ramakrishna’s first flow consuming data from Google PubSub and ingesting it into Google Cloud Storage
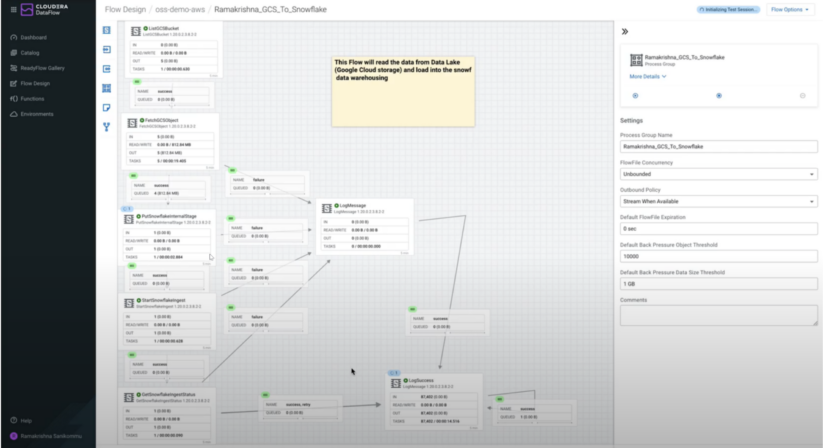
Figure 3: Ramakrishna’s second flow reading data from Google Cloud Storage and ingesting it into Snowflake
Summary and looking ahead
In less than 10 years since its inception, NiFi has achieved absolutely massive scale both in terms of popularity and the size of deployments. NiFi’s origins, however, were quite simple—for any two systems to work together, there are quite a few things that have to agree. They must not only speak some common data language but account for myriad things like relevance, security, priority, authorization, etc. NiFi was built as a sort of Swiss Army Knife to quickly connect different systems and coordinate dataflows from one to another using an intuitive no-code development canvas.
Since acquiring the company primarily responsible for maintaining the NiFi code base in 2015, Cloudera has continued to pour resources into the Open Source project, which now boasts more than 500 contributors across the globe and thousands of active community members in Slack. NiFi has evolved considerably, staying ahead of security vulnerabilities and adding connectors with releases every quarter. The “Best in Flow” contest was a great deal of fun, and demonstrated the appetite for community around Apache NiFi. Here at Cloudera we are excited to host future events for NiFi developers, so stay tuned to find out what’s next. To test drive Cloudera DataFlow yourself, click here to request a trial of Cloudera Data Platform in the Public Cloud. https://www.cloudera.com/campaign/try-cdp-public-cloud.html
Resources
- Rewatch the Meet the Committers Webinar
- Check out Vince’s GitHub for a detailed walkthrough of his use case and the actual flow definition
- Check out Ramakrishna’s LinkedIn post for a detailed walkthrough of his use case
- Check out the “Best in Flow” GitHub to download the actual NiFi flows
- Sign up for a trial of Cloudera DataFlow
Editor's Choice

