

Today’s customers have a growing need for a faster end to end data ingestion to meet the expected speed of insights and overall business demand. This ‘need for speed’ drives a rethink on building a more modern data warehouse solution, one that balances speed with platform cost management, performance, and reliability.
A typical approach that we have seen in customers’ environments is that ETL applications pull data with a frequency of minutes and land it into HDFS storage as an extra Hive table partition file. In this way, the analytic applications are able to turn the latest data into instant business insights. The design cost of this however is that most often the source data for a given partition is not growing fast enough to be accumulated at the expected file size within minutes. This results in platform performance issues and data replication challenges while handling billions of small files and millions of table partitions after a long-running time.
Cloudera, an innovator in providing data products to address these types of challenges, has introduced some new products, such as Kudu low-latency storage and Druid high-performance real-time analytics database that have been successfully implemented in the customer on-premises data centres for these types of real-time data warehousing use cases.
Today, more and more customers are moving workloads to the public cloud for business agility where cost-saving and management are key considerations. A new solution integrating cloud object storage, with Cloudera’s NiFi dataflows, a Kafka datahub, and a Hive virtual warehouse in the CDW service allows businesses to take the best advantage of this public cloud trend.
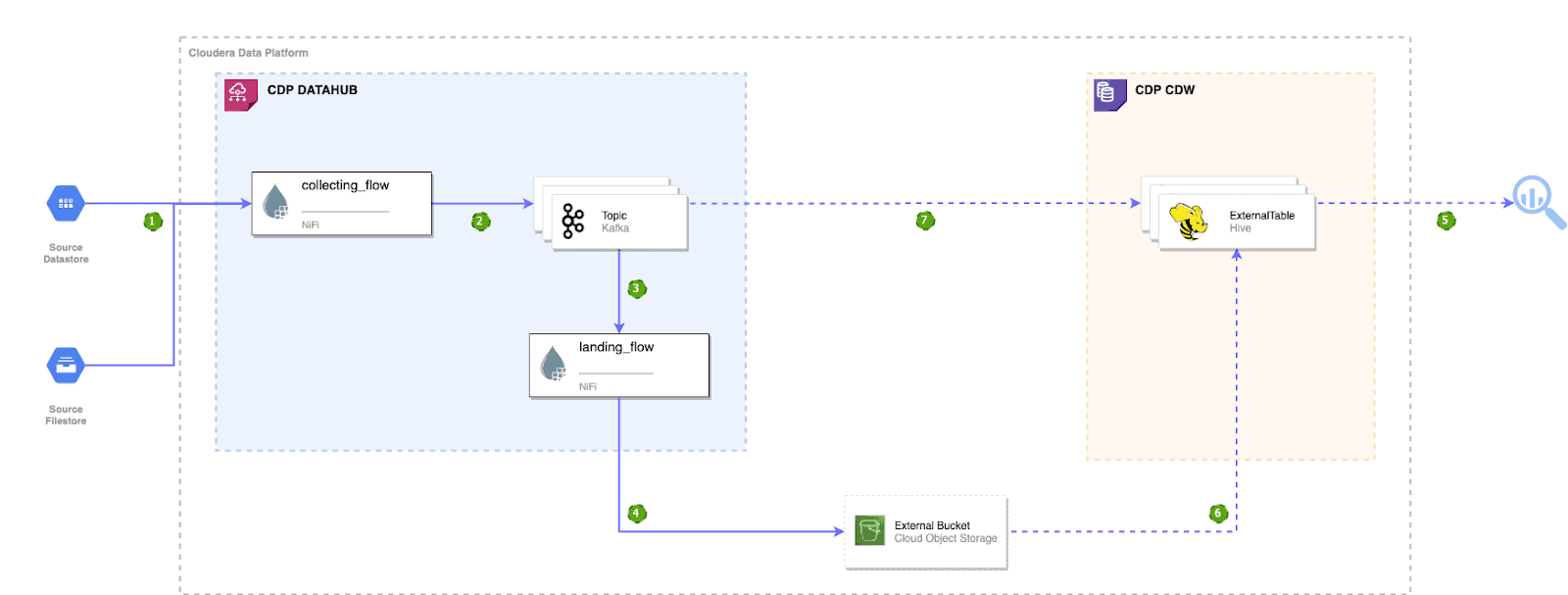
The Cost-Effective Data Warehouse Architecture
From the data ingestion perspective, in the CDP datahub cluster, a NiFi collecting dataflow is designed to continuously collect and process source streaming data then publish it into a Kafka topic in real-time. Another NiFi landing dataflow consumes from this Kafka topic and accumulates the messages into ORC or Parquet files of an ideal size, then lands them into the cloud object storage in near real-time.
In terms of data analysis, as soon as the front-end visualization or BI tool starts accessing the data, the CDW Hive virtual warehouse will spin up cloud computing resources to combine the persisted historical data from the cloud storage with the latest incremental data from Kafka into a transparent real-time view for the users.
This architecture has the following benefits
- Cost-Effective
Cloud object storage is used as the main persistent storage layer, which is significantly cheaper than block volumes. In addition, it also provides an efficient cost model that scales capacity dynamically by usage, instead of having to provision a fixed amount in advance. Thanks to the auto-scaling features in CDW, the data warehouse computing resources are only metered when the analytic workload is running, and it will be automatically suspended if the workload is idle. This perfectly suits the typical pattern of ad hoc exploration, reporting, and data science workloads.
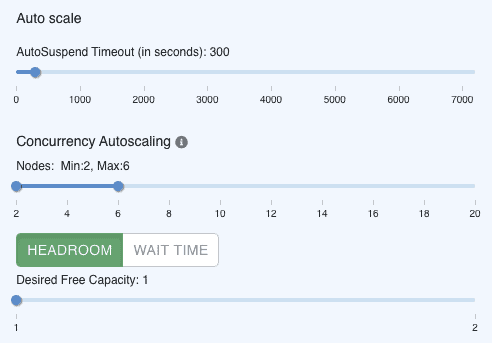
CDW Auto-Scaling Options
- Separate Ingestion from Analysis
One of the key tenets of CDP is separation. It separates computing from storage to allow each to scale independently and to allow for transient compute clusters. It separates data catalogs and workloads to enable better isolation which makes it easier to maintain SLAs and ensure security isolation. This solution follows this principle to separate ingestion workloads from analysis workloads. Ingesting into cloud storage directly is independent of any data warehouse compute services, which resolves a common issue in the traditional data warehouse that ETL jobs and analysis queries very often compete against each other for resources.
- Low Maintenance
In the real-time layer, Kafka automatically cleans the historical events with configurable retention. This mature feature makes it very stable without additional scripting which is common in traditional solutions. While in the persistent layer, the records are regularly saved as column-oriented ORC or Parquet files between 5 to 10 GB. This will dramatically improve the physical health of the data warehouse and keep it well-behaved for the longer-term.
- Adoptable
Additionally, the real-time view is transparent for the front-end SQL. The business teams can embrace real-time with their most familiar SQL tools. Therefore, it’s more adopted by the ecosystem of BI tools and applications.
Design Detail
Partition Strategy
In many large-scale solutions, data is divided into partitions that can be managed and accessed separately. Partitioning can improve scalability, reduce contention, and optimize performance. It can also provide a mechanism for dividing data by usage pattern. However, the partitioning strategy must be chosen carefully to maximize the benefits while minimizing adverse effects.
To efficiently serve business queries, Hive tables normally are partitioned with a few business or time columns, which are structured as partition folders in the ORC/Parquet format.
On the other hand, by default, Kafka picks a partition either in a round-robin fashion or based on the hash value of the message key. Partitioning by key has two problems. Firstly, although it guarantees that the same key is always put into the same partition, it doesn’t ensure that different keys would be in different partitions. Second, if the partition number is increased after the system goes live, the default Kafka partitioner will return different numbers evenly if you provide the same key, which means messages with the same key as before will be in a different partition from the previous one. An alternative approach is to use a Kafka custom partitioner with a mapping between the Kafka partition number and the value of a business-relevant column, such as a ‘category’ column is used to identify the type of transaction being processed in the banking context. Adding new mapping entities in line with Kafka topic partitions will not impact the existing keys’ partition location. However, this solution only supports static and low-cardinality columns as the partition key.
We choose to keep the best partition strategies, round-robin partition in Kafka and business or timestamp column partition in Hive respectively. The following examples are based on business column partitioning, the timestamp partitioning can be altered slightly.
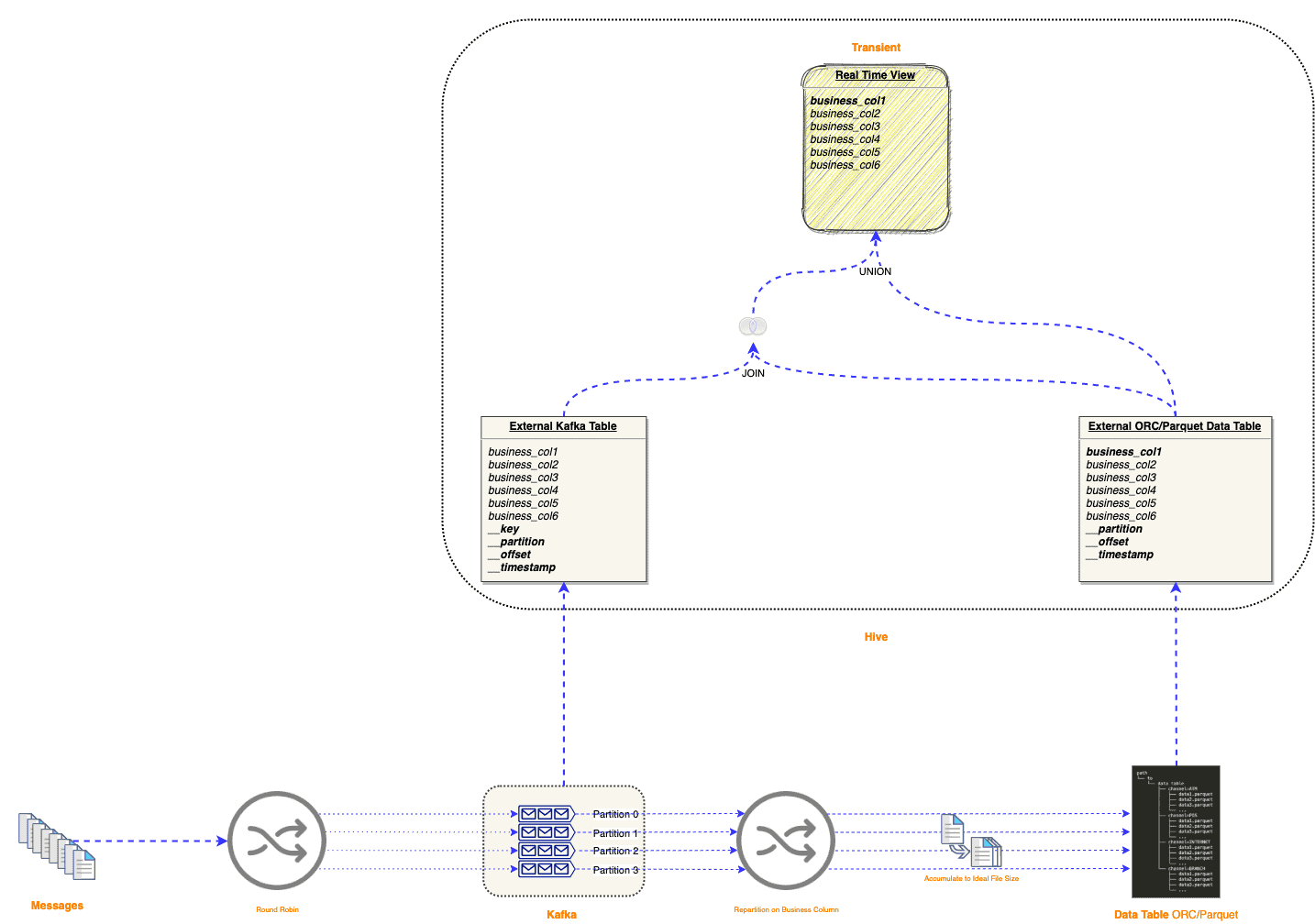
Hive table and Kafka partition relationship
Data Tiering
After we have the Kafka table and the ORC/Parquet table in Hive, 4 tiers can be built on top of these two base tables.
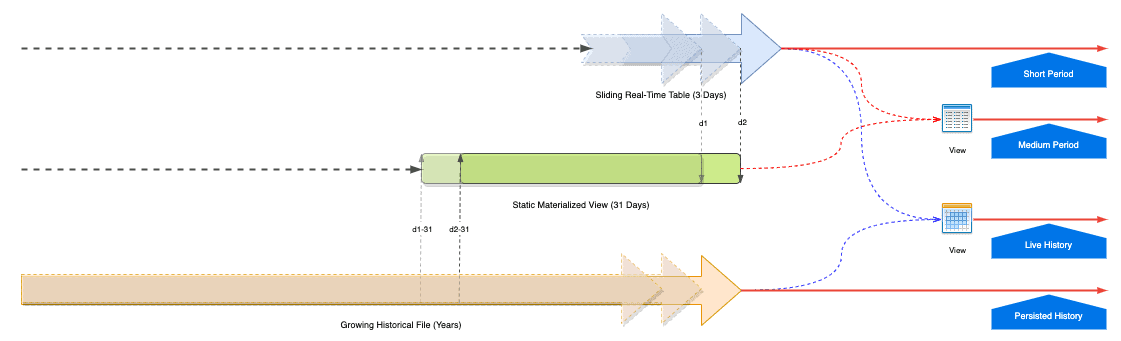
4 Data Tiers
- Short Period Tier
The Hive Kafka Table contains short period live data, 1-3 days is recommended. If the use cases only require the latest short period data, this tier is recommended as it’s the fastest. Moreover, additional shorter sliding views, such as 10 minutes or 1 hour, can be created in this tier for specific use cases.
- Medium Period Tier
More often than not, the data in the recent 1 or 3 months is also required. To address this, a regular 31-day Hive Materialized View is built by combining the base ORC/Parquet table and Kafka table. The query performance is significantly better than the big Hive external ORC/Parquet table. When it’s refreshed every 8 hours or 12 hours by Hive Scheduled Queries, the earliest records are moved ahead correspondingly. And the latest live data is available by combining the Kafka table. This tier is relatively fast.
- Live History Tier
Not very often, the long history real-time data is asked. If it’s the case, the Hive View on top of the ORC/Parquet table and Hive table meets this requirement. But the query performance in this tier is the slowest.
- Persisted History Tier
The history data is always required for certain industry regulatory compliance. This tier is lagging minutes to hours behind the current events. The ORC/Parquet Table is good enough to fit those pure historical use cases. The query performance is better than the full history real-time tier.
To summarize, 4 or fewer tiers can be created for different requirements and use cases. For example, normally ‘Live History Tier’ is ignored since it’s rarely used. The data ingestion and query performance are compared in the following table.
| Tier | Technique | Data Ingestion | Query Latency |
| Short Period Tier | Hive Kafka Table | Real-Time | Seconds |
| Medium Period Tier | Hive Materialized View + Hive Kafka Table | Real-Time | Seconds to Minutes |
| Live History Tier | Hive ORC/Parquet Table + Hive Kafka Table | Real-Time | >> Minutes |
| Persisted History Tier | Hive ORC/Parquet Table | Minutes to Hours Delay | > Minutes |
Schema Management
Avro format messages are stored in Kafka for better performance and schema evolution. Cloudera Schema Registry is designed to store and manage data schemas across services. NiFi data flows can refer to the schemas in the Registry instead of hard coding.
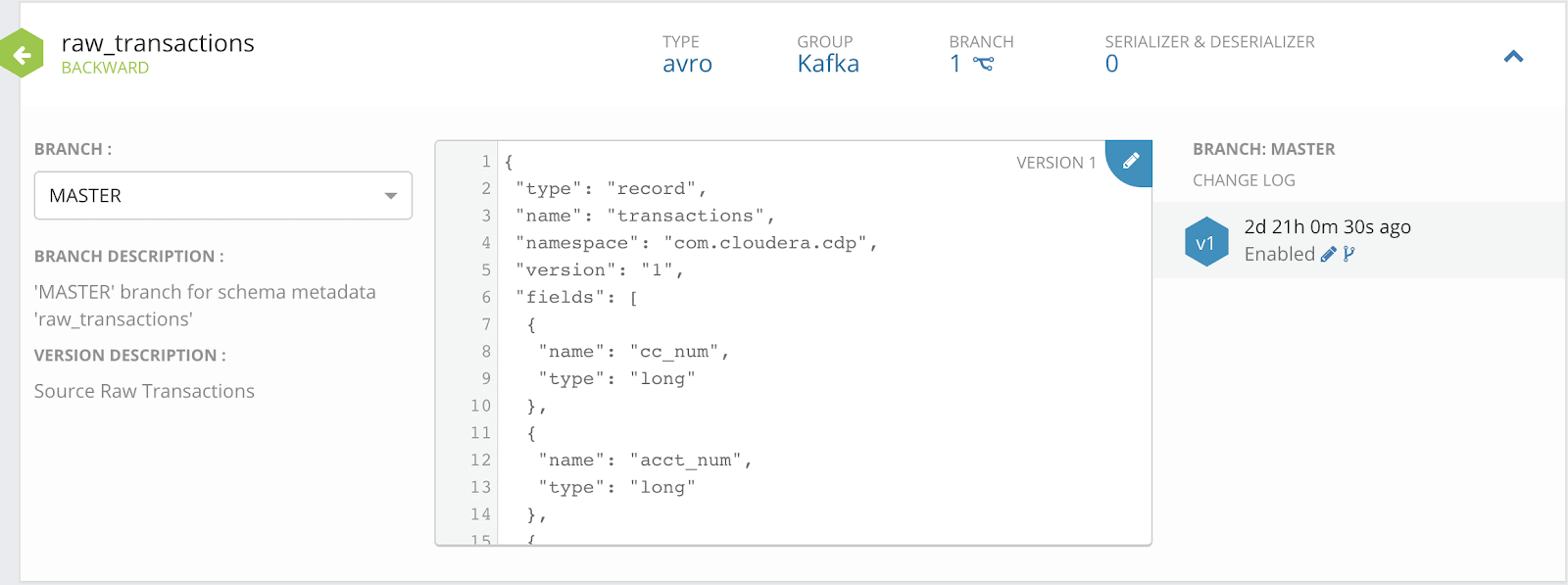
Avro Schema Example in the Cloudera Schema Registry
Here are the two schema details, ‘raw_transactions’ and ‘transactions_with_kafka_metadata’ in the following examples. The former is used in the collecting flow to store Avro into a Kafka topic, while both schemas are required by the landing flow to consume from the Kafka and persist into cloud storage.
{ "type": "record", "name": "transactions", "namespace": "com.cloudera.cdp", "version": "1", "fields": [ { "name": "cc_num", "type": "long" }, { "name": "acct_num", "type": "long" }, { "name": "profile", "type": "string" }, { "name": "state", "type": "string" }, { "name": "lat", "type": "float" }, { "name": "long", "type": "float" }, { "name": "trans_num", "type": "string" }, { "name": "trans_date", "type": "string" }, { "name": "trans_time", "type": "string" }, { "name": "unix_time", "type": "long" }, { "name": "category", "type": "string" }, { "name": "amt", "type": "float" }, { "name": "is_fraud", "type": "int" }, { "name": "merchant", "type": "string" }, { "name": "merch_lat", "type": "float" }, { "name": "merch_long", "type": "float" } ] }
Avro Schema without Kafka Metadata Example
{ "type": "record", "name": "transactions", "namespace": "com.cloudera.cdp", "version": "1", "fields": [ { "name": "cc_num", "type": "long" }, { "name": "acct_num", "type": "long" }, { "name": "profile", "type": "string" }, { "name": "state", "type": "string" }, { "name": "lat", "type": "float" }, { "name": "long", "type": "float" }, { "name": "trans_num", "type": "string" }, { "name": "trans_date", "type": "string" }, { "name": "trans_time", "type": "string" }, { "name": "unix_time", "type": "long" }, { "name": "amt", "type": "float" }, { "name": "is_fraud", "type": "int" }, { "name": "merchant", "type": "string" }, { "name": "merch_lat", "type": "float" }, { "name": "merch_long", "type": "float" }, { "name": "__partition", "type": "int" }, { "name": "__offset", "type": "long" }, { "name": "__timestamp", "type": "long" }, { "name": "category", "type": "string" } ] }
Avro Schema with Kafka Metadata Example
‘__partition’, ‘__offset’, and ‘__timestamp’ are the new fields to be persisted in the ORC/Parquet table. The ‘category’ is the business partition column of the Hive ORC/Parquet table. Why it’s moved to the end of the schema, will be explained later.
The external ORC/Parquet table in this solution is to avoid ingestion relying on the Hive service, thus Hive computing cost is reduced as much as possible. However, to accumulate the files to a bigger size before landing into cloud storage, the persisted history tier ingestion is lagging minutes to hours behind the Kafka tier. If the scenario is not too cost-sensitive, such as in an on-premises environment, a derivative solution with a Hive managed ACID table in the history tier, is recommended. Ingesting via Hive streaming into the Hive managed tables can cut the lag. The managed table files are compacted and managed automatically by the Hive service, moreover, the statistics stored in the Hive metastore would significantly improve the query performance.
One of the key features in this solution, Hive Kafka Storage Handler, is being actively improved by the Cloudera engineering team. It will be fully available shortly in all CDP environments, including CDP Private Cloud Base, CDW in CDP Public Cloud, and CDW experience in CDP Private Cloud.
Cloudera has diverse real-time data warehousing solutions, including but not limited to Druid, Kudu, and Impala, for different environments and requirements. More details are introduced by Justin Hayes in ‘An Overview of Real Time Data Warehousing on Cloudera’.
In the next article, we will explore the implementation detail of this solution.
Thank David Streever, Vicki Zingiris, and Justin Hayes for the review and guidance!
Editor's Choice

