


Please join us on March 24 for Future of Data meetup where we do a deep dive into Iceberg with CDP
What is Apache Iceberg?
Apache Iceberg is a high-performance, open table format, born-in-the cloud that scales to petabytes independent of the underlying storage layer and the access engine layer.
By being a truly open table format, Apache Iceberg fits well within the vision of the Cloudera Data Platform (CDP). In fact, we recently announced the integration with our cloud ecosystem bringing the benefits of Iceberg to enterprises as they make their journey to the public cloud, and as they adopt more converged architectures like the Lakehouse.
Let’s highlight some of those benefits, and why choosing CDP and Iceberg can future proof your next generation data architecture.
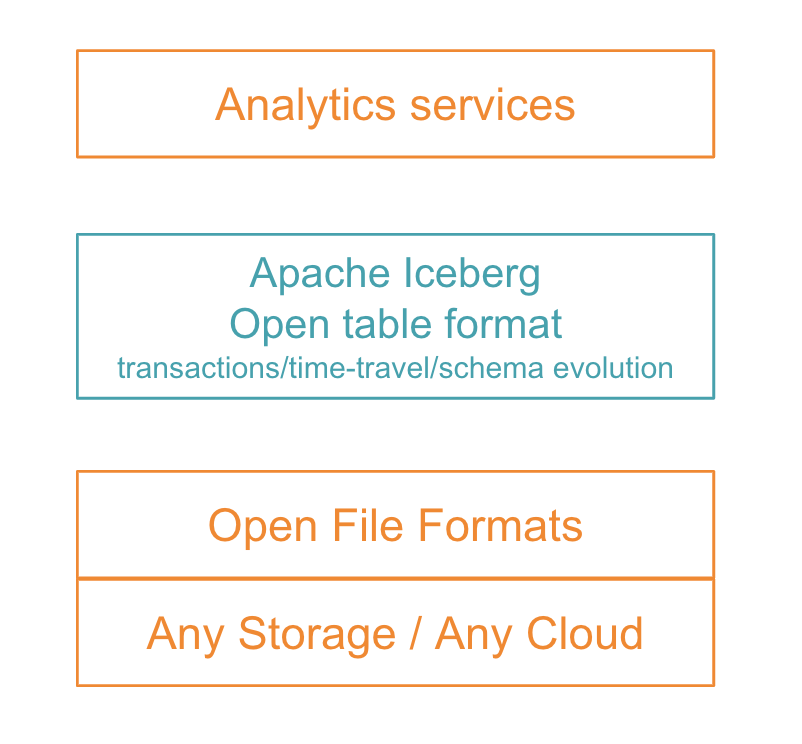
Figure 1: Apache Iceberg fits the next generation data architecture by abstracting storage layer from analytics layer while introducing net new capabilities like time-travel and partition evolution
#1: Multi-function analytics
Apache Iceberg enables seamless integration between different streaming and processing engines while maintaining data integrity between them. Multiple engines can concurrently change the table, even with partial writes, without correctness issues and the need for expensive read locks. Therefore, alleviating the need to use different connectors, exotic and poorly maintained APIs, and other use-case specific workarounds to work with your datasets.
Iceberg is designed to be open and engine agnostic allowing datasets to be shared. Through Cloudera’s contributions, we have extended support for Hive and Impala, delivering on the vision of a data architecture for multi-function analytics from large scale data engineering (DE) workloads and stream processing (DF) to fast BI and querying (within DW) and machine learning (ML).
Being multi-function also means integrated end-to-end data pipelines that break siloes, piecing together analytics as a coherent life-cycle where business value can be extracted at each and every stage. Users should be able to choose their tool of choice and take advantage of its workload specific optimizations. For example, a Jupyter notebook in CML, can use Spark or Python framework to directly access an Iceberg table to build a forecast model, while new data is ingested via NiFi flows, and a SQL analyst monitors revenue targets using Data Visualization. And as a fully open source project, this means more engines and tools will be supported in the future.
#2: Open formats
As a table format, Iceberg supports some of the most commonly used open source file formats – namely, Avro, Parquet and ORC. These formats are well known and mature, not only used by the open source community but also embedded in 3rd-party tools.
The value of open formats is flexibility and portability. Users can move their workloads without being tied to the underlying storage. However, up to now a piece was still missing – the table schema and storage optimizations were tightly coupled, including to the engines, and therefore riddled with caveats.
Iceberg, on the other hand, is an open table format that works with open file formats to avoid this coupling. The table information (such as schema, partition) is stored as part of the metadata (manifest) file separately, making it easier for applications to quickly integrate with the tables and the storage formats of their choice. And since queries no longer depend on a table’s physical layout, Iceberg tables can evolve partition schemes over time as data volume changes (more about this later on).
#3: Open Performance
Open source is critical to avoid vendor lock-in, but many vendors will tout open source tools without acknowledging the gaps between their in-house version and the open source community. This means if you try to go to the open source version, you will see a drastic difference – and therefore you’re unable to avoid vendor lock-in.
The Apache Iceberg project is a vibrant community that’s rapidly expanding support for various processing engines while also adding new capabilities. We believe this is critical for the continued success of the new table format, and hence why we are making contributions across Spark, Hive and Impala to the upstream community. It’s only through the success of the community, that we will be able to get Apache Iceberg adopted and in the hands of enterprises looking to build out their next generation data architecture.
The community already delivered a lot of improvements and performance features such as Vectorization reads and Z-Order, which will benefit users regardless of the engine or vendor accessing the table. In CDP, this is already available as part of Impala MPP open source engine support for Z-Order.
For query planning Iceberg relies on metadata files, as mentioned earlier, that contains where the data lives and how partitioning and schema are spread across the files. Although this allows for schema evolution, it poses a problem if the table has too many changes. That’s why the community created an API to read the manifest (metadata) file in parallel and is working on other similar optimizations.
This open standards approach allows you to run your workloads on Iceberg with performance in CDP without worrying about vendor lock-in.
#4: Enterprise grade
As part of the Cloudera enterprise platform, Iceberg’s native integration benefits from enterprise-grade features of the Shared Data Experience (SDX) such as data lineage, audit, and security without redesign or 3rd party tool integration, which increases admin complexity and requires additional knowledge.
Apache Iceberg tables in CDP are integrated within the SDX Metastore for table structure and access validation, which means you can have auditing and create fine grained policies out-of-the-box.
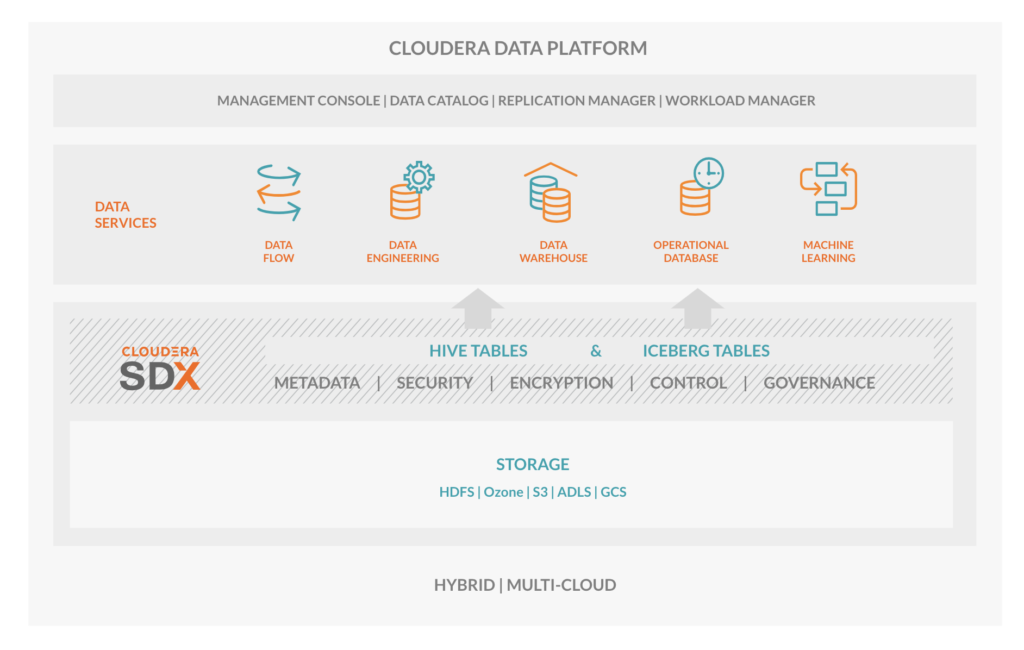
Figure 2: Apache Iceberg within Cloudera Data Platform
#5: Open the door to new use-cases
Apache Hive table laid a good foundation by centralizing table access to warehousing, data engineering, and machine learning. It did this while supporting open file formats (ORC, AVRO, Parquet to name a few) and helped achieve new use-cases with ACID and transactional support. However, with the metadata centralization and by being primarily a file-based abstraction, it has struggled in certain areas like scale.
Iceberg overcomes the scale and performance challenges while introducing a new series of capabilities. Here’s a quick look at how these new features can help tackle challenges across various industries and use-cases.
Change data capture (CDC)
Although not new and available in existing solutions like Hive ACID, the ability to handle deltas with atomicity and consistency is critical to most data processing pipelines that feed DW and BI use-cases. That’s why Iceberg set out to tackle this from day one by supporting row level updates and deletes. Without getting into the details, it’s worth noting there are various ways to achieve this, for example copy-on-write vs merge-on-read. But what’s more important is that through these implementations and continued evolution of the Iceberg open standard format (version 1 spec vs version 2), we will see better and more performant handling of this use-case.
Financial regulation
Many financial and highly regulated industries want a way to look back and even restore tables to specific moments in time. Apache Iceberg snapshot and time-travel features can help analysts and auditors to easily look back in time and analyze the data with the simplicity of SQL.
Reproducibility for ML Ops
By allowing the retrieval of a previous table state, Iceberg provides ML Engineers the ability to retrain models with data in its original state, as well as to perform post-mortem analysis matching predictions to historical data. Through these historical feature stores, models can be re-evaluated, deficiencies identified, and newer and better models deployed.
Simplify data management
Most data practitioners spend a large portion of their time dealing with data management complexities. Let’s say new data sources are identified for your project, and as a result new attributes need to be introduced into your existing data model. Historically this could lead to long development cycles of recreating and reloading tables, especially if new partitions are introduced. However with Iceberg tables, and its metadata manifest files, can streamline these updates without incurring the additional costs.
- Schema evolution: Columns in the table can be changed in place (add, drop, rename, update or reorder) without affecting data availability. All the changes are tracked in the metadata files and Iceberg guarantees that schema changes are independent and free of side effects (like incorrect values).
- Partition evolution: A partition in an Iceberg table can be changed in the same way as an evolving schema. When evolving a partition the old data remains unchanged and new data will be written following the new partition spec. Iceberg uses hidden partitioning to automatically prune files that contain matching data from the older and newer partition spec via split planning.
- Granular partitioning: Traditionally the metastore and loading of partitions into memory during query planning was a major bottleneck preventing users from using granular partition schemes such as hours for fear that as their tables grew in size they would see poor performance. Iceberg overcomes these scalability challenges, by avoiding metastore and memory bottlenecks altogether, allowing users to unlock faster queries by using more granular partition schemes that best suit their application requirements.
This means the data practitioner can spend more time delivering business value and developing new data applications and less time dealing with data management – ie,
Evolve your data at the speed of the business and not the other way around.
The *Any*-house
We have seen a lot of trends in the Data Warehousing space, one of the newest being the Lakehouse, a reference to a converged architecture that combined data warehousing with the data lake. A key accelerant of such converged architectures at enterprises has been the decoupling of storage and processing engines. This however, has to be combined with multi-function analytic services from stream and real-time analytics to warehousing and machine learning. A single analytical workload, or combining of two is not sufficient. That’s why Iceberg within CDP is amorphic – engine agnostic, open data substrate that’s cloud scalable.
This allows the business to build “any” house without having to resort to proprietary storage formats to get the optimal performance, nor proprietary optimizations in one engine or service.
Iceberg is an analytics table layer that serves the data quickly, consistently and with all the features, without any gotchas.
Summary
Let’s quickly recap the 5 reasons why choosing CDP and Iceberg can future proof your next generation data architecture.
- Choose the engine of your choice and what works best for your use-cases from streaming, data curation, sql analytics, and machine learning.
- Flexible and open file formats.
- Get all the benefits of the upstream community including performance and not worry about vendor lock-in.
- Enterprise grade security and data governance – centralized data authorization to lineage and auditing.
- Open the door to new use-cases
Although not an exhaustive list, it does show why Apache Iceberg is perceived as the next generation table format for cloud native applications.
Ready to try Iceberg in CDP? Reach out to your Cloudera account representatives or if you are new to Cloudera take it for a spin through our 60-day trial.
And please join us on March 24 for an Iceberg deep dive with CDP at the next Future of Data meetup.
Editor's Choice

