

In a previous blog post on CDW performance, we compared Azure HDInsight to CDW. In this blog post, we compare Cloudera Data Warehouse (CDW) on Cloudera Data Platform (CDP) using Apache Hive-LLAP to EMR 6.0 (also powered by Apache Hive-LLAP) on Amazon using the TPC-DS 2.9 benchmark. Amazon recently announced their latest EMR version 6.1.0 with support for ACID transactions. This benchmark is run on EMR version 6.0 as we couldn’t get queries to run successfully on version 6.1.0. More on this later in the blog.
Though both the services are powered by an identical version of open source Apache Hive-LLAP, the benchmark results clearly demonstrate CDW is better suited out of the box to provide the best possible performance using LLAP:
- CDW runs the TPC-DS benchmark test suite more than 3x faster than EMR – 3 hours vs 11 hours (see Figure 1).
- Queries on CDW run on an average 5x faster than on EMR providing an overall faster response time (see Figure 2).
- The benchmark ran with 100% success on CDW. EMR in contrast had issues running query72, running for over 10 hours.
You can find all the benchmark scripts to set up and run the TPC-DS on 10TB scale here. In addition, scripts and EMR cluster configuration used for the benchmark can be found here. CDW is an analytic offering for Cloudera Data Platform (CDP). You can easily set up CDP on Amazon using scripts here.
Benchmark Configuration
On CDW, when you provision a Virtual Warehouse against your Data Catalog (catalog of table and views), the platform provides fully tuned LLAP worker nodes ready to run your queries. There are no additional setup or configuration steps required to run the benchmark. Once the benchmark run has completed, the Virtual Warehouse automatically suspends itself when no further activity is detected. For the benchmark, we chose a “Small” Virtual Warehouse size of a 10 node cluster.
On EMR, we spun up 10 workers with the same node type as CDW for a like-for-like comparison with 100% of capacity dedicated to LLAP.
A TPC-DS 10TB dataset stored on S3 was generated in ACID ORC format for CDW and non-ACID ORC format for EMR 6.0.

Cloudera Data Warehouse vs EMR
For the benchmark, we performed two runs of each query and selected the run with the lowest runtime. Doing multiple runs of the same query allowed us to measure performance with data cached on the SSD from the previous run. Total runtime was then calculated by aggregating the runtimes of all 98 queries.
As shown below in Figure 1, CDW outperformed EMR over 3x in the overall runtime with CDW finishing the benchmark in about 3 hours (11,386 seconds) vs EMR’s 11 hours (41,273 seconds).
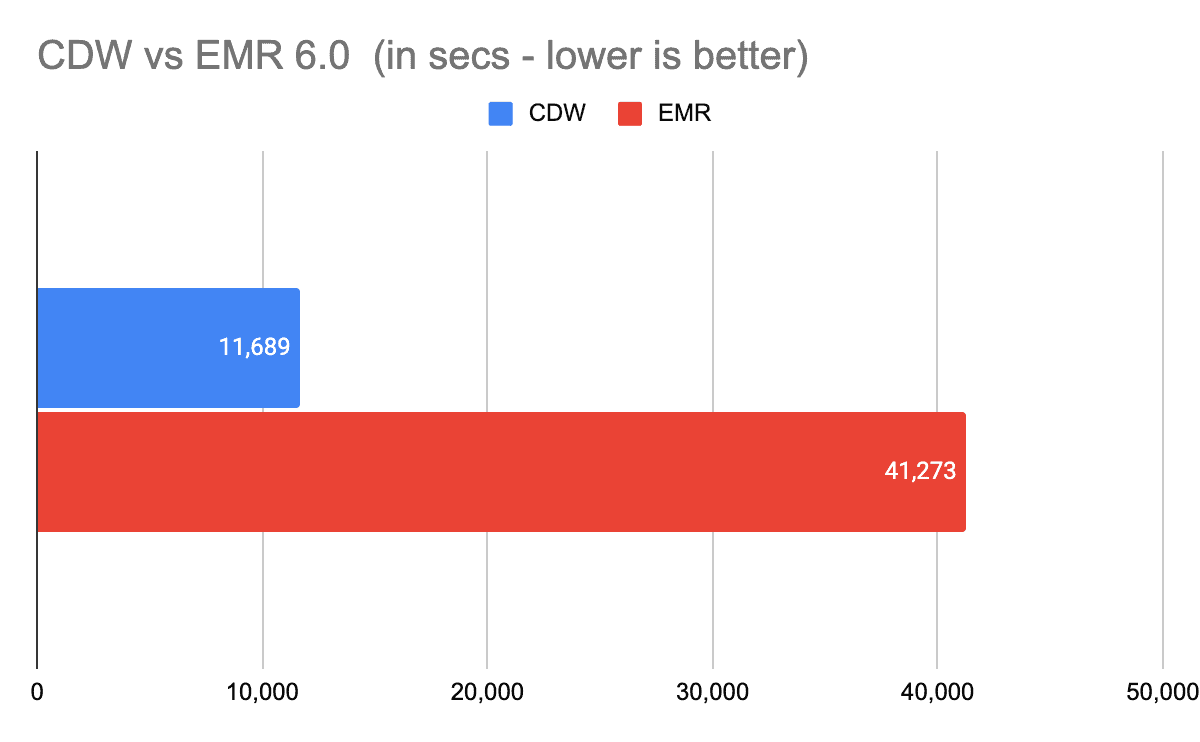
Figure 1 – Overall Runtime Comparison
The difference in performance is not limited to a small set of queries. We saw query performance improvements in CDW ranging from 2x to 160x in more than 60% of the benchmark, with the average speed up of 7.8x per query.
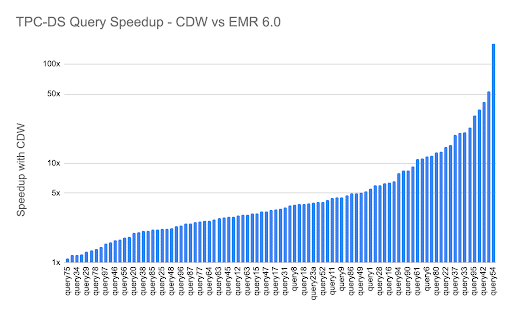
Figure 2 – TPC-DS per query speedup
Issues with EMR 6.1.0
We originally planned to run the benchmark with EMR 6.1.0 as it supports ACID ORC format. However, we couldn’t get any query with table joins to run successfully due to serialization exception in bigTableByteColumnVectorColumns (org.apache.hadoop.hive.ql.exec.vector.mapjoin.VectorMapJoinInnerBigOnlyLongOperator).
The way to work around this issue is to disable vectorization, but the performance degradation is so significant with this setting that we had to abandon the benchmark run with this version.
Conclusion
Using the latest and most well-tuned Hive engine in the market, CDW is built and backed by the pioneer contributors to Apache Hive – LLAP projects and packages Cloudera’s complete knowledge and experience in tuning its platform for performance –right out of the box. Rather than having to invest substantial time and effort to tune analytics for performance, organizations can get straight to what matters most: driving insight and value from their data.
In addition to better performance, CDW also provides a SaaS like experience to seamlessly manage your data lifecycle needs. Running on highly optimized Kubernetes engines, CDW can quickly and automatically scale up and down based on actual query workload, thereby providing optimum utilization of cloud (public as well as private) resources and budget. Finally, CDW is offered in CDP along with other data lifecycle services – Data Engineering, Machine Learning and Data Hub. CDP ensures end-to-end security, governance, and metadata management consistently across all the services through its versatile Shared Data Experience (SDX) module.
Learn more about Cloudera Data Warehouse on CDP.
Editor's Choice

