

At the end of May, we released the second version of Cloudera SQL Stream Builder (SSB) as part of Cloudera Streaming Analytics (CSA). Among other features, the 1.4 version of CSA surfaced the expressivity of Flink SQL in SQL Stream Builder via adding DDL and Catalog support, and it greatly improved the integration with other Cloudera Data Platform components, for example via enabling stream enrichment from Hive and Kudu.
Since then, we have added a RESTful API as a first class citizen to SSB, doubled down on Flink SQL for defining all aspects of SQL jobs, and upgraded to Apache Flink 1.13. Now we are releasing a new version of our product that takes the user experience, technical capabilities, and production readiness to the next level.
Feature Highlights
- Flink SQL scripts
- Templates for generating sinks for queries
- RESTful API for programmatic job submission
- Change Data Capture support
- Java UDF support
Flink SQL scripts
We have enabled writing fully fledged SQL scripts in the main editor window on the Compose tab of Streaming SQL Console, including SET, DDL and DML statements with even multiple INSERT INTO statements in a single script. For example, the following snippet is executable:
SET execution.target=yarn-per-job; CREATE TABLE IF NOT EXISTS datagen_sample ( `col_int` INT, `col_ts` TIMESTAMP(3), WATERMARK FOR `col_ts` AS `col_ts` - INTERVAL '5' SECOND ) WITH ( 'connector' = 'datagen' ); CREATE TABLE IF NOT EXISTS blackhole_sample ( `col_int` INT, `col_ts` TIMESTAMP(3) ) WITH ( 'connector' = 'blackhole' ); INSERT INTO blackhole_sample SELECT * FROM datagen_sample;
As a result of this change, we have removed the option to add Flink DDL tables using the wizard on the Tables tab, and we encourage users to define them like the above example instead.
When executing multiple INSERT INTO statements in a single job, SSB attaches the sampling to the last statement. Additionally, SET statements can be used to configure any Flink configuration parameters. The currently set values are displayed on the Session tab.
Sink templates
We have added the Templates functionality to generate a sink table matching the schema inferred from the user’s query.
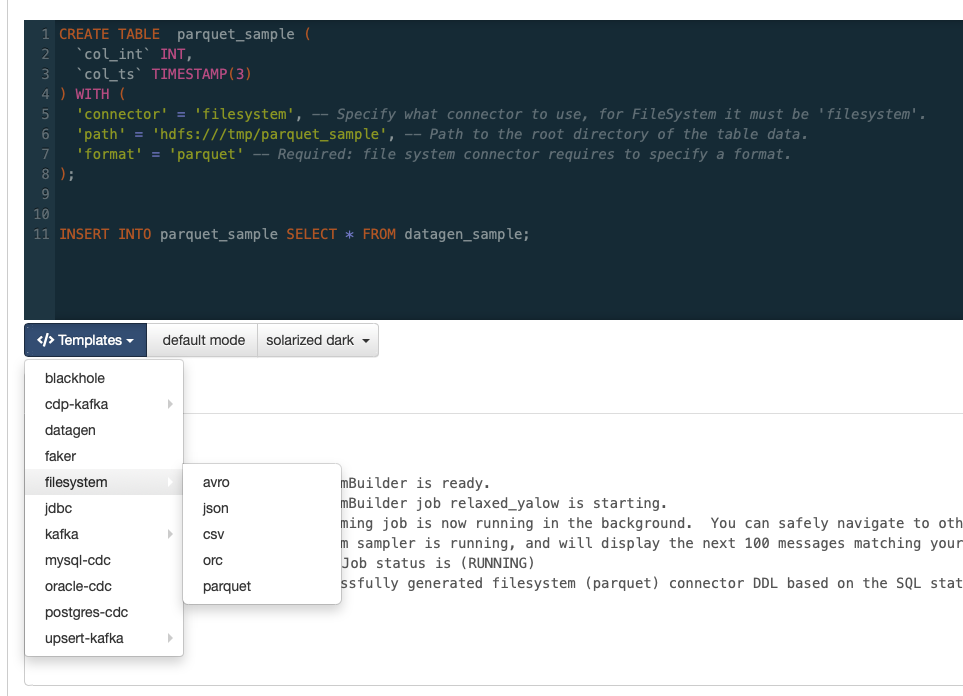
When the templates are called with an empty editor, they provide a default schema. Otherwise, they infer it from the script available or selected in the editor. Now that this functionality is available, we have removed the ability to create schemaless or “Dynamic schema” tables as they did not conform to our table model.
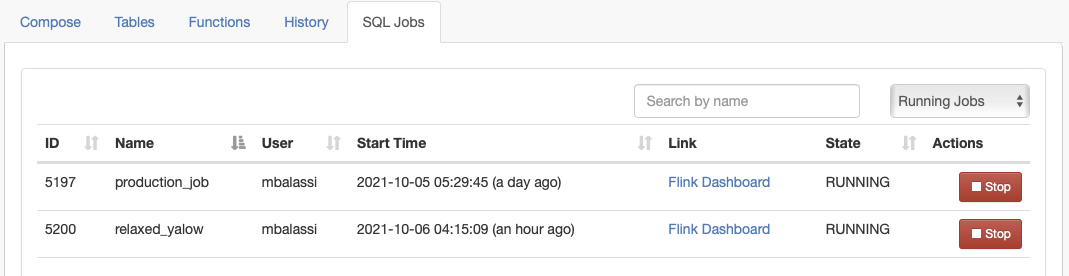
RESTful API for SQL Stream Builder
In this release, we are introducing a RESTful API for all SQL Stream Builder operations. This enables programmatic access and automation of SQL Stream Builder jobs. The accompanying Swagger page is available as part of our documentation. For example the following call creates a self-contained new job:
curl --location --request POST '<streaming_sql_engine_host>:<streaming_sql_engine_port>/api/v1/ssb/sql/execute' \ --header 'Content-Type: application/json' \ --data-raw '{ "sql": "CREATE TABLE IF NOT EXISTS datagen_sample (col_int INT, col_ts TIMESTAMP(3), WATERMARK FOR col_ts AS col_ts - INTERVAL '\''5'\'' SECOND) WITH ('\''connector'\'' = '\''datagen'\'');\nSELECT * FROM datagen_sample;", "job_parameters": { "job_name": "production_job" } }'
The GUI internally uses the same endpoints, so the results can be also observed from the SQL Jobs tab. The default port for the Streaming SQL Engine is 18121.
Change Data Capture
We are adding support for Change Data Capture streams from relational databases based on a community project that wraps Flink as a runtime around logic imported from Debezium. This approach does not require changes to the replicated database tables, instead it hooks into the replication stream of the database.
For example the following table can be defined to connect to an Oracle RDBMS CDC stream:
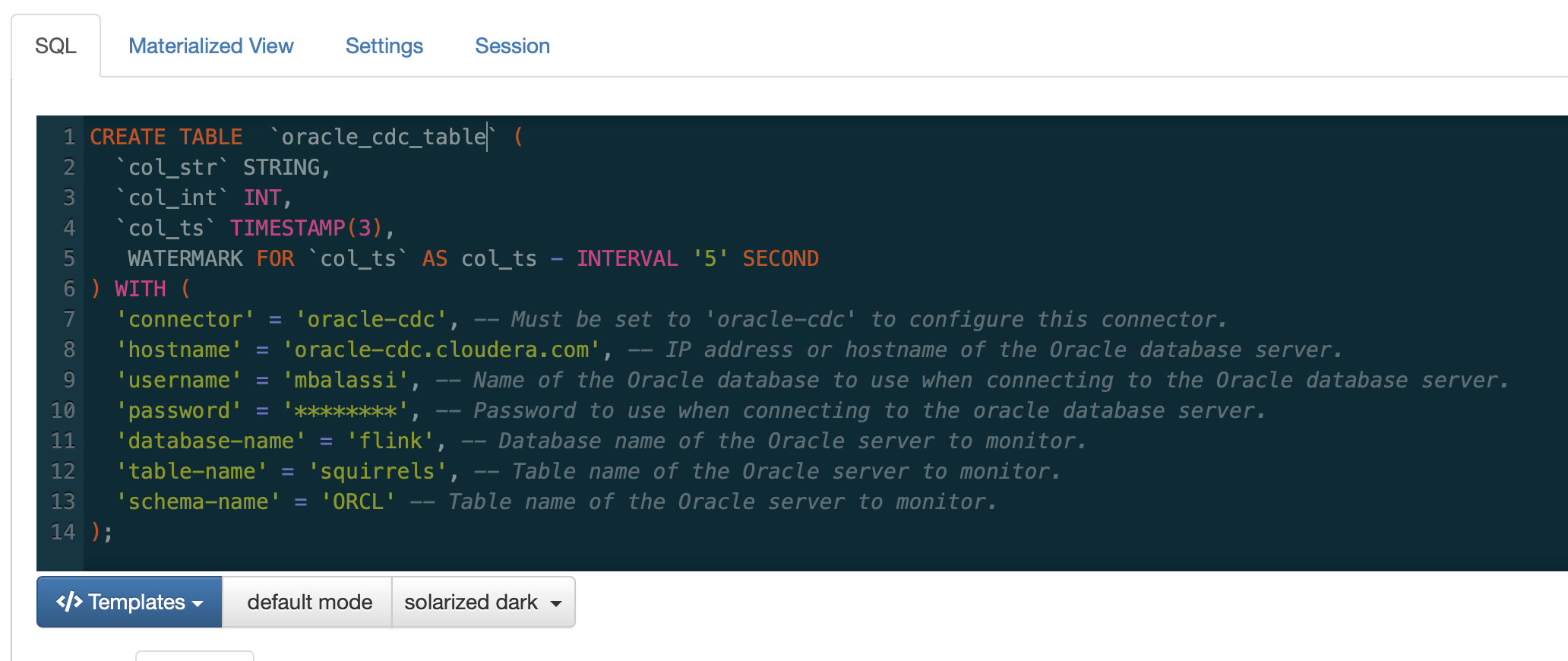
Supported CDC connector implementations are available from the Templates feature.
Java User Defined Functions
SQL Stream Builder already had support for Javascript UDFs defined on the GUI. Now we have added the option to use Flink SQL Java UDFs too via adding them to the classpath.
For example, the following simple increment function implemented as a Flink Java Function:
package com.cloudera; import org.apache.flink.table.functions.ScalarFunction; public class FlinkTestJavaUDF extends ScalarFunction { public Integer eval(Integer i) { return i + 1; } }
Can be added and then used the following way on the aforementioned datagen_sample table:
CREATE FUNCTION incrementer AS 'com.cloudera.FlinkTestJavaUDF' LANGUAGE java; SELECT col_int, incrementer(col_int) as inc FROM datagen_sample;
Summary
In Cloudera Streaming Analytics 1.5, we have significantly improved the SQL Stream Builder functionality and user experience. We have doubled down on Flink SQL via exposing SQL scripts and Java UDFs, added new functionality with the Change Data Capture connectors, and enabled programmatic access with a first class citizen REST API.
Take the next step and learn more about Cloudera Streaming Analytics.
Editor's Choice

