

At the end of March, we released the first version of Cloudera SQL Stream Builder as part of Cloudera Streaming Analytics 1.3. It enabled users to easily write, run and manage real-time SQL queries on streams from Apache Kafka with an exceptionally smooth user experience.
Since then, we have been working hard to expose the full power of Apache Flink SQL-API and the existing Data Warehousing tools in CDP to combine it into a state-of-the-art real-time analytics platform. Now we are releasing a new version of our product that takes the user experience, technical capabilities, and platform integration to the next level.
Feature Highlights
- Flink SQL DDL and Catalog support
- Improved Kafka and Schema Registry integration
- Stream enrichment from Hive & Kudu
- Improved Table Management
- Custom connector support
Flink SQL DDL Support
In addition to quickly connecting to Kafka data sources, users can now use Flink DDL statements to create Tables and Views with full flexibility.
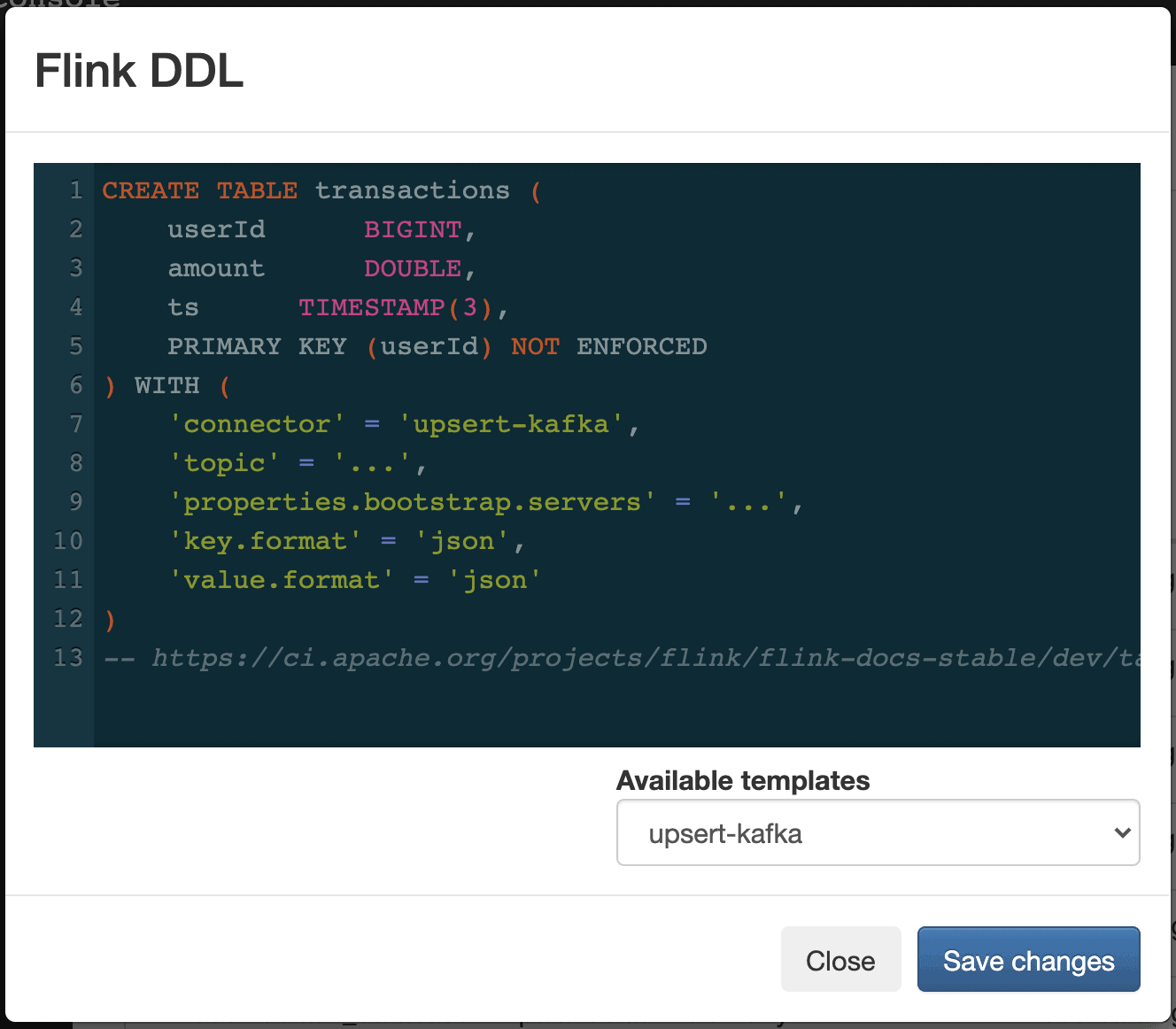
SQL Stream Builder comes with a large set of built-in connectors, such as Kafka, Hive, Kudu, Schema Registry, JDBC and Filesystem connectors, that can be further extended by the users when necessary.
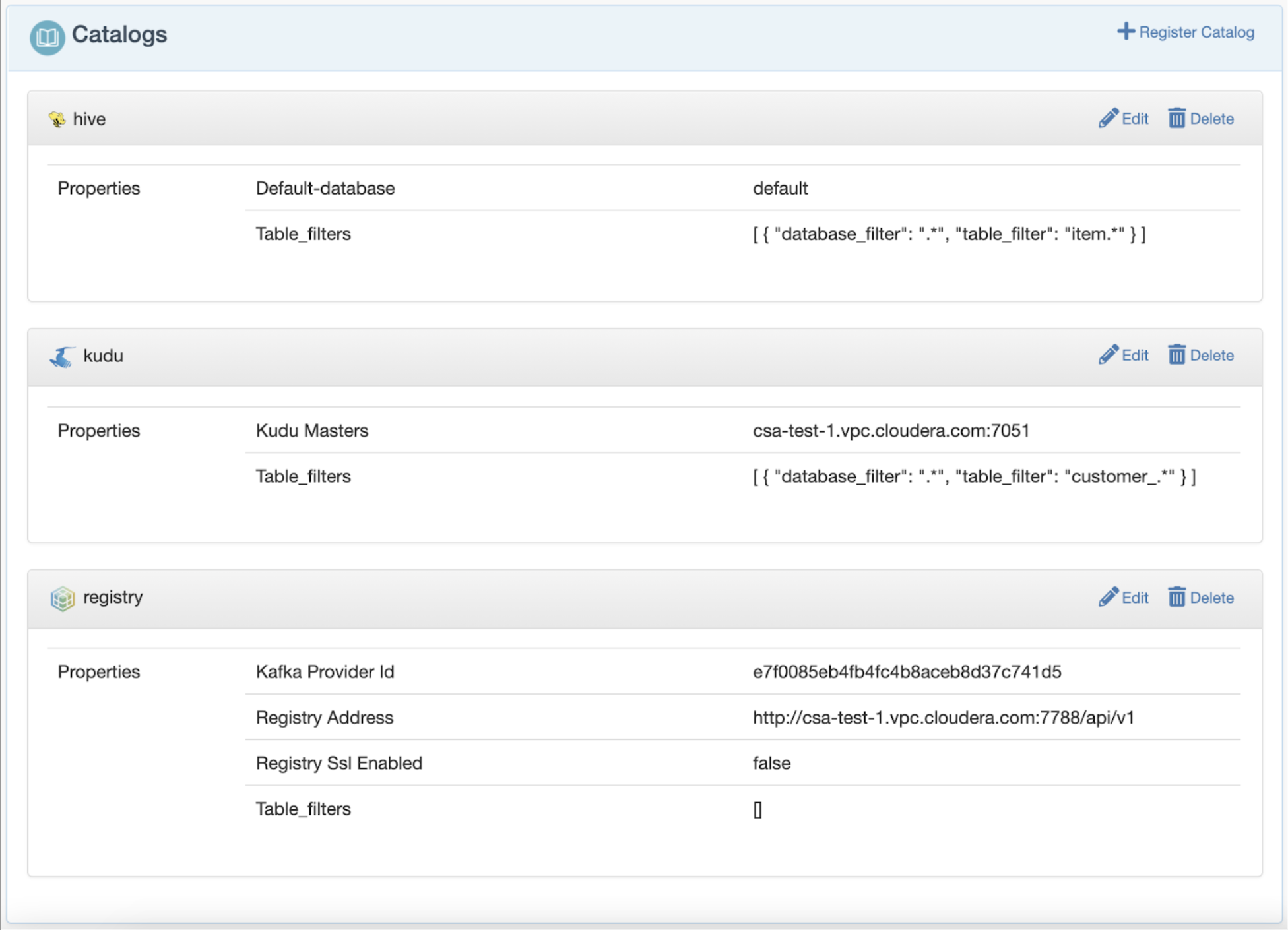
Catalog Integrations
Flink SQL catalogs are now supported directly on the Streaming SQL Console allowing easy access to data stored in other systems. SQL Stream Builder comes bundled with 3 catalogs: Hive, Kudu and Schema Registry.
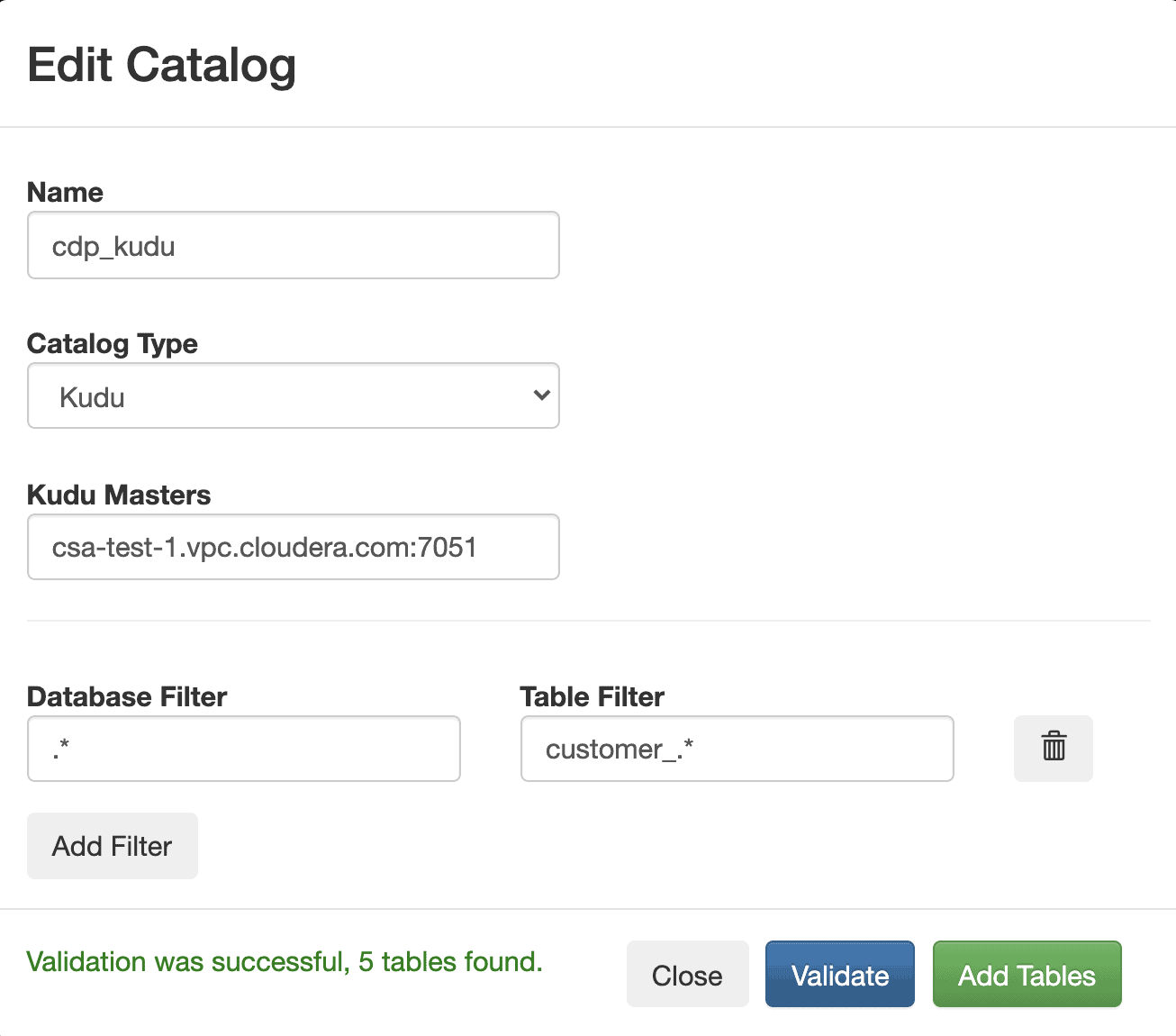
By registering a catalog in the Streaming SQL Console, users get instant access to all the tables and data without having to add them manually. This step significantly speeds up query development and data exploration.
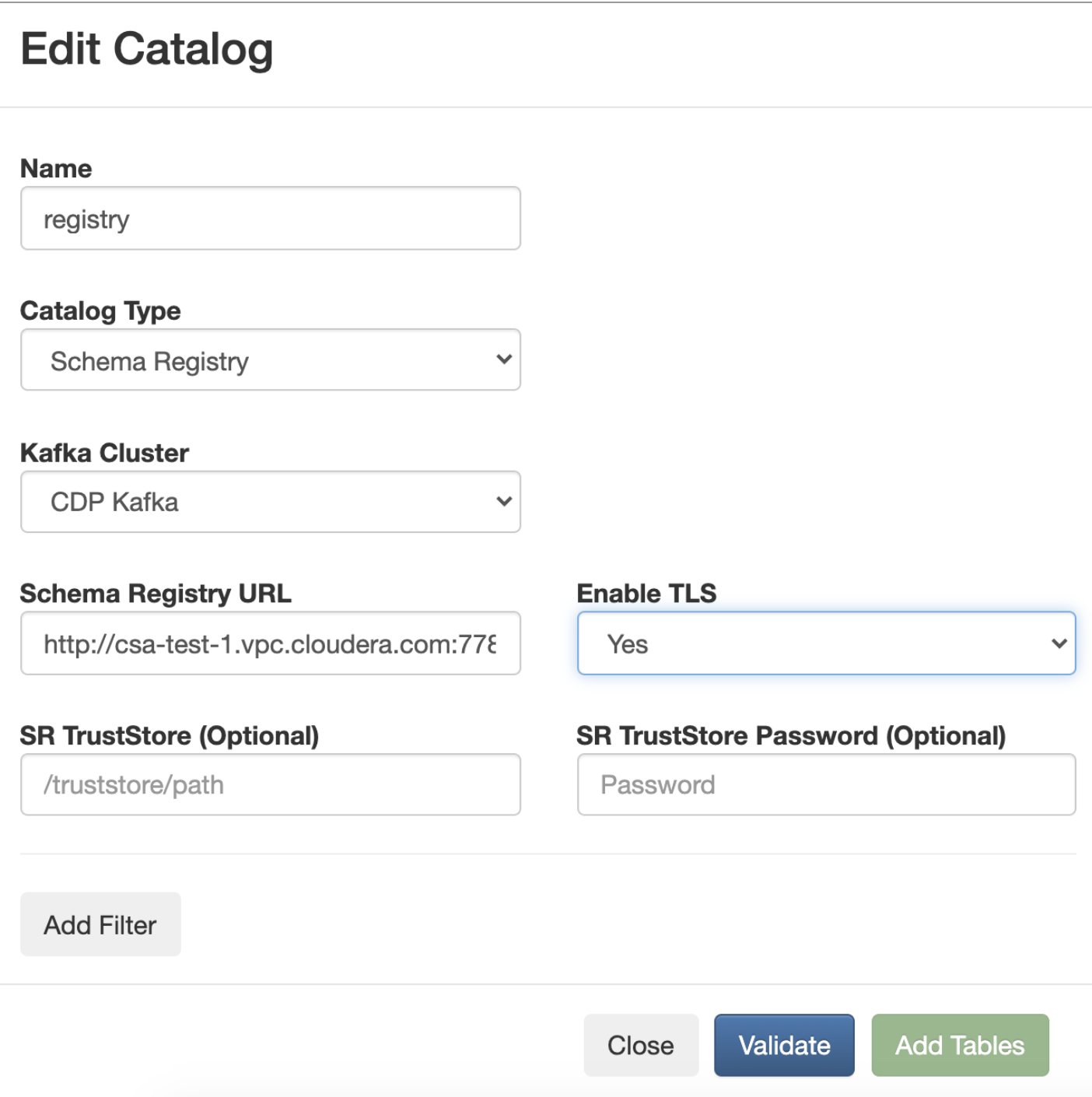
Improved Kafka and Schema Registry integration
We have further streamlined the integration with Kafka and Schema Registry. Schema Registry tables will now be created automatically through the catalog integration so users don’t need to add them one-by-one.
For JSON and Avro Kafka tables that do not use Schema Registry, we have made two important improvements:
- Timestamp and event time management is now exposed in the Kafka source creation pop-up, allowing for fine control
- We also improved the JavaScript input transformations and integrated it with the schema detection functionality
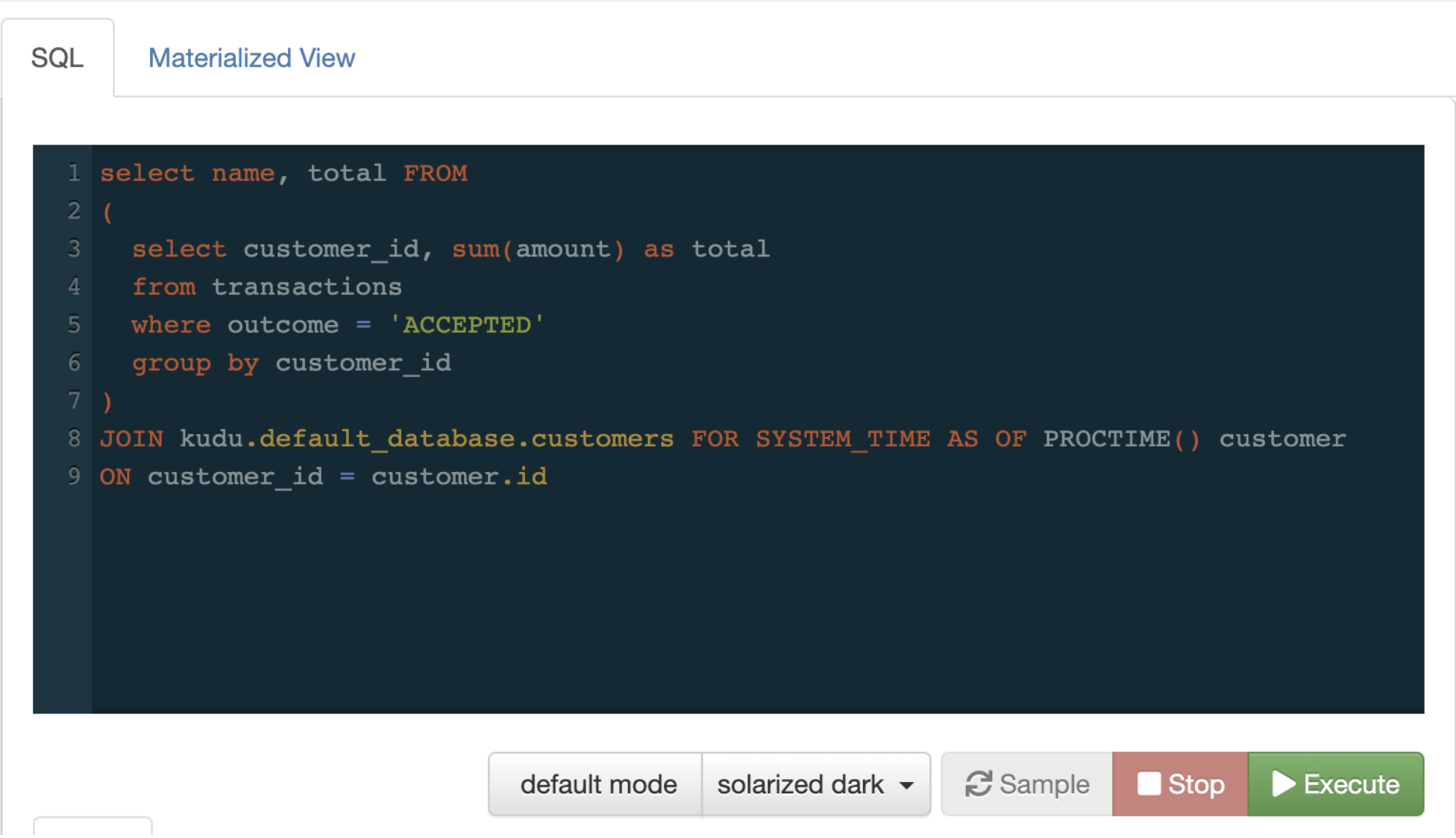
Stream Enrichment from Hive & Kudu
With Cloudera Streaming Analytics 1.4, you get access to all the data stored in your Hive & Kudu systems which opens up key use cases for data enrichment.
You can use Flink’s powerful lookup join syntax to join your incoming streams with static data from Hive, Kudu or databases through the JDBC connector.
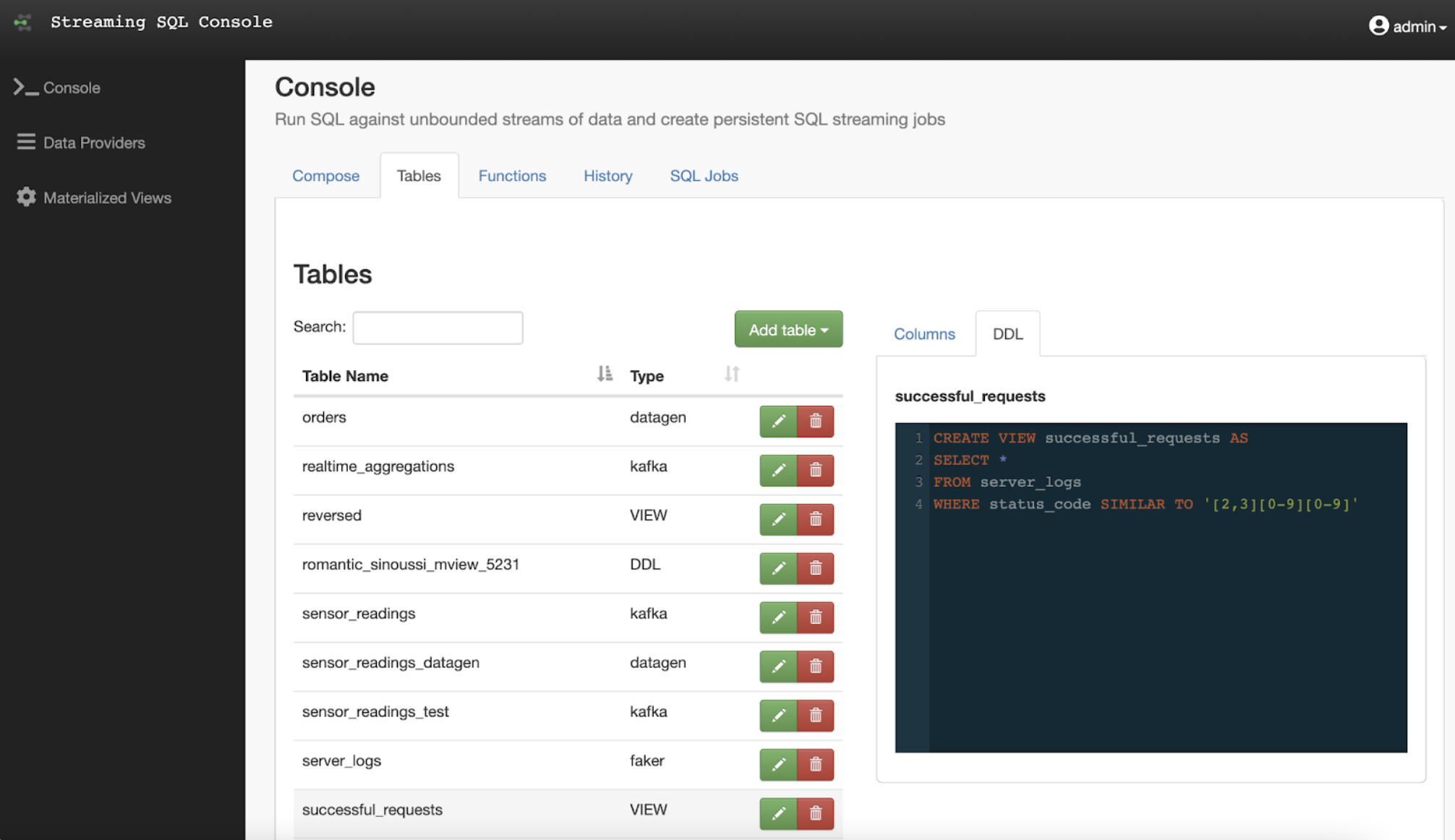
Improved Table Management
The data source data sink management tabs have now been reworked into a general table management page to see all the different tables and views accessible in our system.
With the added search and description functionality, we made table exploration much easier.
Summary
In Cloudera Streaming Analytics 1.4, we have significantly improved the SQL Stream Builder functionality and user experience. We believe that enabling use cases where our end users can easily join Kafka streams and slowly changing sources like Hive and Kudu is a game changer and unlocks the true power of running Streaming SQL queries via Flink on the Cloudera Data Platform.
Take the next step and learn more about Cloudera Streaming Analytics.
Editor's Choice

