

What is a dead letter queue (DLQ)?
Cloudera SQL Stream builder gives non-technical users the power of a unified stream processing engine so they can integrate, aggregate, query, and analyze both streaming and batch data sources in a single SQL interface. This allows business users to define events of interest for which they need to continuously monitor and respond quickly. A dead letter queue (DLQ) can be used if there are deserialization errors when events are consumed from a Kafka topic. DLQ is useful to see if there are any failures due to invalid input in the source Kafka topic and makes it possible to record and debug problems related to invalid inputs.
Creating a DLQ
We will use the example schema definition provided by SSB to demonstrate this feature. The schema has two properties: “name” and “temp” (for temperature) to capture sensor data in JSON format. The first step is to create two Kafka topics: “sensor_data” and “sensor_data_dlq” which can be done the following way:
kafka-topics.sh --bootstrap-server <bootstrap-server> --create --topic sensor_data --replication-factor 1 --partitions 1 kafka-topics --bootstrap-server <bootstrap-server> --create --topic sensor_data_dlq --replication-factor 1 --partitions 1
Once the Kafka topics are created, we can set up a Kafka source in SSB. SSB provides a convenient way to work with Kafka as we can do the whole setup using the UI. In Project Explorer, open the Data Sources folder. Right clicking on “Kafka” brings up the context menu where we can open the creation modal window.
We need to provide a unique name for this new data source, the list of brokers, and the protocol in use:
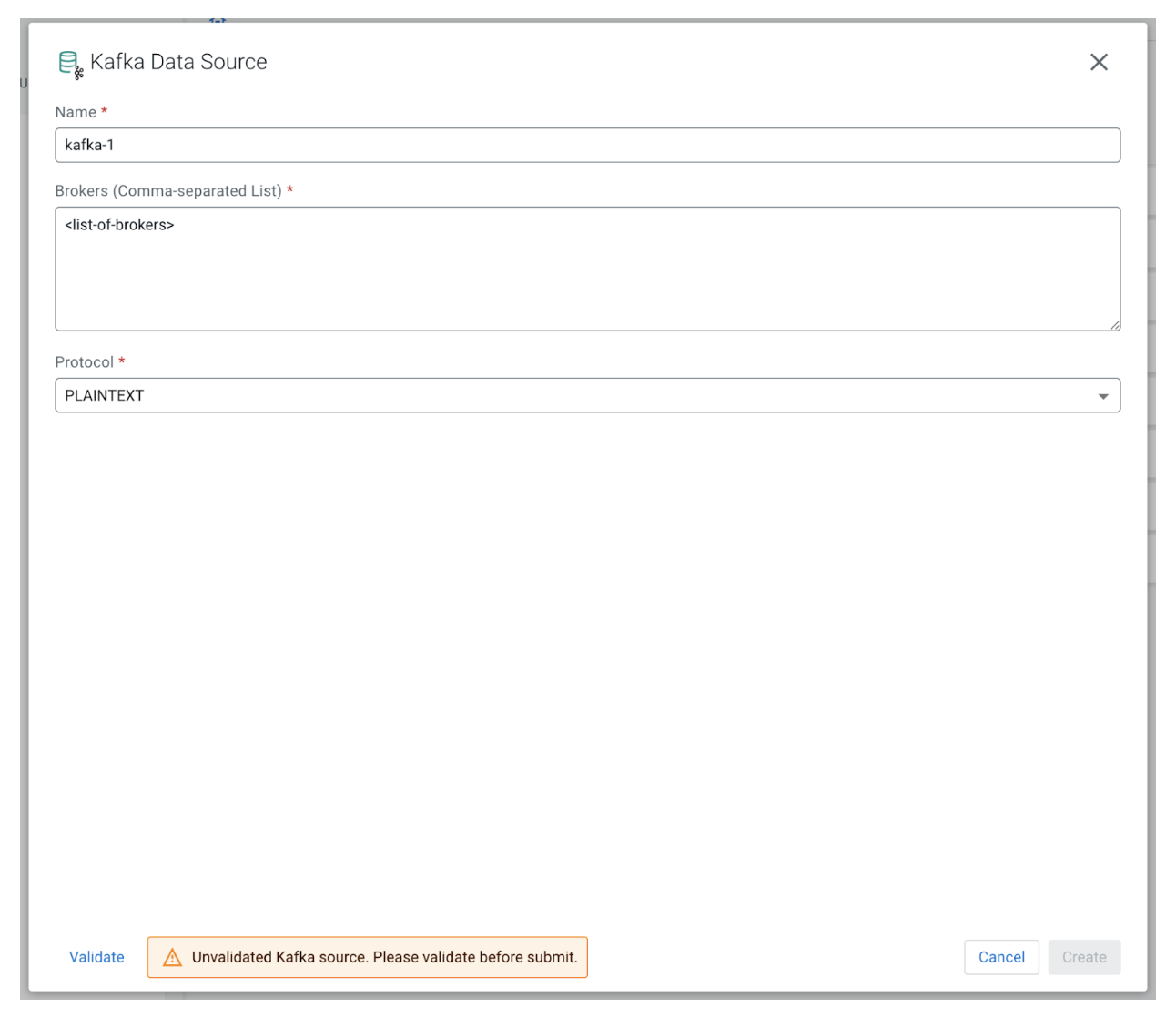
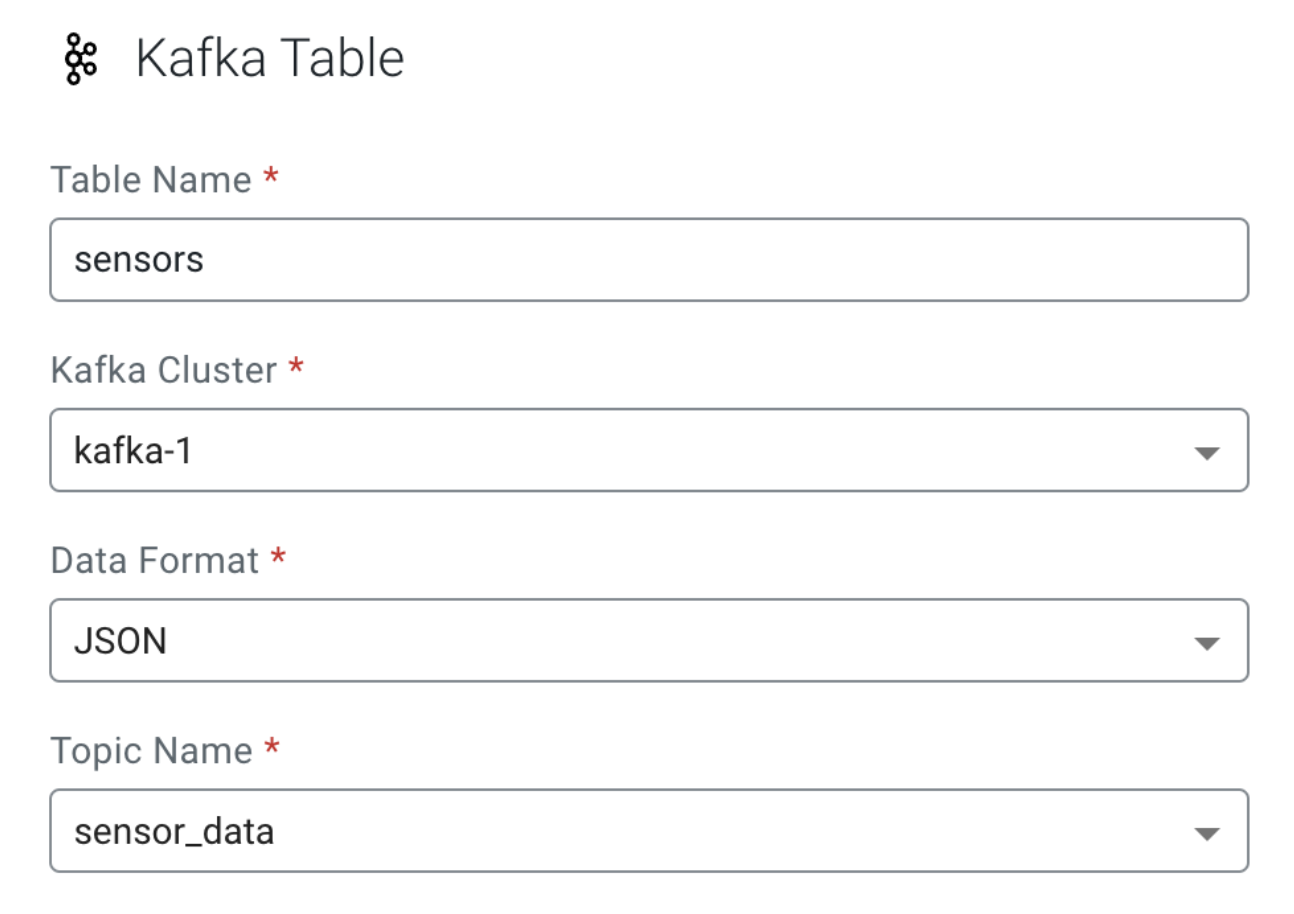
After the new Kafka source is successfully registered, the next step is to create a new virtual table. We can do that from the Project Explorer by right clicking “Virtual Tables” and choosing “New Kafka Table” from the context menu. Let’s fill out the form with the following values:
- Table Name: Any unique name; we will user “sensors” in this example
- Kafka Cluster: Choose the Kafka source registered in the previous step
- Data Format: JSON
- Topic Name: “sensor_data” which we created earlier
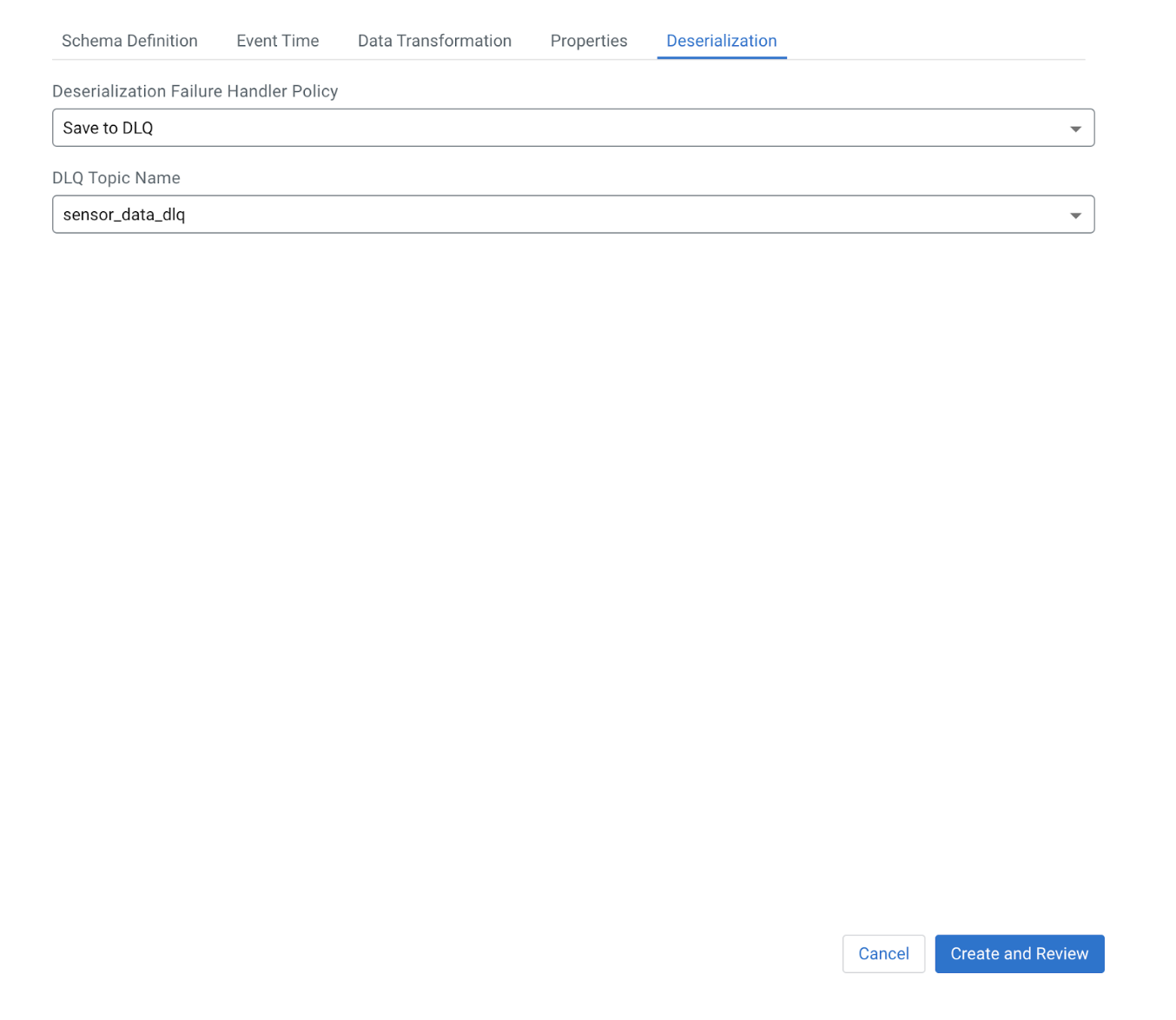
We can see under the “Schema Definition” tab that the example provided has the two fields, “name” and “temp,” as discussed earlier. The last step is to set up the DLQ functionality, which we can do by going to the “Deserialization” tab. The “Deserialization Failure Handler Policy” drop-down has the following options:
- “Fail”: Let the job crash and then auto-restart setting dictates what happens next
- “Ignore”: Ignores the message that could not be deserialized, moves to the next
- “Ignore and Log”: Same as ignore but logs each time it encounters a deserialization failure
- “Save to DLQ”: Sends the invalid message to the specified Kafka topic
Let’s select “Save to DLQ” and choose the previously created “sensor_data_dlq” topic from the “DLQ Topic Name” drop-down. We can click “Create and Review” to create the new virtual table.
Testing the DLQ
First, create a new SSB job from the Project Explorer. We can run the following SQL query to consume the data from the Kafka topic:
SELECT * from sensors;
In the next step we will use the console producer and consumer command line tools to interact with Kafka. Let’s send a valid input to the “sensor_data” topic and check if it is consumed by our running job.
kafka-console-producer.sh --broker-list <broker> --topic sensor_data >{"name":"sensor-1", "temp": 32}
Checking back on the SSB UI, we can see that the new message has been processed:
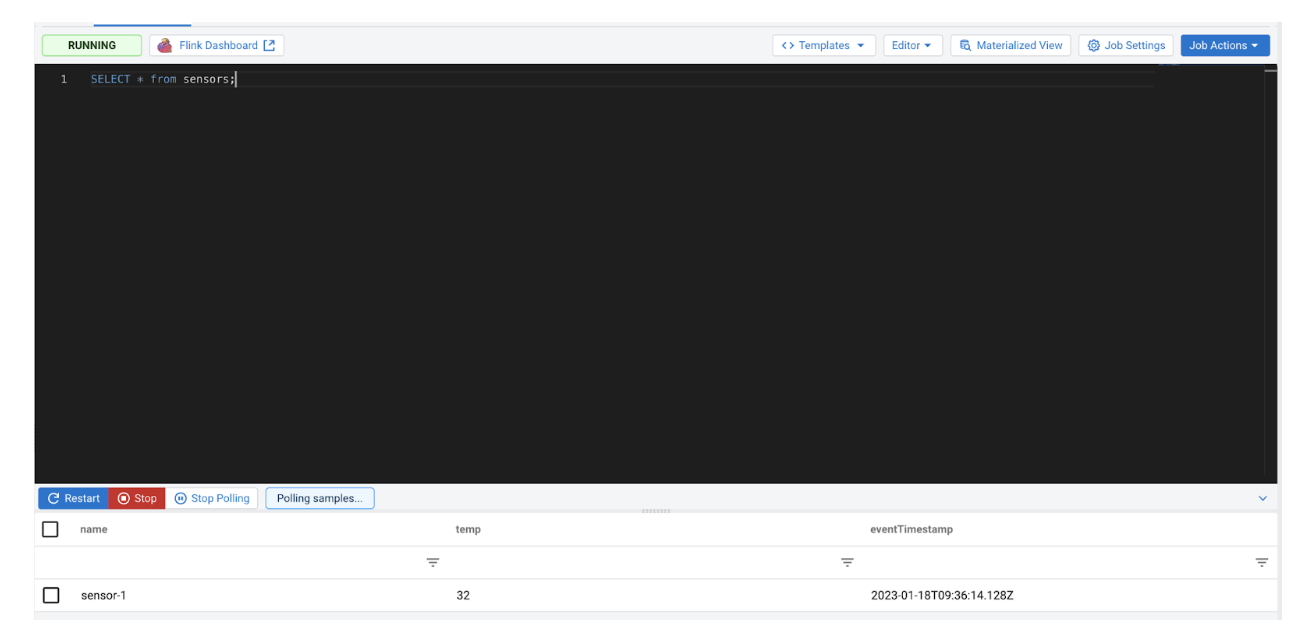
Now, send an invalid input to the source Kafka topic:
kafka-console-producer.sh --broker-list <broker> --topic sensor_data >invalid data
We won’t see any new messages in SSB as the invalid input cannot be deserialized. Let’s check on the DLQ topic we set up earlier to see if the invalid message was captured:
kafka-console-consumer.sh --bootstrap-server <server> --topic sensor_data_dlq --from-beginning invalid data
The invalid input is there which verifies that the DLQ functionality is working correctly, allowing us to further investigate any deserialization error.
Conclusion
In this blog, we covered the capabilities of the DLQ feature in Flink and SSB. This feature is very useful to gracefully handle a failure in a data pipeline due to invalid data. Using this capability, it is very easy and quick to find out if there are any bad records in the pipeline and where the root cause of those bad records are.
Try it out yourself!
Anybody can try out SSB using the Stream Processing Community Edition (CSP-CE). CE makes developing stream processors easy, as it can be done right from your desktop or any other development node. Analysts, data scientists, and developers can now evaluate new features, develop SQL-based stream processors locally using SQL Stream Builder powered by Flink, and develop Kafka Consumers/Producers and Kafka Connect Connectors, all locally before moving to production in CDP.
Editor's Choice

