

The Paycheck Protection Program (PPP) is implemented by the US federal government to provide a direct incentive for businesses to keep their employees on the payroll, particularly during the Covid-19 pandemic. PPP assists qualified businesses retain their workforce as well as help pay for related business expenses. Data from the US Treasury website show which companies received PPP loans and how many jobs were retained. The US Treasury approved approximately one million PPP loans across the US.
Analysis of this data presents three challenges. First, the size of the data is significant. The amount of time to pull, curate, transform, retrieve and report on that data is time intensive. Second, the data set is likely to evolve, which will consume additional development time and resources. Finally, in a multi-stage process like this, there’s a chance things will break. Having the ability to quickly determine errors or bottlenecks will help consistently meet SLAs.
This blog illustrates how Cloudera Data Engineering (CDE), using Apache Spark, can be used to produce reports based on the PPP data while addressing each of the challenges outlined above.
Objective
A mock scenario for the Texas Legislative Budget Board (LBB) is set up below to help a data engineer manage and analyze the PPP data. The primary objective for this data engineer is to provide the LBB with two end reports:
- Report 1: Breakdown of all cities in Texas that retained jobs
- Report 2: Breakdown of company type that retained jobs
Cloudera Data Engineering (CDE)
This is where Cloudera Data Engineering (CDE) running Apache Spark can help. CDE is one of the services in Cloudera Data Platform (CDP) that allows data engineers to create, manage, and schedule Apache Spark jobs, while providing useful tools to monitor job performance, access log files, and orchestrate workflows via Apache Airflow. Apache Spark is a data processing framework that is capable of quickly running large-scale data processing.
The US Treasury provides two different data sets, one for approved loans greater than $150k and one for approved loans under $150k. To produce the two end reports for the LBB, these steps were followed (see Fig. 1).
- The first step was to load the two separate data sets into an S3 bucket.
- A Spark job was created for each data set to pull and filter data from the S3 bucket.
- These two Spark jobs transformed and loaded the clean data into a Hive data warehouse for retrieval.
- A third Spark job was created to process the data from the Hive data warehouse to create the two reports.
Once the job runs were complete, CDE provided a graphical representation of the various stages within each Spark job (see Fig. 2). This allowed the data engineer to easily see what parts of the job were potentially taking the most time, letting them to easily refine and improve their code to best meet customer SLAs.
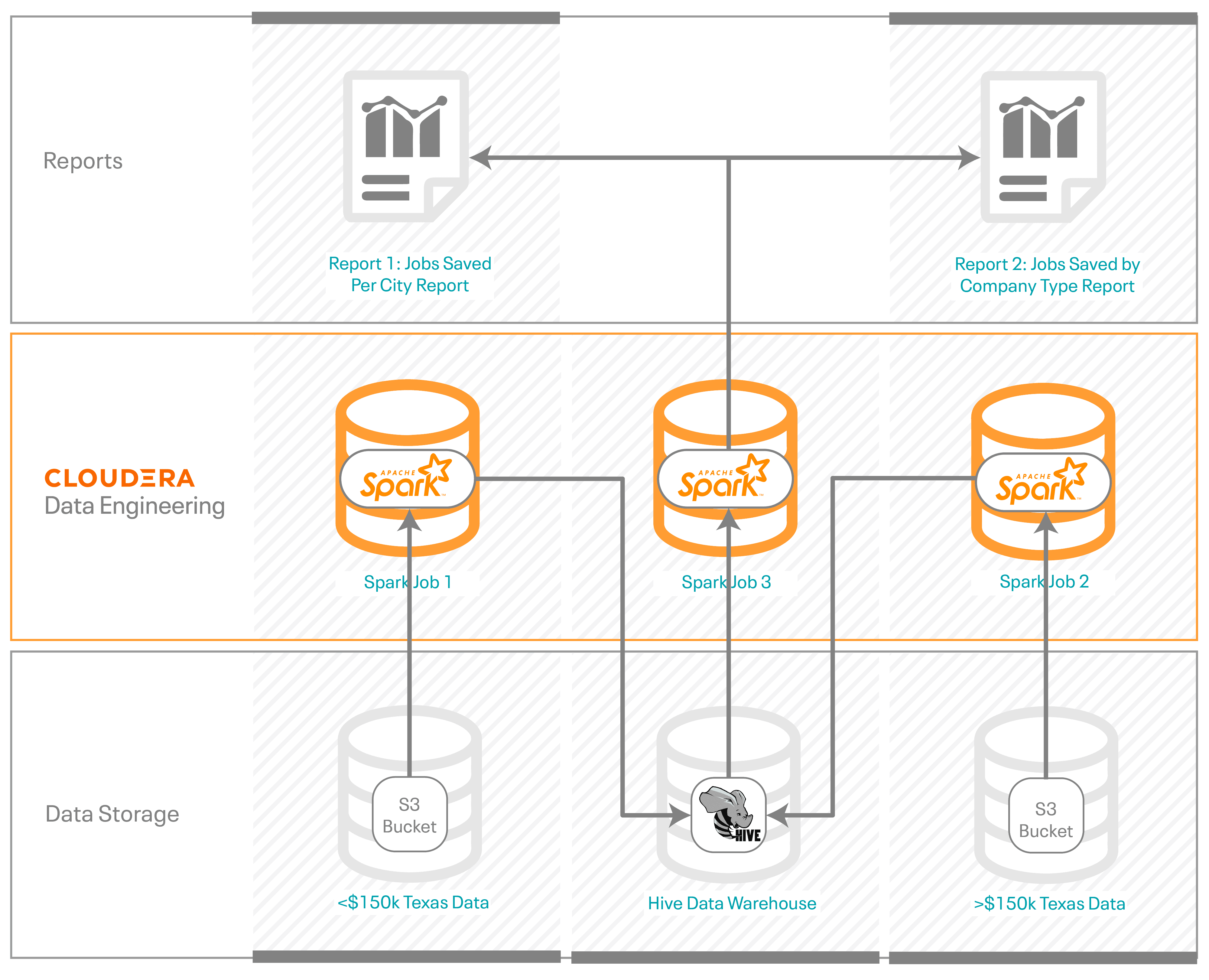
Fig. 1: Data journey to produce the two end reports.
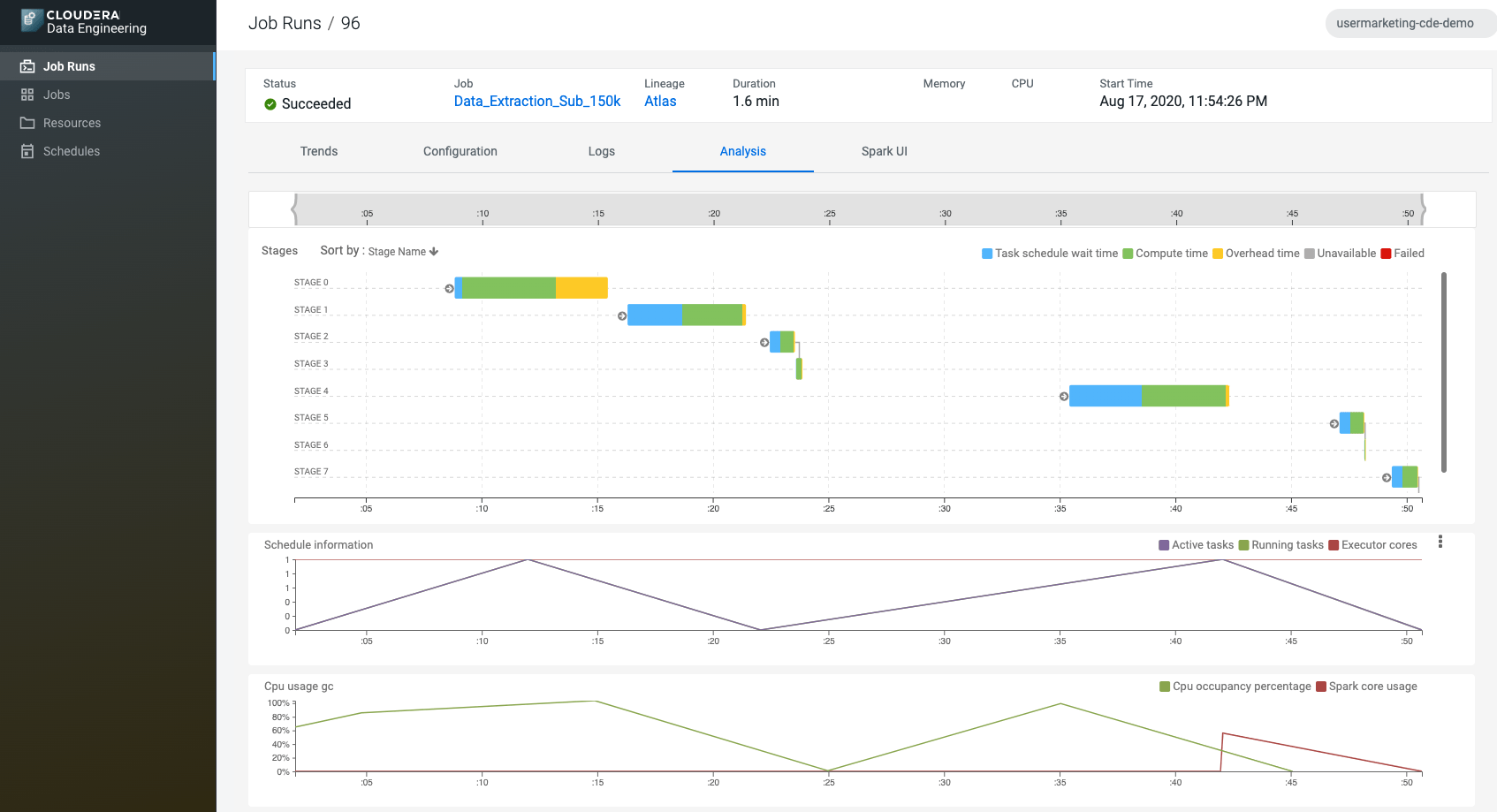
Fig. 2: CDE graphical representation of various Spark stages.
Results
The primary objective to produce the two end reports from the record of a million approved applicants were met. The graphical summary of the first report (see Fig. 3) shows a top 10 sample of the number of jobs retained per city in Texas, and the second report (see Fig. 4) shows a top 5 sample of the number of jobs retained by company type. With these reports, the Texas Legislative Budget Board, for example, can infer that cities with the least amount of job retention per capita may need resources to lessen any economic impact.
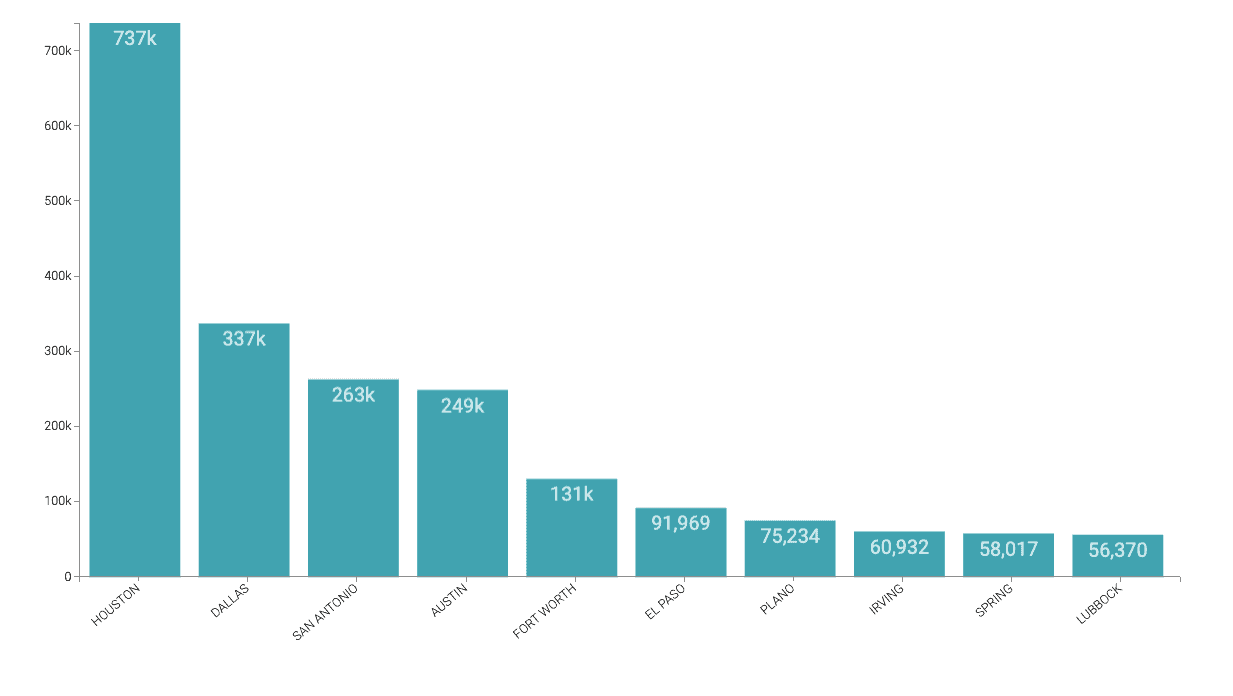
Fig. 3: Top 10 cities that retained the most jobs, State of Texas, 2020

Fig. 4: Top 5 company types that retained the most jobs, State of Texas, 2020
Next Steps
To see all this in action, please click on links below to a few different sources showcasing the process that was created.
- Video – If you’d like to see and hear how this was built, see video at the link.
- Tutorials – If you’d like to do this at your own pace, see a detailed walkthrough with screenshots and line by line instructions of how to set this up and execute.
- Meetup – If you want to talk directly with experts from Cloudera, please join a virtual meetup to see a live stream presentation. There will be time for direct Q&A at the end.
- CDP Users Page – To learn about other CDP resources built for users, including additional video, tutorials, blogs and events, click on the link.
Editor's Choice

