


In this installment, we provide insight into how the Fair Scheduler works, and why it works the way it does.
In Part 3 of this series, you got a quick introduction to Fair Scheduler, one of the scheduler choices in Apache Hadoop YARN (and the one recommended by Cloudera). In Part 4, we will cover most of the queue properties, some examples of their use, as well as their limitations.
Queue Properties
By default, the Fair Scheduler uses a single default queue. Creating additional queues and setting the appropriate properties allows for more fine-grained control of how applications are run on the cluster.
FairShare
FairShare is simply an amount of YARN cluster resources. We will use the notation <memory: 100GB, vcores: 25> to indicate a FairShare of 100GB and 25 vcores.
Share Weights
<weight>Numerical Value 0.0 or greater</weight>
Notes:
- The weight determines the amount of resources a queue deserves in relation to its siblings. For example, given the following:
- A YARN cluster of size 1000GB and 200 vcores
- Queue X with weight 0.25
- All other queues with a combined weight of 0.75
- Queue X will have FairShare of <memory: 250GB, vcores: 50>
- The calculated FairShare is enforced for a queue if the queue or one of its child queues has at least one active application. This limit will be satisfied quickly if there is an equivalent amount of free resources on the cluster. Otherwise, the resources will be made available as tasks in other queues finish.
- The weight is relative to the cluster, so the FairShare changes as the cluster resources change.
- This is the recommended method of performing queue resource allocation.
Resource Constraints
There are two types of resource constraints:
<minResources>20000 mb, 10 vcores</minResources> <maxResources>2000000 mb, 1000 vcores</maxResources>
Notes:
- The
minResourceslimit is a soft limit. It is enforced as long as the queue total resource requirement is greater than or equal to theminResourcesrequirement and it will get at least the amount specified as long as the following holds true:- The resources are available or can be preempted from other queues.
- The sum of all
minResourcesis not larger than the cluster’s total resources.
- The
maxResourceslimit is a hard limit, meaning it is constantly enforced. The total resources used by the queue with this property plus any of its child and descendant queues must obey the property. - Using
minResources/maxResourcesis not recommended. There are several disadvantages:- Values are static values, so they need updating if the cluster size changes.
maxResourceslimits the utilization of the cluster, as a queue can’t take up any free resources on the cluster beyond the configuredmaxResources.- If the
minResourcesof a queue is greater than its FairShare, it might adversely affect the FairShare of other queues. - In the past, one specified
minResourceswhen using preemption to get a chunk of resources sooner. This is no longer necessary as FairShare-based preemption has been improved significantly. We will discuss this subject in more detail later.
Limiting Applications
There are two ways to limit applications on the queue:
<maxRunningApps>10</maxRunningApps> <maxAMShare>0.3</maxAMShare>
Notes:
- The
maxRunningAppslimit is a hard limit. The total resources used by the queue plus any child and descendant queues must obey the property. - The
maxAMSharelimit is a hard limit. This fraction represents the percentage of the queue’s resources that is allowed to be allocated for ApplicationMasters.- The
maxAMShareis handy to set on very small clusters running a large number of applications. - The default value is 0.5. This default ensures that half the resources are available to run non-AM containers.
- The
Users and Administrators
These properties are used to limit who can submit to the queue and who can administer applications (i.e. kill) on the queue.
<aclSubmitApps>user1,user2,user3,... group1,group2,...</aclSubmitApps> <aclAdministerApps>userA,userB,userC,... groupA,groupB,...</aclAdministerApps>
Note: If yarn.acl.enable is set to true in yarn-site.xml, then the yarn.admin.acl property will also be considered a list of valid administrators in addition to the aclAdministerApps queue property.
Queue Placement Policy
Once you configure the queues, queue placement policies serve the following purpose:
- As applications are submitted to the cluster, assign each application to the appropriate queue.
- Define what types of queues are allowed to be created “on the fly”.
Queue-placement policy tells Fair Scheduler where to place applications in queues. The queue-placement policy:
<queuePlacementPolicy> <Rule #1> <Rule #2> <Rule #3> . . </queuePlacementPolicy>
will match against “Rule #1” and if that fails, match against “Rule #2” and so on until a rule matches. There are a predefined set of rules from which to choose and their behavior can be modeled as a flowchart. The last rule must be a terminal rule, which is either the default rule or the reject rule.
If no queue-placement policy is set, then FairScheduler will use a default rule based on the properties yarn.scheduler.fair.user-as-default-queue and yarn.scheduler.fair.allow-undeclared-pools properties in the yarn-site.xml file.
Special: Creating queues on the fly using the “create” attribute
All the queue-placement policy rules allow for an XML attribute called create which can be set to “true” or “false”. For example:
<rule name=”specified” create=”false”>
If the create attribute is true, then the rule is allowed to create the queue by the name determined by the particular rule if it doesn’t already exist. If the create attribute is false, the rule is not allowed to create the queue and queue placement will move on to the next rule.
Queue Placement Rules
This section gives an example for each type of queue-placement policy available and provides a flowchart for how the scheduler determines which application goes to which queue (or whether the application creates a new queue).
Rule: specified
- Summary: Specify exactly to which queue the application goes.
- Example rule in XML:
<rule name="specified"/> - Example Hadoop command specifying queue:
hadoop jar mymr.jar app1 -Dmapreduce.job.queuename="root.myqueue" - Flowchart:
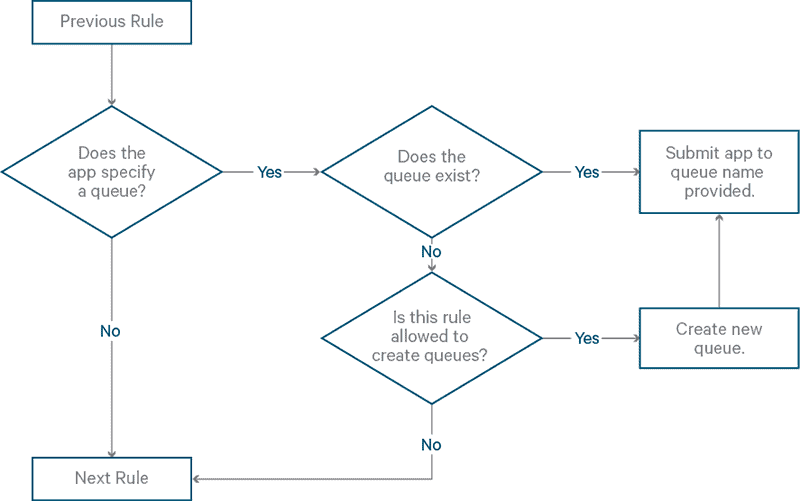
Rule: user
- Summary: Assign the application to a queue named after the user who submitted the application. For example, if Fred is the user launching the YARN application, then the queue in the flowchart will be
root.fred. - Example rule in XML:
<rule name="user"/> - Flowchart:

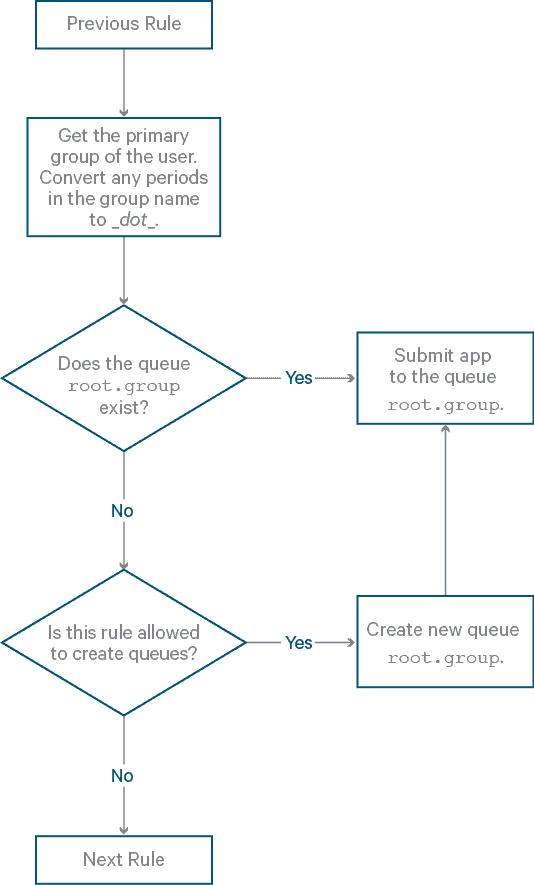
Rule: primaryGroup
- Summary: Assign the application to a queue named after the primary group (usually the first group) to which the user belongs. For example, if the user launching the application belongs in the Marketing group, then the queue in the flowchart will be
root.marketing. - Example rule in XML:
<rule name="primaryGroup"/> - Flowchart:
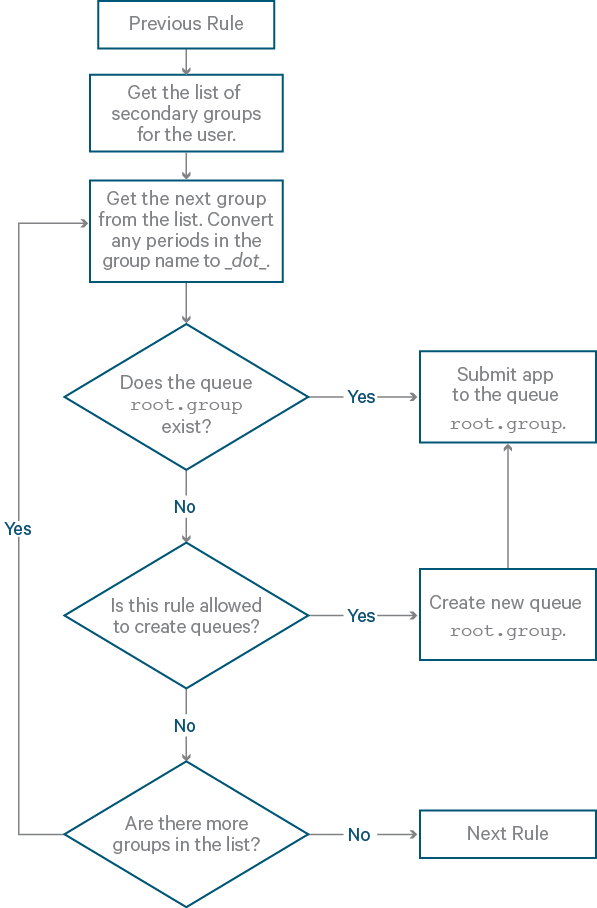
Rule: secondaryGroupExistingQueue
- Summary: Assign the application to a queue named after the first valid secondary group (in other words, not the primary group) to which the user belongs. For example, if the user belongs to the secondary groups
market_eu,market_auto,market_germany, then the queue in the flowchart will iterate and look for the queuesroot.market_eu,root.market_auto, androot.market_germany. - Example rule in xml:
<rule name="secondaryGroupExistingQueue"/> - Flowchart:
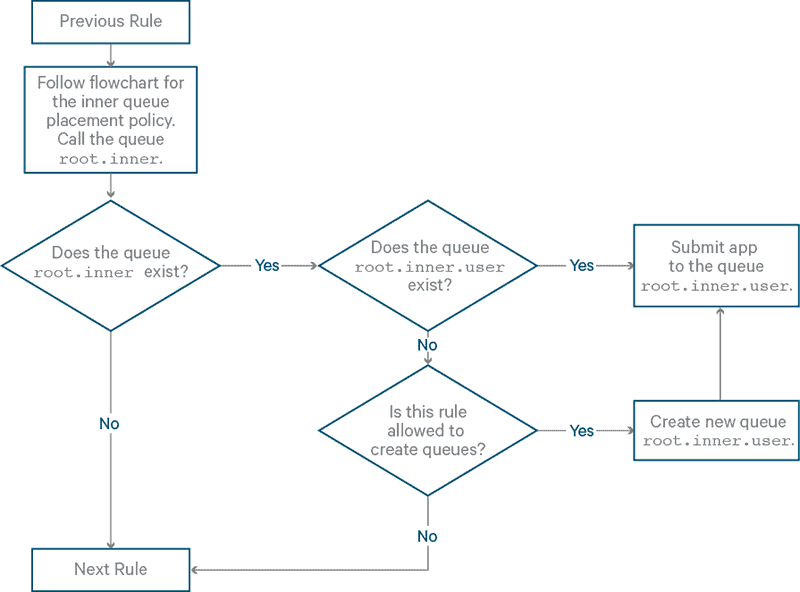
Rule: nestedUserQueue
- Summary: Create a
userqueue below some other queue other thanroot. The “other queue” is determined by the rule enclosed by thenestedUserQueuerule. - Template:
<rule name="nestedUserQueue" create=”true”>
<!-- Put one of the other Queue Placement Policies here. -->
</rule>
- Example rule in XML:
<rule name="nestedUserQueue" create=”true”>
<rule name="primaryGroup" create="false" />
</rule>
- Note: This rule creates
userqueues, but under a queue other than therootqueue. The inner queue-placement policy is evaluated first, and then theuserqueue is created underneath. Note that if thenestedUserQueuerule does not set the propertycreate="true"then applications can only be submitted if a particularuserqueue already exists. - Flowchart:
Rule: default
Summary: Define a default queue.
Example rule in XML: <rule name="default" queue="default" />
Flowchart:
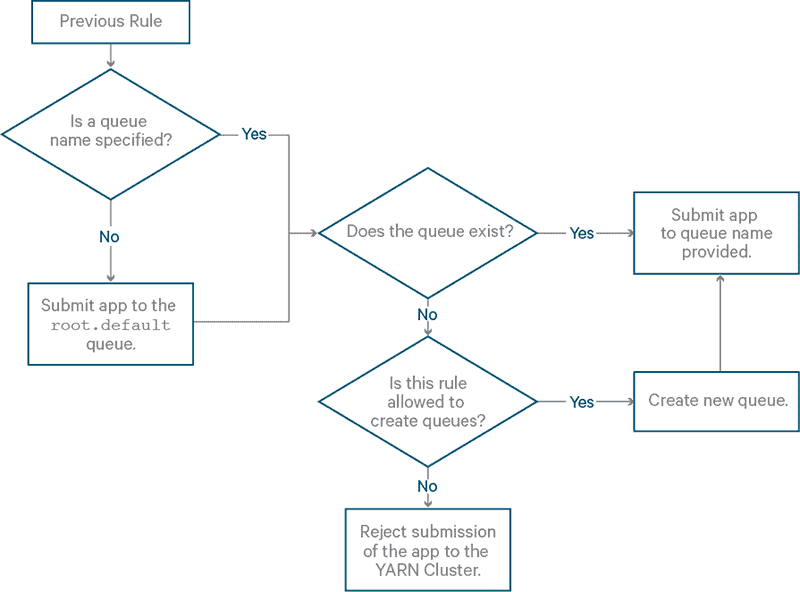
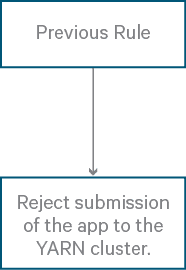
Rule: reject
- Summary: Reject the application submission. This is typically used as a last rule if you wish to avoid ending up with some default behavior for application submission.
- Example rule in XML:
<rule name="reject"/> - Note: If a standard
hadoop jarcommand is rejected by this rule, the error messagejava.io.IOException: Failed to run job : Application rejected by queue placement policywill occur. - Flowchart:
Sidebar: Application Scheduling StatusAs discussed in Part 1 of this series, an application comprises one or more tasks, with each task running in a container. For purposes of this blog post, an application can be in one of four states:
|
Example: A Cluster with Running Applications
Assume that we have a YARN cluster with total resources <memory: 800GB, vcores 200> with two queues: root.busy (weight=1.0) and root.sometimes_busy (weight 3.0). There are generally four scenarios of interest:
- Scenario A: The busy queue is full with applications, and
sometimes_busyqueue has a handful of running applications (say 10%, i.e. <memory: 80GB, vcores: 20>). Soon, a large number of applications are added to thesometimes_busyqueue in a relatively short time window. All the new applications insometimes_busywill be pending, and will become active as containers finish up in thebusyqueue. If the tasks in thebusyqueue are fairly short-lived, then the applications in thesometimes_busyqueue will not wait long to get containers assigned. However, if the tasks in thebusyqueue take a long time to finish, the new applications in thesometimes_busyqueue will stay pending for a long time. In either case, as the applications in thesometimes_busyqueue become active, many of the running applications in thebusyqueue will take much longer to finish.
- Scenario B: Both the
busyandsometimes_busyqueues are full or close-to-full of active and/or pending applications. In this situation, the cluster will remain at full utilization. Each queue will use its fair share, with the sum of all applications in thebusyqueue using 25% of the cluster’s resources and the sum of all applications in thesometimes_busyqueue using the remaining 75%.
So, how can Scenario A be avoided?
One solution would be to set maxResources on the busy queue. Suppose the maxResources attribute is set on the busy queue to the equivalent of 25% of the cluster. Since maxResources is a hard limit, the applications in the busy queue will be limited to the 25% total at all times. So, in the case where 100% of the cluster could be used, the cluster utilization is actually closer to 35% (10% for the sometimes_busy queue and 25% for the busy queue).
Scenario A will improve noticeably since there are free resources on the cluster that can only go to applications in the sometimes_busy queue, but the average cluster utilization would likely be low.
More FairShare Definitions
- Steady FairShare: the theoretical FairShare value for a queue. This value is calculated based on the cluster size and the weights of the queues in the cluster.
- Instantaneous FairShare: the calculated FairShare value by the scheduler for each queue in the cluster. This value differs from Steady FairShare in two ways:
– Empty queues are not assigned any resources.
– This value is equal to the Steady FairShare when all queues are at or beyond capacity. - Allocation: equal to the sum of the resources used by all running applications in the queue.
Going forward, we will refer to Instantaneous FairShare as simply “FairShare.”
The Case for Preemption
Given these new definitions, the previous scenarios can be phrased as follows:
- Scenario A
- The
sometimes_busyqueue has an Allocations value of <memory: 80GB, vcores: 20> and a FairShare value of <memory: 600GB, vcores: 150>. - The
busyqueue has an Allocations value of <memory: 720GB, vcores: 180> and a FairShare value of <memory: 200GB, vcores: 50>.
- The
- Scenario B
- Both queues have their Instantaneous FairShare equal to their Steady FairShare.
In Scenario A, you can see the imbalance that both queues have between their Allocations and their FairShare. The balance is slowly returned as containers are release from the busy queue and allocated to the sometimes_busy queue.
By turning on preemption, the Fair Scheduler can kill containers in the busy queue and allocate them more quickly to the sometimes_busy queue.
Configuring Fair Scheduler for Preemption
To turn on preemption, set this property in yarn-site.xml:
<property>yarn.scheduler.fair.preemption</property> <value>true</value>
Then, in your FairScheduler allocation file, preemption can be configured on a queue via fairSharePreemptionThreshold and fairSharePreemptionTimeout as shown in the example below. The fairSharePreemptionTimeout is the number of seconds the queue is under fairSharePreemptionThreshold before it will try to preempt containers to take resources from other queues.
<allocations>
<queue name="busy">
<weight>1.0</weight>
</queue>
<queue name="sometimes_busy">
<weight>3.0</weight>
<fairSharePreemptionThreshold>0.50</fairSharePreemptionThreshold>
<fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>
</queue>
<queuePlacementPolicy>
<rule name="specified" />
<rule name=”reject” />
</queuePlacementPolicy>
</allocations>
Recall that the FairShare of the sometimes_busy queue is <memory: 600GB, vcores: 150>. The two new properties tell FairScheduler that the sometimes_busy queue will wait 60 seconds before beginning preemption. If in that time, it has not received 50% of its FairShare in resources, FairScheduler can begin killing containers in the busy queue and allocating them to the sometimes_busy queue.
A couple things of note:
- The value of
fairSharePreemptionThresholdshould be greater than 0.0 (setting to 0.0 would be like turning off preemption) and not greater than 1.0 (since 1.0 will return the full FairShare to the queue needing resources). - Preemption in this configuration will kill containers in the
busyqueue and allocate them to thesometimes_busyqueue.- Preemption in the reverse direction will not happen since there are no preemption properties set on the
busyqueue. - Preemption will not kill containers from application A in the
sometimes_busyqueue and allocate them to application B in thesometimes_busyqueue.
- Preemption in the reverse direction will not happen since there are no preemption properties set on the
- If
fairSharePreemptionTimeoutis not set for a given queue or one of its ancestor queues, and the defaultFairSharePreemptionTimeout is not set, pre-emption by this queue will never occur, even if pre-emption is enabled.
(Note: We will not cover minResources and minSharePreemptionTimeout on a queue. FairShare preemption is currently recommended.)
Extra Reading
To get more information about Fair Scheduler, take a look at the online documentation (Apache Hadoop and CDH versions are available).
Conclusion
- There are many properties that can be set on a queue. This includes limiting resources, limiting applications, setting users or administrators, and setting scheduling policy.
- A queue configuration file should also include a queue placement policy. The queue placement policy defines how applications are assigned to queues.
- Applications that are running in a queue can keep applications in a different queue in a pending or starving state. Configuring preemption in Fair Scheduler allows this imbalance to be adjusted more quickly.
Next Time
Part 5 will provide specific examples, such as job prioritization, and how to use queues and their properties to handle the situation.
Ray Chiang is a Software Engineer at Cloudera.
Dennis Dawson is a Technical Writer at Cloudera.
Editor's Choice

