

CDP Operational Database (COD) is a real-time auto-scaling operational database powered by Apache HBase and Apache Phoenix. It is one of the main data services that run on Cloudera Data Platform (CDP) Public Cloud. You can access COD from your CDP console.
The cost savings of cloud-based object stores are well understood in the industry. Applications whose latency and performance requirements can be met by using an object store for the persistence layer benefit significantly with lower cost of operations in the cloud. While it is possible to emulate a hierarchical file system view over object stores, the semantics compared to HDFS are very different. Overcoming these caveats must be addressed by the accessing layer of the software architecture (HBase, in this case). From dealing with different provider interfaces, to specific vendor technology constraints, Cloudera and the Apache HBase community have made significant efforts to integrate HBase and object stores, but one particular characteristic of the Amazon S3 object store has been a big problem for HBase: the lack of atomic renames. The store file tracking project in HBase addresses the missing atomic renames on S3 for HBase. This improves HBase latency and reduces I/O amplification on S3.
HBase on S3 review
HBase internal operations were originally implemented to create files in a temporary directory, then rename the files to the final directory in a commit operation. It was a simple and convenient way to separate being written or obsolete from ready-to-be-read files. In this context, non-atomic renames could cause not only client read inconsistencies, but even data loss. This was a non-issue on HDFS because HDFS provided atomic renames.
The first attempt to overcome this problem was the rollout of the HBOSS project in 2019. This approach built a distributed locking layer for the file system paths to prevent concurrent operations from accessing files undergoing modifications, such as a directory rename. We covered HBOSS in this previous blog post.
Unfortunately, when running the HBOSS solution against larger workloads and datasets spanning over thousands of regions and tens of terabytes, lock contentions induced by HBOSS would severely hamper cluster performance. To solve this, a broader redesign of HBase internal file writes was proposed in HBASE-26067, introducing a separate layer to handle the decision about where files should be created first and how to proceed at file write commit time. That was labeled the StoreFile Tracking feature. It allows pluggable implementations, and currently it provides the following built-in options:
- DEFAULT: As the name suggests, this is the default option and is used if not explicitly set. It works as the original design, using temporary directories and renaming files at commit time.
- FILE: The focus of this article, as this is the one to be used when deploying HBase with S3 with Cloudera Operational Database (COD). We’ll cover it in more detail in the remainder of this article.
- MIGRATION: An auxiliary implementation to be used while converting the existing tables containing data between the DEFAULT and FILE implementations.
User data in HBase
Before jumping into the inner details of the FILE StoreFile Tracking implementation, let us review HBase’s internal file structure and its operations involving user data file writing. User data in HBase is written to two different types of files: WAL and store files (store files are also mentioned as HFiles). WAL files are short lived, temporary files used for fault tolerance, reflecting the region server’s in-memory cache, the memstore. To achieve low-latency requirements for client writes, WAL files can be kept open for longer periods and data is persisted with fsync style calls. Store files (Hfiles), on the other hand, is where user data is ultimately saved to serve any future client reads, and given HBase’s distributed sharding strategy for storing information Hfiles are typically spread over the following directory structure:
/rootdir/data/namespace/table/region/cf
Each of these directories are mapped into region servers’ in-memory structures known as HStore, which is the most granular data shard in HBase. Most often, store files are created whenever region server memstore utilization reaches a given threshold, triggering a memstore flush. New store files are also created by compactions and bulk loading. Additionally, region split/merge operations and snapshot restore/clone operations create links or references to store files, which in the context of store file tracking require the same handling as store files.
HBase on cloud storage architecture overview
Since cloud object store implementations do not currently provide any operation similar to an fsync, HBase still requires that WAL files be placed on an HDFS cluster. However, because these are temporary, short-lived files, the required HDFS capacity in this case is much smaller than would be needed for deployments storing the whole HBase data in an HDFS cluster.
Store files are only read and modified by the region servers. This means higher write latency does not directly impact client write operations (Puts) performance. Store files are also where the whole of an HBase data set is persisted, which aligns well with the reduced costs of storage offered by the main cloud object store vendors.
In summary, an HBase deployment over object stores is basically a hybrid of a short HDFS for its WAL files, and the object store for the store files. The following diagram depicts an HBase over Amazon S3 deployment:
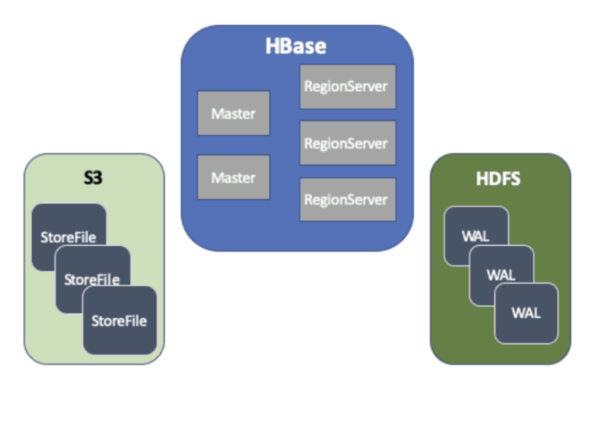
This limits the scope of the StoreFile Tracking redesign to components that directly deal with store files.
HStore writes high-level design
The HStore component mentioned above aggregates several additional structures related to store maintenance, including the StoreEngine, which isolates store file handling specific logic. This means that all operations touching store files would ultimately rely on the StoreEngine at some point. Prior to the HBASE-26067 redesign, all logic related to creating store files and how to differentiate between finalized files from files under writing and obsolete files was coded within the store layer. The following diagram is a high-level view of the main actors involved in store file manipulation prior to the StoreFile Tracking feature:
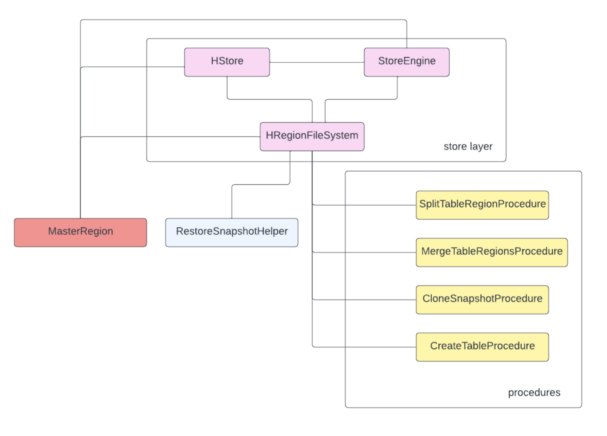
A sequence view of a memstore flush, from the context of HStore, prior to HBASE-26067, would look like this:
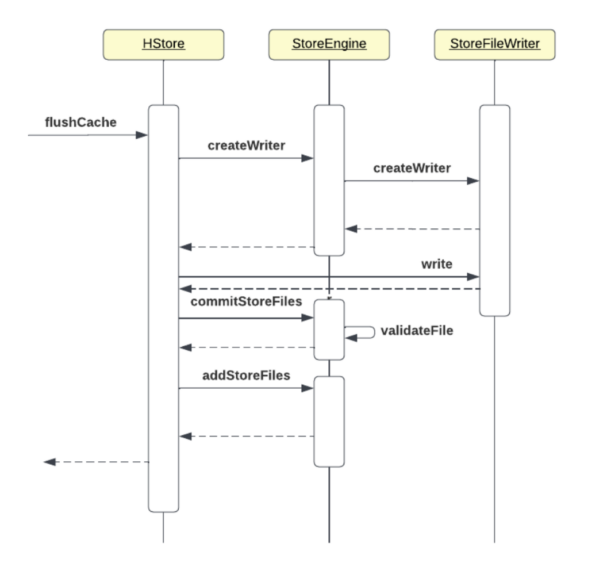
StoreFile Tracking adds its own layer into this architecture, encapsulating file creation and tracking logic that previously was coded in the store layer itself. To help visualize this, the equivalent diagrams after HBASE-26067 can be represented as:
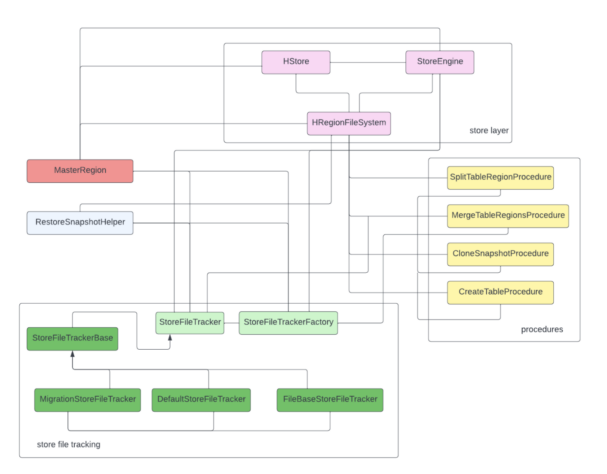
Memstore flush sequence with StoreFile Tracking:
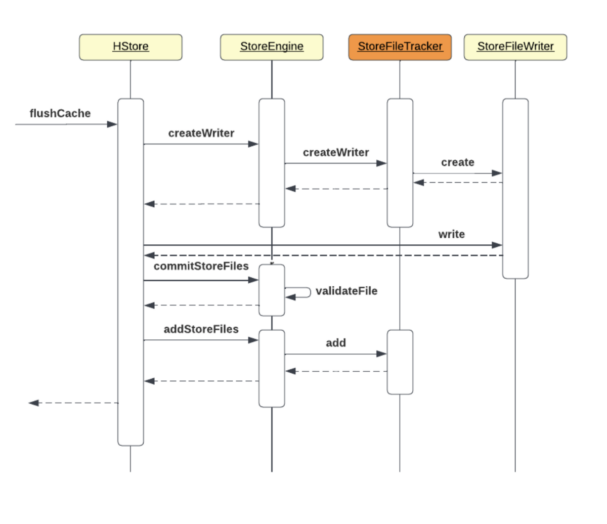
FILE-based StoreFile Tracking
The FILE-based tracker creates new files straight into the final store directory. It keeps a list of the committed valid files over a pair of meta files saved within the store directory, completely dismissing the need to use temporary files and rename operations. Starting from CDP 7.2.14 release, it is enabled by default for S3 based Cloudera Operational Database clusters, but from a pure HBase perspective FILE tracker can be configured at global or table level:
- To enable FILE tracker at global level, set the following property on hbase-site.xml:
<property><name>hbase.store.file-tracker.impl</name><value>FILE</value></property>
|
- To enable FILE tracker at table or column family level, just define the below property at create or alter time. This property can be defined at table or column family configuration:
{CONFIGURATION => {'hbase.store.file-tracker.impl' => 'FILE'}}
|
FILE tracker implementation details
While the store files creation and tracking logic is defined in the FileBaseStoreFileTracker class pictured above in the StoreFile Tracking layer, we mentioned that it has to persist the list of valid store files in some sort of internal meta files. Manipulation of these files is isolated in the StoreFileListFile class. StoreFileListFile keeps at most two files prefixed f1/f2, followed by a timestamp value from when the store was last open. These files are placed on a .filelist directory, which in turn is a subdirectory of the actual column family folder. The following is an example of a meta file for a FILE tracker enabled table called “tbl-sft”:
/data/default/tbl-sft/093fa06bf84b3b631007f951a14b8457/f/.filelist/f2.1655139542249
|
StoreFileListFile encodes the timestamp of file creation time together with the list of store files in the protobuf format, according to the following template:
message StoreFileEntry { required string name = 1; required uint64 size = 2; } message StoreFileList { required uint64 timestamp = 1; repeated StoreFileEntry store_file = 2; } |
It then calculates a CRC32 check sum of the protobuf encoded content, and saves both content and checksum to the meta file. The following is a sample of the meta file payload as seen in UTF:
^@^@^@U^H¥<91><87>ð<95>0^R% fad4ce7529b9491a8605d2e0579a3763^Pû%^R% 4f105d23ff5e440fa1a5ba7d4d8dbeec^Pû%û8â^R |
In this example, the meta file lists two store files. Note that it’s still possible to identify the store file names, pictured in red.
StoreFileListFile initialization
Whenever a region opens on a region server, its related HStore structures need to be initialized. When the FILE tracker is in use, StoreFileListFile undergoes some startup steps to load/create its metafiles and serve the view of valid files to the HStore. This process is enumerated as:
- Lists all meta files currently under .filelist dir
- Groups the found files by their timestamp suffix, sorting it by descending order
- Picks the pair with the latest timestamp and parses the file’s content
- Cleans all current files from .filelist dir
- Defines the current timestamp as the new suffix of the meta file’s name
- Checks which file in the chosen pair has the latest timestamp in its payload and returns this list to FileBasedStoreFileTracking
The following is a sequence diagram that highlights these steps:
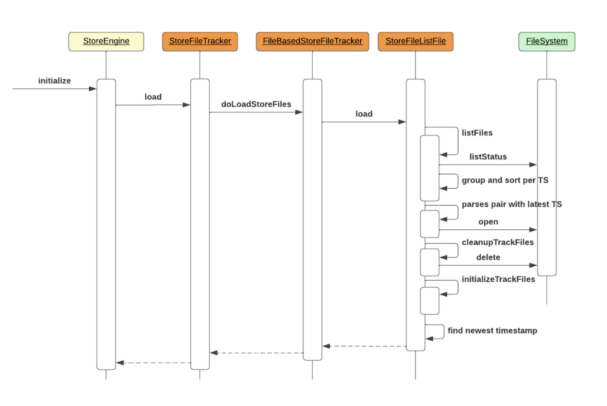
StoreFileListFile updates
Any operation that involves new store file creation causes HStore to trigger an update on StoreFileListFile, which in turn rotates the meta files prefix (either from f1 to f2, or f2 to f1), but keeps the same timestamp suffix. The new file now contains the up-to-date list of valid store files. Enumerating the sequence of actions for the StoreFileListFile update:
- Find the next prefix value to be used (f1 or f2)
- Create the file with the chosen prefix and same timestamp suffix
- Generate the protobuf content of the list of store files and the current timestamp
- Calculate the checksum of the content
- Save the content and the checksum to the new file
- Delete the obsolete file
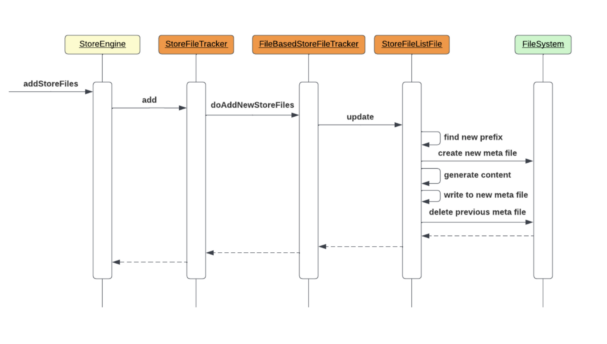
StoreFile Tracking operational utils
Snapshot cloning
In addition to the hbase.store.file-tracker.impl property that can be set at table or column family configuration on both create or alter time, an additional option is made available for clone_snapshot HBase shell command. This is critical when cloning snapshots taken for tables that did not have the FILE tracker configured, for example, while exporting snapshots from non-S3-based clusters with no FILE tracker, to S3-backed clusters that need the FILE tracker to work properly. The following is a sample command to clone a snapshot and properly set FILE tracker for the table:
clone_snapshot 'snapshotName', 'namespace:tableName', {CLONE_SFT=>'FILE'}
|
In this example, FILE tracker would already initialize StoreFileListFile with the related tracker meta files during the snapshot files loading time.
Store file tracking converter command
Two new HBase shell commands to change the store file tracking implementation for tables or column families are available, and can be used as an alternative to convert imported tables originally not configured with the FILE tracker:
- change_sft: Allows for changing store file tracking implementation of an individual table or column family:
hbase> change_sft 't1','FILE' hbase> change_sft 't2','cf1','FILE' |
- change_sft_all: Changes store file tracking implementation for all tables given a regex:
hbase> change_sft_all 't.*','FILE' hbase> change_sft_all 'ns:.*','FILE' hbase> change_sft_all 'ns:t.*','FILE' |
HBCK2 support
There is also a new HBCK2 command for fabricating FILE tracker meta files, in the exceptional event of meta files getting corrupted or going missing. This is the rebuildStoreFileListFiles command, and can rebuild meta files for the entire HBase directory tree at once, for individual tables, or for specific regions within a table. In its simple form, the command just builds and prints a report of affected files:
HBCK2 rebuildStoreFileListFiles
|
The above example builds a report for the whole directory tree. If the -f/–fix options are passed, the command effectively builds the meta files, assuming all files in the store directory are valid.
HBCK2 rebuildStoreFileListFiles -f my-sft-tbl |
Conclusion
StoreFile Tracking and its built-in FILE implementation that avoids internal file renames for managing store files enables HBase deployments over S3. It is completely integrated with Cloudera Operational Database in Public Cloud, and is enabled by default on every new cluster created with S3 as the persistence storage technology. The FILE tracker successfully handles store files without relying on temporary files or directories, dismissing the additional locking layer proposed by HBOSS. The FILE tracker and the additional tools that deal with snapshot, configuration, and supportability successfully migrate the data sets to S3, thereby empowering HBase applications to leverage the benefits offered by S3.
We’re extremely pleased to have unlocked HBase on S3 potential to our users. Try out HBase running on S3 in the Operational Database template in CDP today! To learn more about Apache HBase Distributed Data Store visit us here.
Editor's Choice

