

This blog post was published on Hortonworks.com before the merger with Cloudera. Some links, resources, or references may no longer be accurate.
This is the 5th blog of the Hadoop Blog series (part 1, part 2, part 3, part 4). In this blog, we will explore running Docker containers on YARN for faster time to market and faster time to insights for data intensive workloads at scale.
For over half a decade, the Apache Hadoop YARN community has been hard at work enabling the building blocks for running a diverse set of data intensive workloads at unprecedented scale.
The YARN community is constantly looking at ways to enable new use cases and improve existing capabilities. With the emergence of light-weight containerization technologies such as Docker, the benefit of bringing this capability to YARN was clear. The Apache Hadoop YARN community kicked off an effort long time ago to support orchestration of Docker containers on YARN, and we are excited about the progress that has been made since working towards that goal.
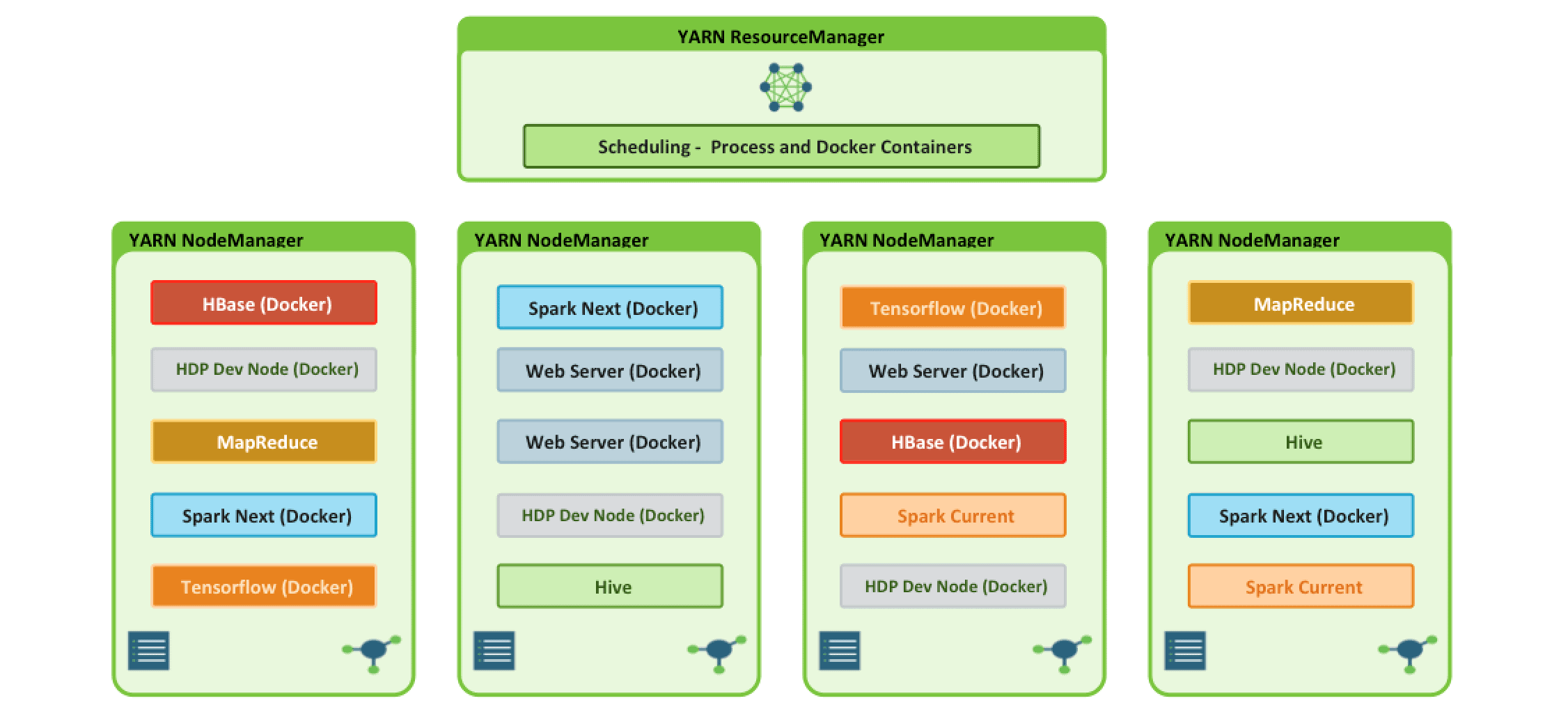
Apache Hadoop YARN 3.x laid the foundation for enabling workloads beyond the traditional short lived interactive and batch processing frameworks. With the addition of the YARN Services framework and Docker containerization, it is now possible to run both existing Hadoop frameworks, such as Hive, and new containerized workloads on the same underlying infrastructure! With Apache Hadoop 3.1, these capabilities have been improved to enable advanced use cases such as Tensorflow and HBase.
Motivation
The benefits gained by the addition of containerization are huge. The rich scheduling and multi tenancy features that are already present in YARN combined with containerization, open up many more use cases.
Docker makes it easy for users to bundle libraries and dependencies along with their application. This translates to reducing the time to deployment, which in turn leads to a faster time to insights. With Docker’s packaging and isolation features, it is even possible to run two different versions of the same framework on the same cluster. Have you ever been interested in an bleeding edge feature in the latest version of Apache Spark, but are unsure if it will meet your needs? Now you have the ability to try out that feature by leveraging YARN’s containerization support, without Spark version upgrades or impact to the current applications. (Side note: we will be doing a post on containerized Spark on YARN very soon!)
Consider the benefits of the use cases that YARN’s containerization support enables, such as:
- Orchestration of stateless distributed applications.
- Packaging libraries for a Spark application, eliminating the need for operations to deploy that library cluster wide.
- Provisioning per tenant development HDP clusters for prototyping.
- Running tests on multiple Operating Systems without the need to change the underlying host Operating System.
- Upgrading the underlying host Operating System, while keeping the user’s execution environment unchanged.
- ….
The list goes on…

Architecture
The YARN containerization feature provides multiple entry points for accessing these capabilities to allow for different types of users to leverage the system. This approach led to two main additions to YARN; the core Docker runtime support and YARN Services.
YARN Services is a higher level abstraction that provides an easy way to define the layout of components within a service and the service’s execution parameters, such as retry policies and configuration, in a single service specification file. When the specification file is submitted to the cluster, the lower level core Docker runtime support is used to satisfy that request and start the requested Docker containers on the YARN NodeManager systems.
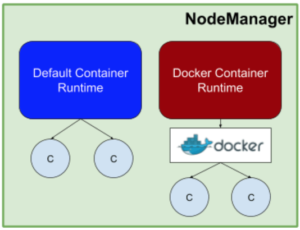
The core Docker runtime support is configured using environment variables at application submission time, which means existing Hadoop applications will not require changes to leverage containerization support.
Trying It Out
The example will focus on leveraging the core Docker runtime support added to YARN. Future blog posts will outline a similar example leveraging the YARN Services framework.
Prerequisites
Docker needs to be installed on all YARN NodeManager hosts in the cluster.
Setting up YARN ResourceManager & Scheduler
There’s nothing to do here!
Dockerized apps can take full advantage of all of the RM & scheduling aspects including Queues, ACLs, fine-grained sharing policies, powerful placement policies etc.
This is where the real power of using dockerized apps side-by-side with the rest of the applications comes in – being able to rationalize resource management & scheduling exactly the same way irrespective of the type of containerization.
Setting up YARN Containerization on the NodeManager
In the section, we describe how the YARN NodeManager can be configured to use docker containers.
There are two configuration files that need to be modified to enable YARN’s containerization features; yarn-site.xml and container-executor.cfg. The necessary changes are outlined below. Restart all YARN services after making the configuration changes.
The following configuration runs LinuxContainerExecutor in an insecure mode. With this configuration, the processes in the Docker container will run as the nobody user. This is necessary to avoid modifications to the images to include the submitting user’s account and to limit access to the host resources. Insecure mode is intended only for testing or in high controlled single user environments. Kerberos configurations are recommended for production.
In some cases, the same or very similarly named setting appears in both yarn-site.xml and container-executor.cfg. This is done as a “defense in depth” measure to protect the system in the case of unauthorized access to the daemon users. The configuration values used in these two files need to match in these cases (for instance, yarn.nodemanager.runtime.linux.docker.capabilities in yarn-site.xml and docker.allowed.capabilities in container-executor.cfg).
Setting Up YARN NodeManager – YARN-SITE.XML
Basics
| yarn.nodemanager.container-executor.class | Container executors encapsulate the logic for launching and interacting with containers on a specific Operating System(s). |
| yarn.nodemanager.runtime.linux.allowed-runtimes | Comma separated list of runtimes that are allowed when using LinuxContainerExecutor. |
Security
| yarn.nodemanager.runtime.linux.docker.capabilities | This configuration setting determines the capabilities assigned to docker containers when they are launched. While these may not be case-sensitive from a docker perspective, it is best to keep these uppercase. To run without any capabilities, set this value to “none” or “NONE”. Admins must update this list based on the security requirements of their workloads. |
| yarn.nodemanager.runtime.linux.docker.privileged-containers.allowed | This configuration setting determines if privileged docker containers are allowed on this cluster. The submitting user must be part of the privileged container acl and must be part of the docker group or have sudo access to the docker command to be able to use a privileged container. Use with extreme care. |
| yarn.nodemanager.runtime.linux.docker.privileged-containers.acl | This configuration setting determines the submitting users who are allowed to run privileged docker containers on this cluster. The submitting user must also be part of the docker group or have sudo access to the docker command. No users are allowed by default. Use with extreme care. |
| yarn.nodemanager.linux-container-executor.nonsecure-mode.local-user | The user that containers will run as in nonsecure mode. |
Networking
| yarn.nodemanager.runtime.linux.docker.allowed-container-networks | The set of Docker networks allowed when launching containers. |
| yarn.nodemanager.runtime.linux.docker.default-container-network | The Docker network used when launching containers when no network is specified in the request. This network must be one of the (configurable) set of allowed container networks. The default is host, which may not be appropriate for multiple containers on a single node when they use the same port, use bridge in that case. See docker networking documentation for more. |
Example yarn-site.xml
<property> <name>yarn.nodemanager.container-executor.class</name> <value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutor</value> </property> <property> <name>yarn.nodemanager.linux-container-executor.nonsecure-mode.local-user</name> <value>nobody</value> </property> <property> <name>yarn.nodemanager.runtime.linux.allowed-runtimes</name> <value>default,docker</value> </property> <property> <name>yarn.nodemanager.runtime.linux.docker.capabilities</name> <value>CHOWN,DAC_OVERRIDE,FSETID,FOWNER,MKNOD,NET_RAW,SETGID,SETUID,SETFCAP, SETPCAP,NET_BIND_SERVICE,SYS_CHROOT,KILL,AUDIT_WRITE</value> </property> <property> <name>yarn.nodemanager.runtime.linux.docker.privileged-containers.allowed</name> <value>false</value> </property> <property> <name>yarn.nodemanager.runtime.linux.docker.privileged-containers.acl</name> <value></value> </property> <property> <name>yarn.nodemanager.runtime.linux.docker.allowed-container-networks</name> <value>host,bridge</value> </property> <property> <name>yarn.nodemanager.runtime.linux.docker.default-container-network</name> <value>host</value> </property> |
Setting up YARN Container-Executor binary (Container-executor.cfg)
In the section, we describe how the YARN ContainerExecutor binary should be configured in order to be able to use docker containers.
Basics
| module.enabled | Must be “true” or “false” to enable or disable launching Docker containers respectively. Default value is 0. |
| docker.binary | The binary used to launch Docker containers. /usr/bin/docker by default. |
| yarn.nodemanager.linux-container-executor.group | The Unix group of the NodeManager. It must match the yarn.nodemanager.linux-container-executor.group in the yarn-site.xml file. |
| min.user.id | The minimum UID that is allowed to launch applications. When leveraging the nobody user on CentOS this needs to be set below 99, as that is the default UID of the nobody user, which is the default run-as user in insecure mode with LinuxContainerExecutor. |
Security
| banned.users | A comma-separated list of usernames who should not be allowed to launch applications. The default setting is: yarn, mapred, hdfs, and bin. |
| docker.allowed.capabilities | Comma separated capabilities that containers are allowed to use. By default no capabilities are allowed to be used. Admins must update this list based on the security requirements of their workloads. |
| docker.privileged-containers.enabled | Set to “true” or “false” to enable or disable launching privileged containers. Default value is “false”. The submitting user must be defined in the privileged container acl setting and must be part of the docker group or have sudo access to the docker command to be able to use a privileged container. Use with extreme care. |
| docker.trusted.registries | Comma separated list of trusted docker registries for running trusted privileged docker containers. By default, no registries are defined. If the image used for the application does not appear in this list, all capabilities, mounts, and privileges will be removed from the container. |
Storage & Volumes
| docker.allowed.devices | Comma separated devices that containers are allowed to mount. By default no devices are allowed to be added. |
| docker.allowed.ro-mounts | Comma separated directories that containers are allowed to mount in read-only mode. By default, no directories are allowed to be mounted. |
| docker.allowed.rw-mounts | Comma separated directories that containers are allowed to mount in read-write mode. By default, no directories are allowed to be mounted. |
| docker.allowed.volume-drivers | Comma separated volume drivers that containers are allowed to use. |
Networking
| docker.allowed.networks | Comma separated networks that containers are allowed to use. If no network is specified when launching the container, the default Docker network will be used. |
Example container-executor.cfg
yarn.nodemanager.local-dirs=<yarn.nodemanager.local-dirs from yarn-site.xml> yarn.nodemanager.log-dirs=<yarn.nodemanager.log-dirs from yarn-site.xml> yarn.nodemanager.linux-container-executor.group=hadoop banned.users=hdfs,yarn,mapred,bin min.user.id=50 [docker] module.enabled=true docker.binary=/usr/bin/docker docker.allowed.capabilities=CHOWN,DAC_OVERRIDE,FSETID,FOWNER,MKNOD,NET_RAW, SETGID,SETUID,SETFCAP,SETPCAP,NET_BIND_SERVICE, SYS_CHROOT,KILL,AUDIT_WRITE,DAC_READ_SEARCH, SYS_PTRACE,SYS_ADMIN docker.allowed.devices= docker.allowed.networks=bridge,host,none docker.allowed.ro-mounts=/sys/fs/cgroup, <yarn.nodemanager.local-dirs from yarn-site.xml> docker.allowed.rw-mounts=<yarn.nodemanager.local-dirs from yarn-site.xml>, <yarn.nodemanager.log-dirs from yarn-site.xml> docker.privileged-containers.enabled=false docker.trusted.registries=local,centos,hortonworks docker.allowed.volume-drivers= |
Running containerized Distributed Shell
Execute the following from a YARN client node.
#!/bin/bash export DSHELL_JAR="./yarn/hadoop-yarn-applications-distributedshell-*.jar" export RUNTIME="docker" export DOCKER_IMAGE="library/centos:latest" export DSHELL_CMD="sleep 120" export NUM_OF_CONTAINERS="1" yarn jar $DSHELL_JAR \ -shell_env YARN_CONTAINER_RUNTIME_TYPE="$RUNTIME" \ -shell_env YARN_CONTAINER_RUNTIME_DOCKER_IMAGE="$DOCKER_IMAGE" \ -shell_command $DSHELL_CMD -jar $DSHELL_JAR -num_containers $NUM_OF_CONTAINERS |
Conclusion
Apache Hadoop YARN containerization support has enabled the building blocks that will allow users get more out of their investment in YARN.
Stay tuned for more on how YARN Services further enhances the user experience for running services on YARN and how these features can be used to run advanced applications, such as Spark and Tensorflow.
Learn More about Hadoop 3:
- First-Class Support for Long Running Services on Apache Hadoop YARN
- How Apache Hadoop 3 Adds Value Over Apache Hadoop 2
- Apache Hadoop 3.1.0 released. And a look back!
- Apache Hadoop 3.1 – A Giant Leap for Big Data
Editor's Choice


some small typo on the script.
-shell_command $DSHELL_CMD
-jar $DSHELL_JAR
-num_containers $NUM_OF_CONTAINERS