


Analytical SQL engines like Apache Impala are great for large table scans and aggregation query workloads. Individual tables in the big data ecosystem can reach petabytes in size, so achieving fast query response times requires intelligent filtering of table data based on conditions in the WHERE or HAVING clauses. Typically, you partition large tables using one or more columns that can effectively filter the range of data. For example, date columns are often chosen as partition keys so partitions of data can be eliminated when a date range is specified in SQL queries. In addition to filtering at the partition level, the Parquet file format supports filtering at the file level based on the minimum and maximum values of each column in the file. These minimum/maximum column values are stored in the footer of the file. If the range between the minimum and maximum value in the file does not overlap with the range of data specified by the query, then the system skips the entire file during scans. In the past, filtering file-level minimum/maximum statistics has been coarse grained: if an entire file could not be skipped, the entire file had to be read. However, with the addition of Parquet Page Indexes to the Parquet format in CDP 1.0, scanners can further reduce the amount of data being read from disk, offering a significant performance boost for SELECT queries in Impala.
About Parquet
Apache Parquet is a binary file format for storing data. Most often it is used for storing table data. Parquet organizes the data into row groups, and each row group stores a set of rows. Internally a row group is column-oriented. This means that the row group is divided into entities that are called “column chunks.” They are called column chunks because a row group stores only a fragment of a column. Column-oriented means that the values belonging to the first column chunk are stored next to each other, then the values of the second column chunk, and so on. In this sense, to be column-oriented means the values are organized by column chunks, and the column chunks contain the data pages which ultimately store the data. At the end of the file, there is the Parquet footer that stores the metadata.
The whole Parquet file looks like the following diagram (Figure 1). In this diagram, the boxes symbolize the column values and boxes that have the same color belong to the same column chunk:
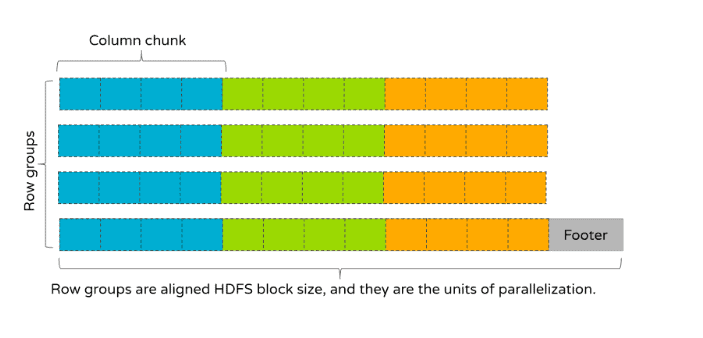
Figure 1
Minimum/Maximum Filtering
Since Parquet 2.0, files can contain row group level statistics that contain the minimum and maximum values for each column chunk. These statistics can be used to eliminate row groups during scanning as illustrated in Figure 2 below:
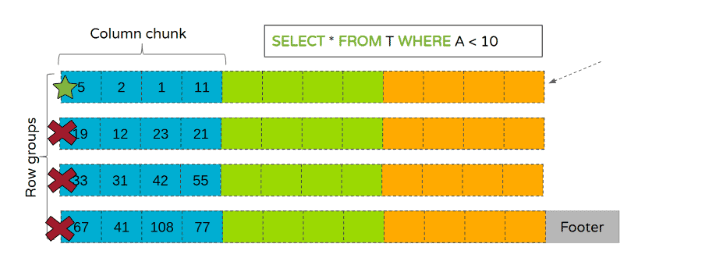
Figure 2
In the example shown in the above diagram, only the first row group meets the search criteria because the range [1, 11] overlaps with A < 10. This results in the first row group being read while the other row groups are skipped entirely.
Page Index
The Page Index feature works in a similar fashion to row group-level min/max stats, but at a finer granularity. As the name suggests, the Page Index stores information about the pages, such as where they are located in the file, which rows they contain, and most importantly, the min/max statistics about the stored values. The Page Index itself is stored in the footer of a Parquet file. Queries that have a filter predicate read the Page Index first and determine which pages to perform an action on, such as read, decompress, decode, and so on. Scans without filter predicates do not need to read the Page Index, which results in no runtime overhead.
The following example shows how a Parquet page filtering algorithm can use page-level statistics to effectively filter data for queries with one or more filter predicates.
Consider the following table:
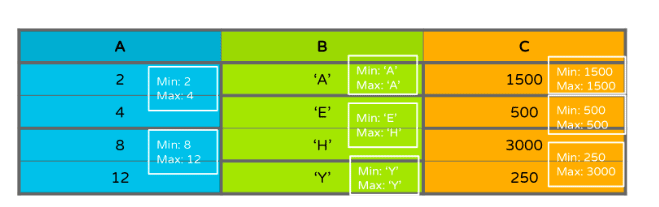
Figure 3
In Figure 3, the strong borders symbolize page boundaries. The white boxes show the stored min/max statistics for each page.
If there is a query with a predicate in the WHERE clause, only a subset of the pages need to be scanned as shown in Figure 4:
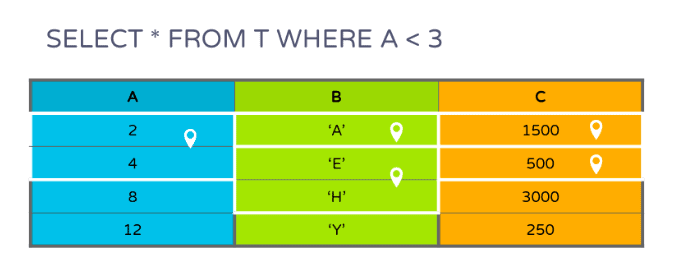
Figure 4
There is a predicate on the first column only, but based on the matching rows, pages can be filtered from the other columns as well.
If there are predicates on multiple columns like A and B, only pages from C that contain the common subset of rows of the filtered pages of A and B need to be scanned as shown in Figure 5:
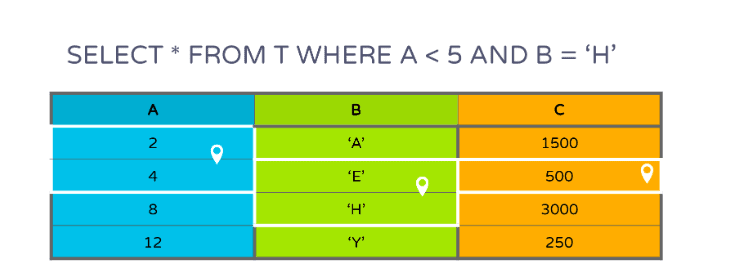
Figure 5
There is a predicate on the first column only, but based on the matching rows, pages can be filtered from the other columns as well.
If there are predicates on multiple columns like A and B, only pages from C that contain the common subset of rows of the filtered pages of A and B need to be scanned as shown in Figure 5:
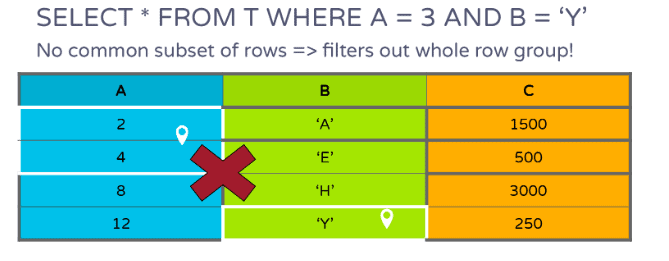
Figure 6
In Figure 7, the whole row group can be filtered out if there is a gap in the data:
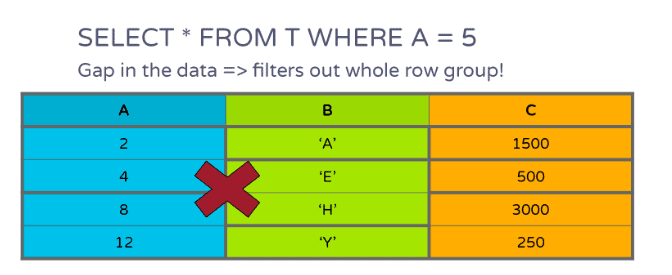
Figure 7
Using page indexes, you can filter out the entire row groups that could not be filtered out with row group-level statistics.
The Page Index feature works best on sorted data because pages of sorted data usually store disjunct ranges, making filtering very efficient. This feature also works well when you are looking for outlier values because those values are likely to be outside of the minimum/maximum range of most pages. Page Index can be complementary to partitioning. For example, you can partition your data by a set of columns, and then use SORT BY to sort your data by another column that you use in the filtering criteria.
Testing with Parquet-MR
Using Parquet-MR, we ran a number of performance tests on randomly generated data. The main purpose was to measure the potential performance gain for SELECT queries and also to prove that the feature does not cause performance regressions.
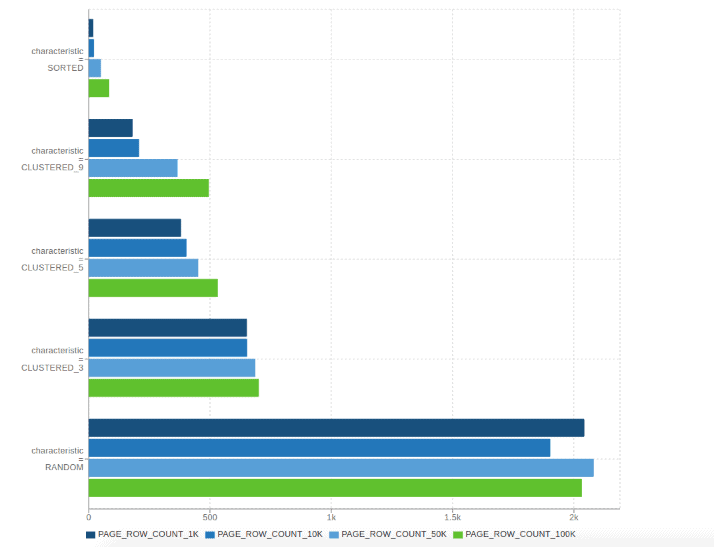
The following chart shows how Parquet-MR performs on datasets from the perspective of five different characteristics with simple SELECT queries like column = x. The following datasets were used:
- SORTED: We generated random data and then sorted the whole data.
- CLUSTERED_n: We generated random data, split it into n buckets and then sorted each bucket separately. This simulates partially sorted data that occurs in real-life workloads. For example, data sets comprised of timestamps of events.
- RANDOM: We generated random data and did not apply any sorting.
The sorted datasets work best for page indexes. Even partially sorted data performs much better than purely random data. These examples also show that there is no significant performance penalty of using page indexes on pure random data.
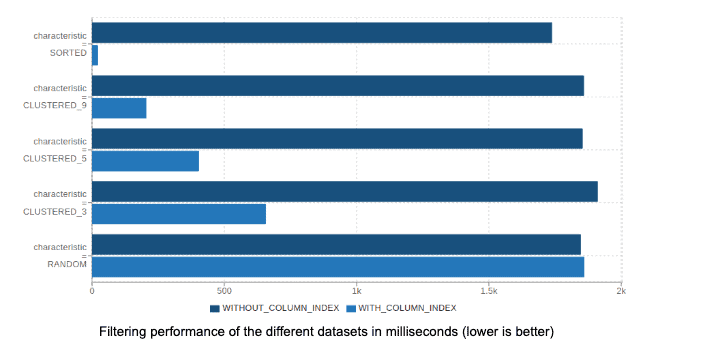
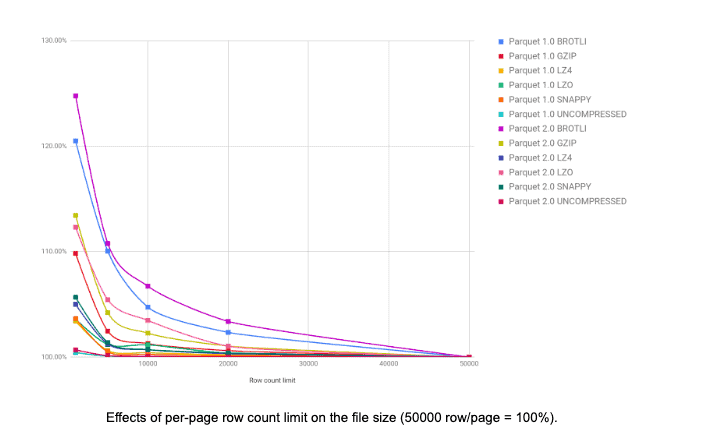
These examples also show that the more pages we have in a column chunk the better from the “page indexes” perspective. Before this feature was developed, Parquet-MR had only one property that could control the number of pages in a column chunk: parquet.page.size. The problem with using that property is that some encodings can perform “too well” on some data. For example, using RLE encoding on highly repetitive data. In these cases, even using a small page size results in all the values for a column chunk fitting in only one page. Then significant filtering cannot be performed based on page indexes.
To solve this problem, we introduced the new property parquet.page.row.count.limit. This property controls the number of rows for an actual page. Based on the following charts, 20,000 has been chosen as the default value which seems to be a good midpoint between good performance and a significant number of pages. Too many pages increases the file size significantly.
Filtering performance of the different page sizing in milliseconds. Note that lower is better.
Testing with Impala
We used the LINEITEM table with a scale factor of 50 from the TPC-H benchmark suite and wrote several SELECT queries against it. The table was unpartitioned and sorted by the L_ORDERKEY column. All queries were executed on a single thread to focus the measurements on the speedup of scans.
The following queries were used in the test:
- Q1: select * from lineitem where l_suppkey = 10
- Q2: select * from lineitem where l_suppkey > 499995;
- Q3: select * from lineitem where l_orderkey = 1
- Q4: select * from lineitem where l_orderkey = 73944871
- Q5: select * from lineitem where l_orderkey < 1000;
- Q6: select * from lineitem where l_extendedprice < 910
- Q7: select * from lineitem where l_extendedprice = 902.00
- Q8: select * from lineitem where l_extendedprice > 104946.00
- Q9: select * from lineitem where l_receiptdate = ‘1998-12-30’
- Q10: select * from lineitem where l_commitdate = ‘1992-01-31’ and l_orderkey > 210000000
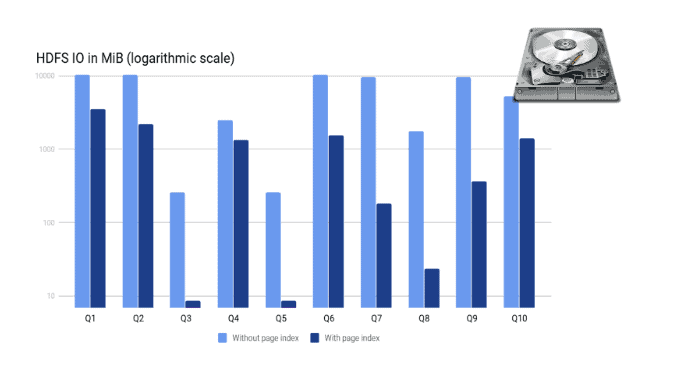
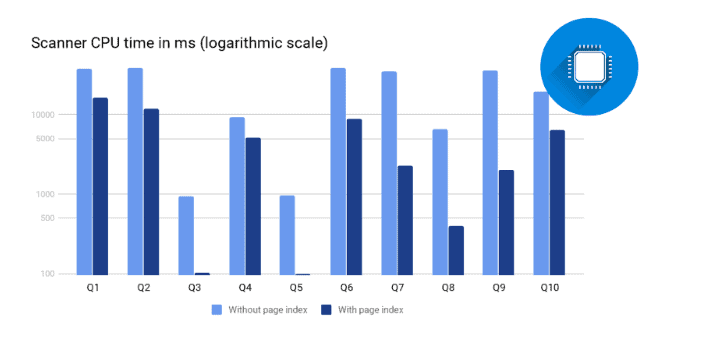
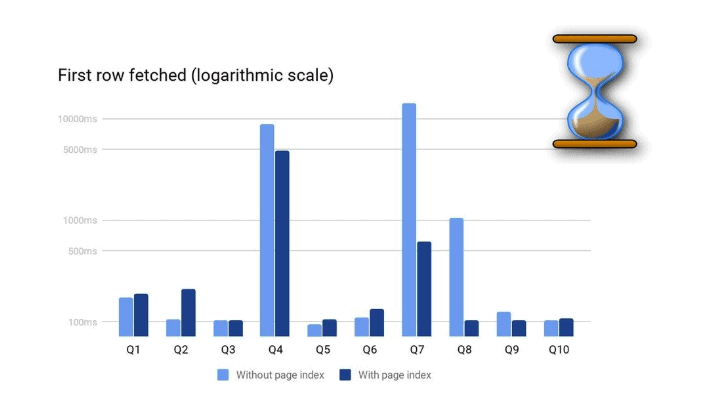
As shown above, the scan-time is proportional to the data read. The amount of data read depends on the actual filter in the query and the selectivity of it.
Summary
In this article, the Parquet Page Index feature is introduced and demonstrated to show how it can improve query performance. It can significantly decrease scanning time for some workloads and greatly reduce the query response time without any modification to the queries involved. The feature is released in Parquet-MR 1.11.0 and Impala 3.3.0 and is available in CDP since version 1.0. Page Index reading and writing are enabled by default for both Impala and Parquet-MR. However, keep in mind that for best results you should sort/cluster your data.
Editor's Choice


Very cool optimization! Does this add any overhead to write operations as the page index would presumably have to be updated before the operation completes?
Also quick comment that the introductory text for Figure 6 in the Page Index section seems to be incorrectly referring to Figure 5.
In Impala it only means that we need to keep track the min/max values for each Parquet page during writing. Unfortunately I don’t have the exact numbers but the time and memory overhead should be negligible (long strings are truncated to 64 bytes).